xTuring
0.1.8


xTuring обеспечивает быструю, эффективную и простую настройку LLM с открытым исходным кодом, таких как Mistral, LLaMA, GPT-J и других. Предоставляя простой в использовании интерфейс для точной настройки LLM в соответствии с вашими собственными данными и приложением, xTuring упрощает создание, изменение и управление LLM. Весь процесс можно выполнить на вашем компьютере или в частном облаке, обеспечивая конфиденциальность и безопасность данных.
С xTuring вы можете,
pip install xturing from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the dataset
instruction_dataset = InstructionDataset ( "./examples/models/llama/alpaca_data" )
# Initialize the model
model = BaseModel . create ( "llama_lora" )
# Finetune the model
model . finetune ( dataset = instruction_dataset )
# Perform inference
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( "Generated output by the model: {}" . format ( output ))Вы можете найти папку данных здесь.
Мы рады объявить о последних улучшениях нашей библиотеки xTuring :
LLaMA 2 Вы можете использовать и настраивать модель LLaMA 2 в различных конфигурациях: готовая , готовая с точностью INT8 , точная настройка LoRA , точная настройка LoRA с точностью INT8 и точная настройка LoRA. настройка с точностью INT4 с использованием оболочки GenericModel и/или вы можете использовать класс Llama2 из xturing.models для тестирования и точной настройки модели. from xturing . models import Llama2
