ssebowa
1.0.0
Ssebowa — это библиотека Python с открытым исходным кодом, которая предоставляет генеративные модели искусственного интеллекта, в том числе:
ssebowa-llm: Большая языковая модель (LLM) для генерации текста,ssebowa-vllm: модель визуального языка (VLLM) для визуального понимания,ssebowa-imagen: генерация изображения и настраиваемая модель точной настройки,Ssebowa-vigen: Модель генерации видео.С Ssebowa вы можете легко генерировать текст, переводить языки, писать различные виды творческого контента, создавать персонализированные изображения и информативно отвечать на ваши вопросы.
Более подробную информацию об использовании см. в технической документации Ssebowa.
Перед запуском сценария убедитесь, что установлены необходимые библиотеки. Вы можете сделать это, выполнив следующие команды:
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .Затем установите Ssebowa
pip install ssebowaЕсли вы выполняете эти команды в блокноте Colab или Jupyter, используйте это:
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowaТеперь вы можете получить доступ к различным моделям, импортировав их из библиотеки:
Ssebowa-Imagen — это модель синтеза изображений с открытым исходным кодом, которая использует комбинацию diffusion modeling и generative adversarial networks (GANs) для создания высококачественных изображений из text descriptions , а также позволяет превратить несколько ваших фотографий в custom model , способную генерировать потрясающие изображения chosen subject . Он использует 100 billion dataset изображений и текстовых описаний, что позволяет ему точно улавливать нюансы изображений реального мира и эффективно переводить текстовые описания в убедительные визуальные представления.
10-20 high-quality индивидуальных фотографий (jpg or png) таких как ваша фотография, фотография друга, товар или домашнее животное и т. д., и поместите их в определенный каталог.16GB or more . (Если вы выполняете тонкую настройку SDXL, вам понадобится 24 ГБ видеопамяти.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()Лайк давайте сгенерируем "Кот сидит на книжной полке"
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebowa-vllm — это визуальная модель большого языка (VLLM) с открытым исходным кодом, разработанная Ssebowa AI. Это мощный инструмент, который можно использовать для понимания изображений. Ssebowa-vllm имеет 11 миллиардов визуальных параметров и 7 миллиардов языковых параметров, поддерживая распознавание изображений с разрешением 1120*1120.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)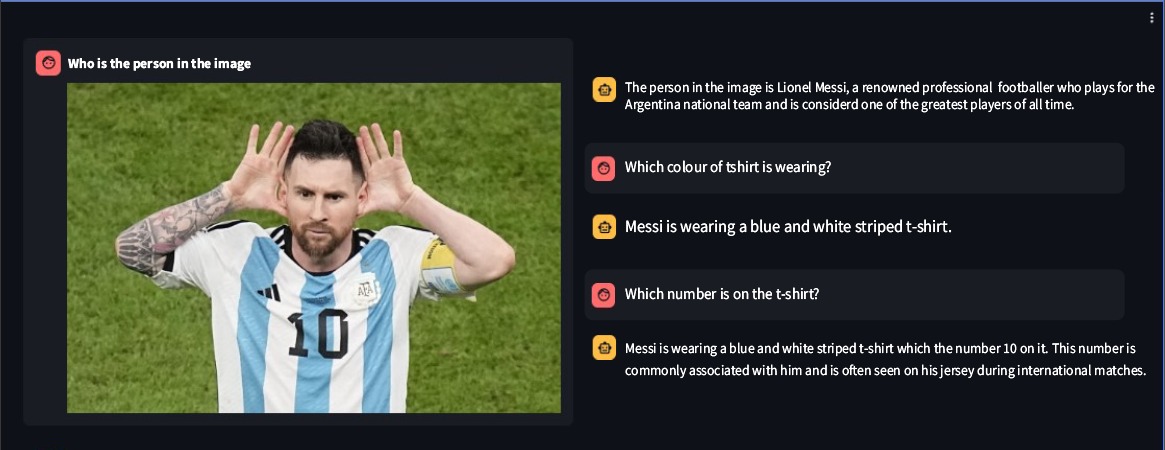
Ссебова открыта для предложений! Рекомендации в разработке..
Ssebowa выпускается под лицензией Apache License 2.0.
Если у вас есть какие-либо вопросы или предложения, пожалуйста, откройте вопрос на GitHub или свяжитесь с нами по адресу [email protected].


