wikisearch
1.0.0
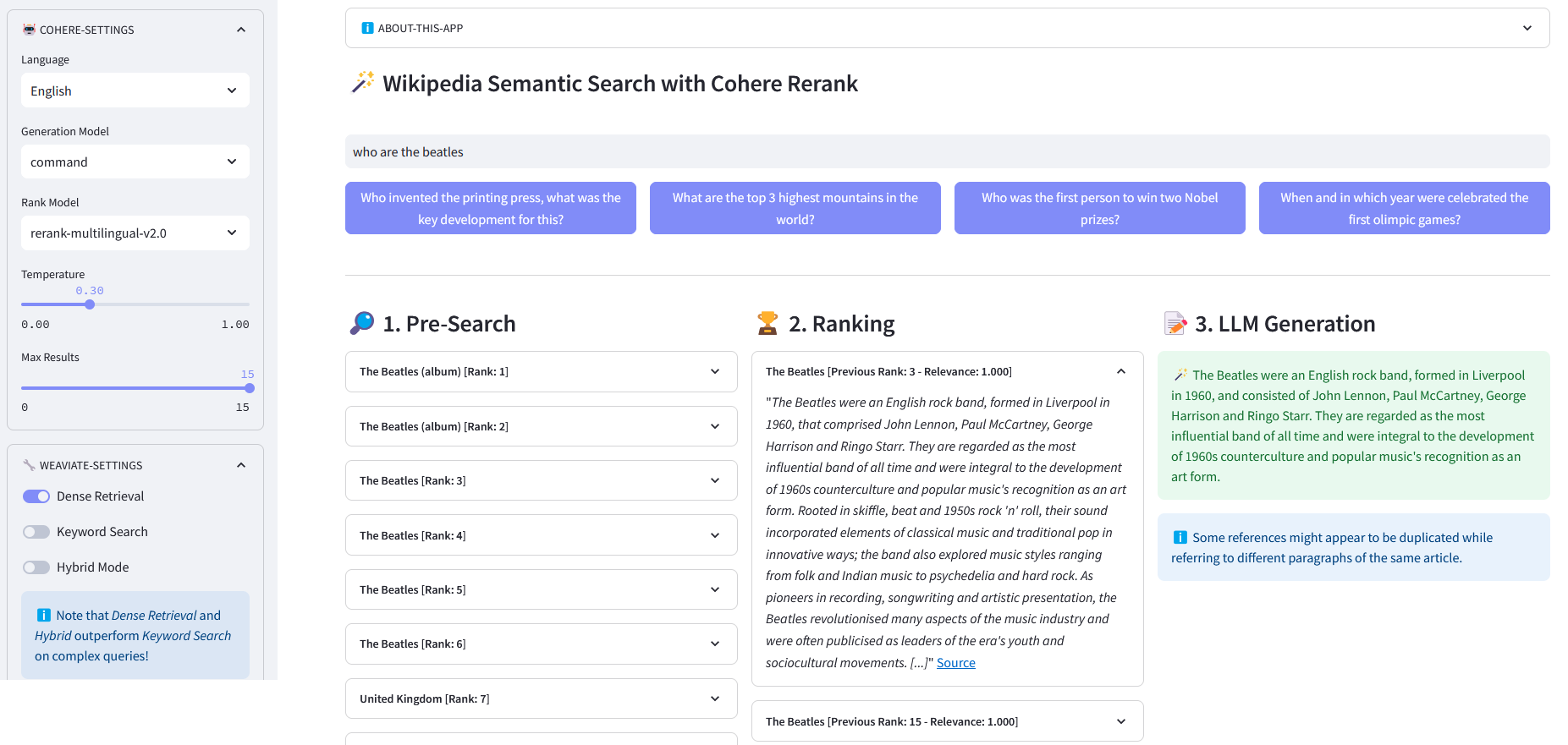
Приложение Streamlit для многоязычного семантического поиска по более чем 10 миллионам документов Википедии, векторизованных с помощью Weaviate. Эта реализация основана на блоге Cohere «Использование LLM для поиска» и соответствующем блокноте. Это позволяет сравнивать производительность поиска по ключевым словам , плотного поиска и гибридного поиска для запроса набора данных Википедии. Кроме того, он демонстрирует использование Cohere Rerank для повышения точности результатов и Cohere Generate для предоставления ответа на основе указанных ранжированных результатов.