model = Llama2 ()
## or
from xturing . models import BaseModel
model = BaseModel . create ( 'llama2' )Evaluation . Теперь вы можете оценить любую Causal Language Model в любом наборе данных. В настоящее время поддерживается метрика perplexity . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model
model = BaseModel . create ( 'gpt2' )
# Run the Evaluation of the model on the dataset
result = model . evaluate ( dataset )
# Print the result
print ( f"Perplexity of the evalution: { result } " )INT4 Precision — теперь вы можете использовать и точно настраивать любой LLM с INT4 Precision используя GenericLoraKbitModel . # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Run the fine-tuning
model . finetune ( dataset ) # Make the necessary imports
from xturing . models import BaseModel
# Initializes the model: quantize the model with weight-only algorithms
# and replace the linear with Itrex's qbits_linear kernel
model = BaseModel . create ( "llama2_int8" )
# Once the model has been quantized, do inferences directly
output = model . generate ( texts = [ "Why LLM models are becoming so important?" ])
print ( output ) # Make the necessary imports
from xturing . datasets import InstructionDataset
from xturing . models import GenericLoraKbitModel
# Load the desired dataset
dataset = InstructionDataset ( '../llama/alpaca_data' )
# Load the desired model for INT4 bit fine-tuning
model = GenericLoraKbitModel ( 'tiiuae/falcon-7b' )
# Generate outputs on desired prompts
outputs = model . generate ( dataset = dataset , batch_size = 10 )Для понимания его применения рекомендуется изучить рабочий пример Llama LoRA INT4.
Для более глубокого понимания рассмотрите возможность изучения рабочего примера GenericModel, доступного в репозитории.

$ xturing chat -m " <path-to-model-folder> "
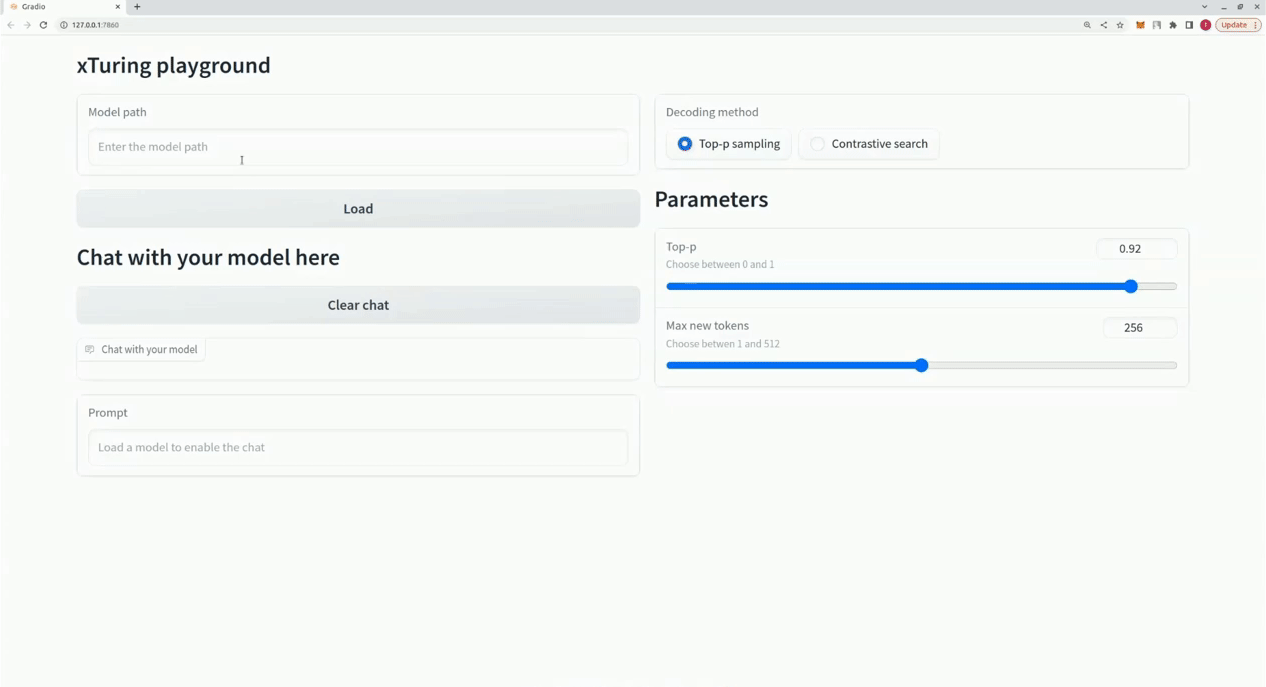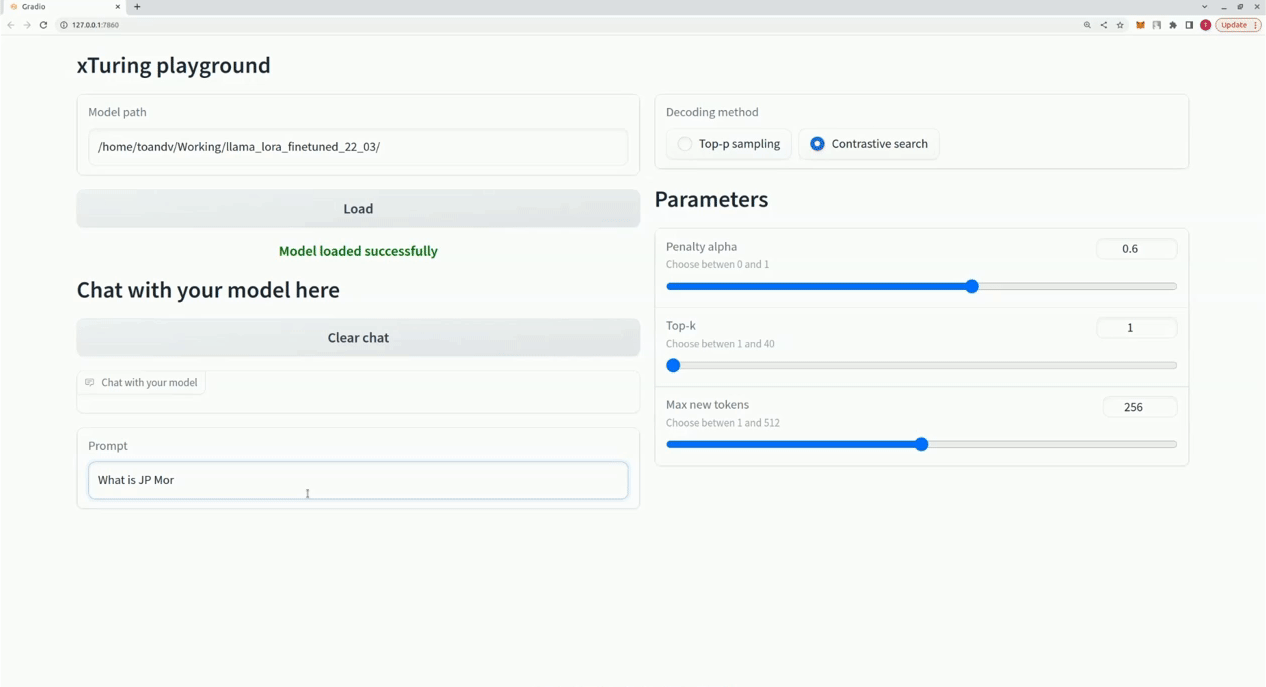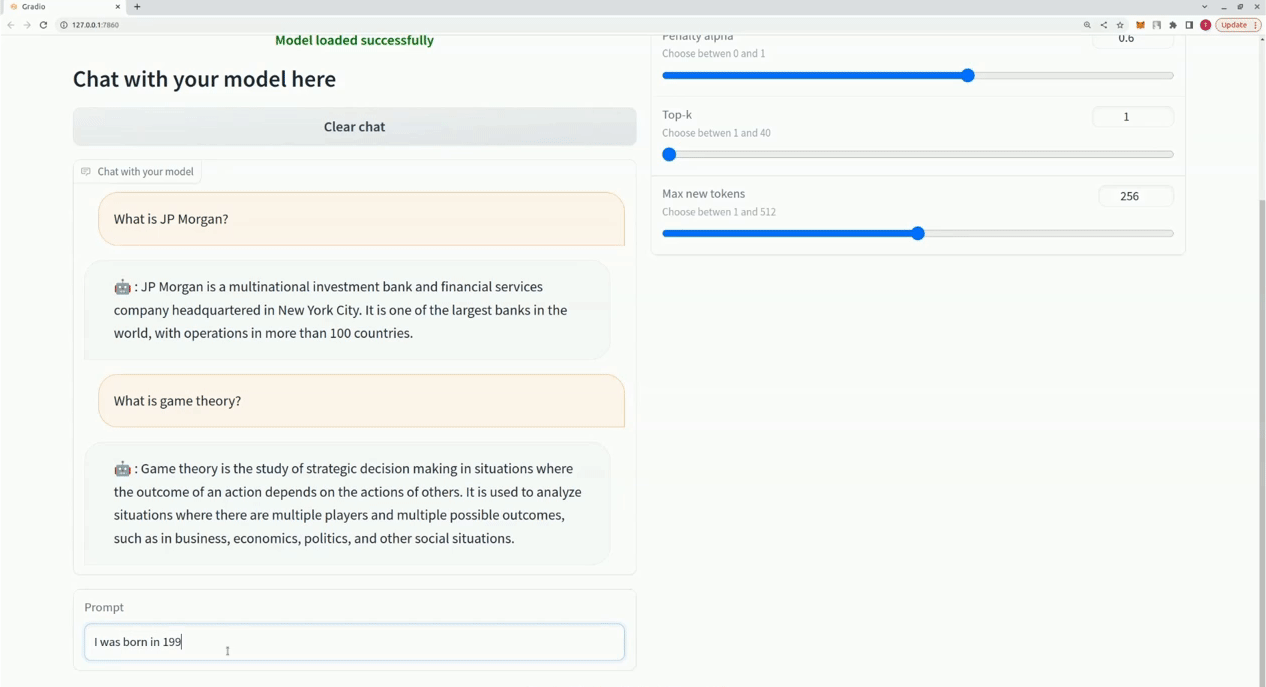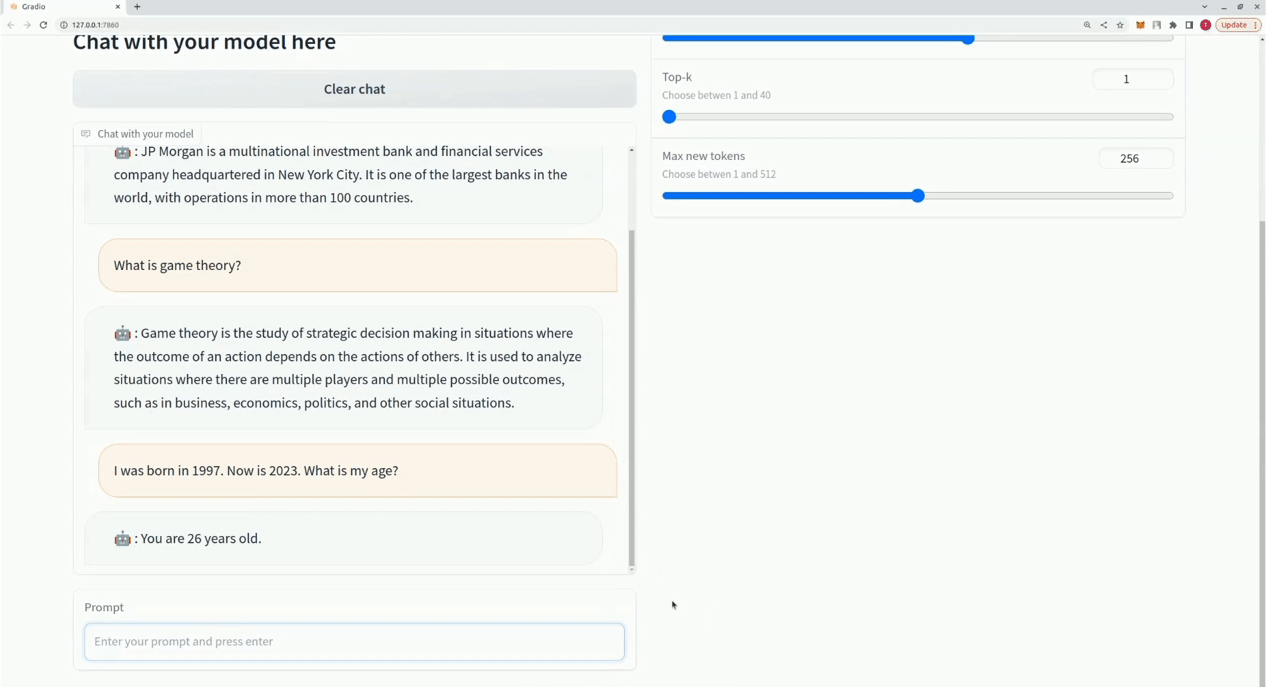
from xturing . datasets import InstructionDataset
from xturing . models import BaseModel
from xturing . ui import Playground
dataset = InstructionDataset ( "./alpaca_data" )
model = BaseModel . create ( "<model_name>" )
model . finetune ( dataset = dataset )
model . save ( "llama_lora_finetuned" )
Playground (). launch () ## launches localhost UI Вот сравнение производительности различных методов точной настройки модели LLaMA 7B. Для точной настройки мы используем набор данных Альпака. Набор данных содержит 52 тыс. инструкций.