Семантический поиск относится к поисковым алгоритмам, которые учитывают намерение и контекстное значение поисковых фраз при генерировании результатов, а не сосредотачиваются исключительно на сопоставлении ключевых слов. Он обеспечивает более точные и релевантные результаты за счет понимания семантики или значения запроса.
Встраивание — это вектор (список) чисел с плавающей запятой, представляющий такие данные, как слова, предложения, документы, изображения или аудио. Указанное числовое представление отражает контекст, иерархию и сходство данных. Их можно использовать для последующих задач, таких как классификация, кластеризация, обнаружение выбросов и семантический поиск.
Векторные базы данных, такие как Weaviate, специально созданы для оптимизации возможностей хранения и запросов для встраивания. На практике векторная база данных использует комбинацию различных алгоритмов, каждый из которых участвует в поиске приближенного ближайшего соседа (ANN). Эти алгоритмы оптимизируют поиск посредством хеширования, квантования или поиска на основе графов.
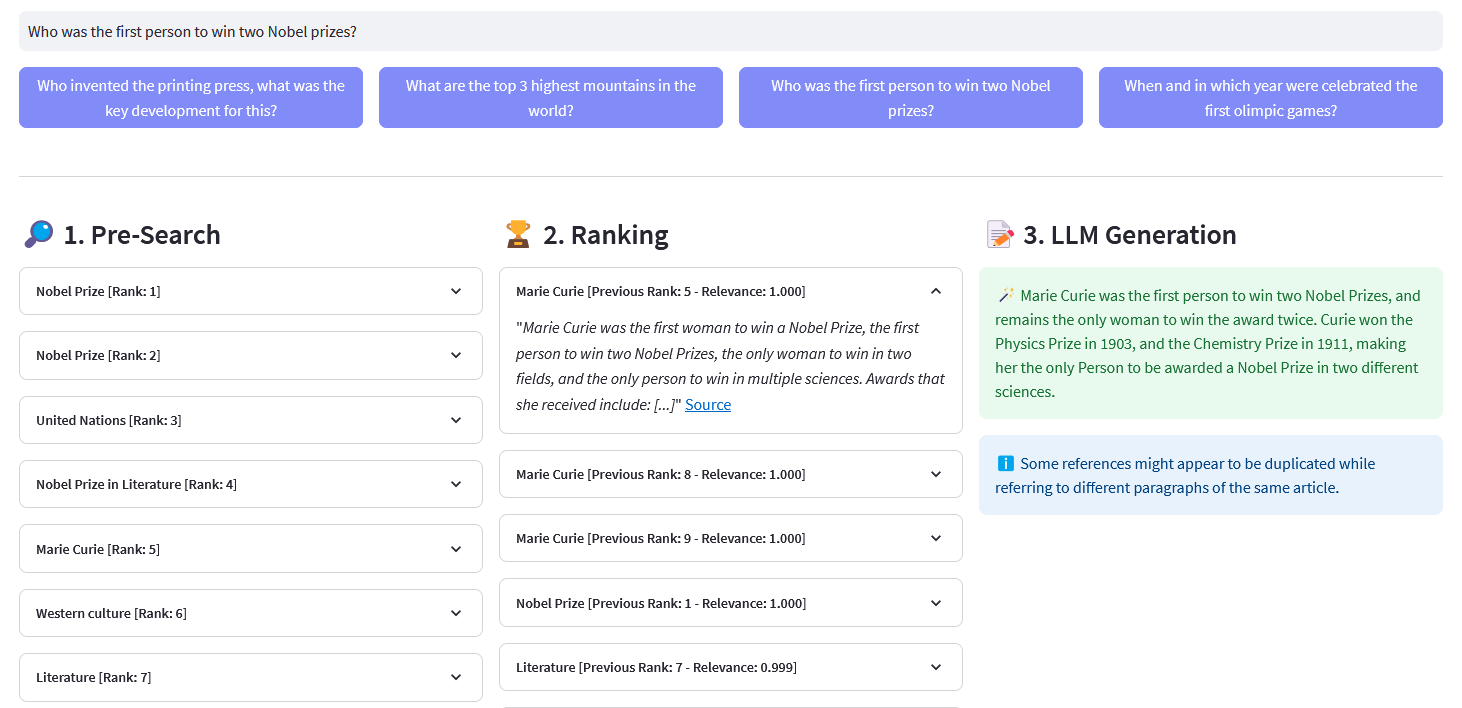
Предварительный поиск : предварительный поиск во встраиваниях Википедии с сопоставлением ключевых слов , плотным поиском или гибридным поиском :
Сопоставление ключевых слов: он ищет объекты, которые содержат в своих свойствах условия поиска. Результаты оцениваются в соответствии с функцией BM25F:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" Выполняет ключевое слово поиск (разреженный поиск) в статьях Википедии с использованием вложений, хранящихся в Weaviate. Параметры: - query (str): поисковый запрос - lang (str,. необязательно): язык статей. По умолчанию — «en». — top_n (int, необязательно): количество возвращаемых лучших результатов. По умолчанию — 10. Возвращает: — список: список лучших статей на основе оценки BM25F. ""logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Статьи", self.WIKIPEDIA_PROPERTIES)
.with_bm25(запрос=запрос)
.with_where(где_фильтр)
.with_limit(top_n)
.делать()
)возврат ответа["данные"]["Получить"]["Статьи"]Плотный поиск: найдите объекты, наиболее похожие на необработанный (невекторизованный) текст:
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" Выполняет семантику поиск (плотный поиск) в статьях Википедии с использованием вложений, хранящихся в Weaviate. Параметры: - query (str): поисковый запрос - lang (str,. необязательно): язык статей. По умолчанию — «en». — top_n (int, необязательно): количество возвращаемых лучших результатов. По умолчанию — 10. Возвращает: — список: список лучших статей на основе семантического сходства. ""logging.info("with_neartext()")nearText = {"concepts": [запрос]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_near_text(околотекста)
.with_where(где_фильтр)
.with_limit(top_n)
.делать()
)возврат ответа['данные']['Получить']['Статьи']Гибридный поиск: выдает результаты на основе взвешенной комбинации результатов поиска по ключевому слову (bm25) и векторного поиска.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" Выполняет гибрид поиск в статьях Википедии с использованием встроенных элементов, хранящихся в Weaviate. Параметры: - query (str): поисковый запрос. - lang (str, необязательно): язык статей по умолчанию. 'en'. - top_n (int, необязательно): количество возвращаемых лучших результатов. По умолчанию – 10. Возвращает: - list: список лучших статей на основе гибридной оценки. )where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(запрос=запрос)
.with_where(где_фильтр)
.with_limit(top_n)
.делать()
)возврат ответа["данные"]["Получить"]["Статьи"]ReRank : Cohere Rerank реорганизует предварительный поиск, присваивая оценку релевантности каждому результату предварительного поиска по запросу пользователя. По сравнению с семантическим поиском на основе внедрения он дает лучшие результаты поиска, особенно для сложных и специфичных для предметной области запросов.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self, query, document, top_n=10, model='rerank-english-v2.0') -> dict:""" Изменяет ранжирование списка ответов с помощью API переранжирования Cohere. Параметры: - query (str): поисковый запрос. - document (list): список документов, которые будут reranked. - top_n (int, необязательно): количество возвращаемых результатов с самым высоким рейтингом. По умолчанию – 10. - model: модель, используемая для изменения рейтинга. По умолчанию – "rerank-english-v2.0". Изменено ранжирование документов из API Cohere.
Источник: Когере
Генерация ответов : Cohere Generate формирует ответ на основе ранжированных результатов.
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, temp=0.2, model="command", lang="english") -> list:prompt = f""" Используйте информацию, представленную ниже, чтобы ответить на вопросы в конце. / Включите некоторые любопытные или важные факты, извлеченные из контекста. / Сгенерируйте ответ на языке запроса. Если вы не можете определить язык запроса, используя {lang}. / Если ответ на вопрос не содержится в предоставленной информации, сгенерировать «Ответ не в контексте». --- Информация о контексте: {context} --- Вопрос. : {query} """ return self.cohere.generate(prompt=prompt,num_generations=1,max_tokens=1000,temperature=temperature,model=model,
)Клонируем репозиторий:
[email protected]:dcarpintero/wikisearch.git
Создайте и активируйте виртуальную среду:
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
Установите зависимости:
pip install -r requirements.txt
Запустить веб-приложение
streamlit run ./app.py
Демо-веб-приложение развернуто в Streamlit Cloud и доступно по адресу https://wikisearch.streamlit.app/.
Совместное изменение ранга
Стримлитовое облако
Архивы встраивания: миллионы вложений статей Википедии на многих языках
Использование LLM для поиска с плотным поиском и изменением рейтинга
Векторные базы данных
Векторный поиск
Weaviate BM25 Поиск
Гибридный поиск Weaviate