Аппаратное обеспечение:
4xA100 40 ГБ графического процессора, 335 ГБ оперативной памяти процессора
Параметры точной настройки:
{
'maximum sequence length' : 512 ,
'batch size' : 1 ,
}| ЛЛаМА-7Б | DeepSpeed + разгрузка процессора | ЛоРА + ДипСпид | LoRA + DeepSpeed + разгрузка ЦП |
|---|---|---|---|
| графический процессор | 33,5 ГБ | 23,7 ГБ | 21,9 ГБ |
| Процессор | 190 ГБ | 10,2 ГБ | 14,9 ГБ |
| Время/эпоха | 21 час | 20 минут | 20 минут |
Внесите свой вклад в это, отправив свои результаты производительности на других графических процессорах, создав проблему с характеристиками вашего оборудования, потреблением памяти и временем за эпоху.
Мы уже доработали некоторые модели, которые вы можете использовать в качестве базы или начать играть. Вот как вы их загрузите:
from xturing . models import BaseModel
model = BaseModel . load ( "x/distilgpt2_lora_finetuned_alpaca" )| модель | набор данных | Путь |
|---|---|---|
| ДистиллGPT-2 LoRA | альпака | x/distilgpt2_lora_finetuned_alpaca |
| ЛАМА ЛОРА | альпака | x/llama_lora_finetuned_alpaca |
Ниже приведен список всех поддерживаемых моделей через класс BaseModel xTuring и соответствующие им ключи для их загрузки.
| Модель | Ключ |
|---|---|
| Цвести | цвести |
| Церебрас | мозг |
| ДистиллГПТ-2 | дистилляция gpt2 |
| Сокол-7Б | сокол |
| Галактика | Галактика |
| ГПТ-J | gptj |
| ГПТ-2 | gpt2 |
| ЛлаМА | лама |
| ЛлаМА2 | лама2 |
| ОПТ-1.3Б | выбрать |
Вышеупомянутое является базовыми вариантами LLM. Ниже приведены шаблоны для получения версий LoRA , INT8 , INT8 + LoRA и INT4 + LoRA .
| Версия | Шаблон |
|---|---|
| ЛоРА | <model_key>_lora |
| INT8 | <ключ_модели>_int8 |
| ИНТ8 + ЛоРА | <model_key>_lora_int8 |
** Чтобы загрузить версию INT4+LoRA любой модели, вам нужно будет использовать класс GenericLoraKbitModel из xturing.models . Ниже описано, как его использовать:
model = GenericLoraKbitModel ( '<model_path>' ) model_path можно заменить локальным каталогом или любой моделью библиотеки HuggingFace, например facebook/opt-1.3b .
LLaMA , GPT-J , GPT-2 , OPT , Cerebras-GPT , Galactica и Bloom . Generic model Falcon-7B Если у вас есть какие-либо вопросы, вы можете создать проблему в этом репозитории.
Вы также можете присоединиться к нашему серверу Discord и начать обсуждение на канале #xturing .
Этот проект лицензируется по лицензии Apache 2.0 — подробности см. в файле ЛИЦЕНЗИИ.
Как проект с открытым исходным кодом в быстро развивающейся области, мы приветствуем любые вклады, включая новые функции и улучшенную документацию. Пожалуйста, прочитайте наше руководство по участию, чтобы узнать, как вы можете принять участие.


