bedrock agents infer models
1.0.0
Этот проект служит для разработчиков основой для расширения вариантов использования различных моделей больших языков (LLM) с помощью агентов Amazon Bedrock. Цель состоит в том, чтобы продемонстрировать потенциал использования нескольких моделей на Bedrock для создания цепных ответов, которые адаптируются к различным сценариям. Помимо создания текстовых результатов, это приложение также поддерживает создание и исследование изображений с использованием моделей генерации изображений и преобразования текста в изображение. Эта расширенная функциональность повышает универсальность приложения, делая его пригодным для более творческих и визуальных вариантов использования.
Для тех, кто предпочитает подход «Инфраструктура как код» (IaC), мы также предоставляем шаблон AWS CloudFormation, в котором настраиваются основные компоненты, такие как агент Amazon Bedrock, корзина S3 и функция Lambda. Если вы предпочитаете развернуть этот проект через AWS CloudFormation, обратитесь к руководству семинара здесь.
Кроме того, этот файл README проведет вас через пошаговый процесс ручной установки и настройки агентов Amazon Bedrock через консоль AWS, что даст вам возможность экспериментировать с новейшими моделями и полностью раскрыть потенциал агентов Bedrock.
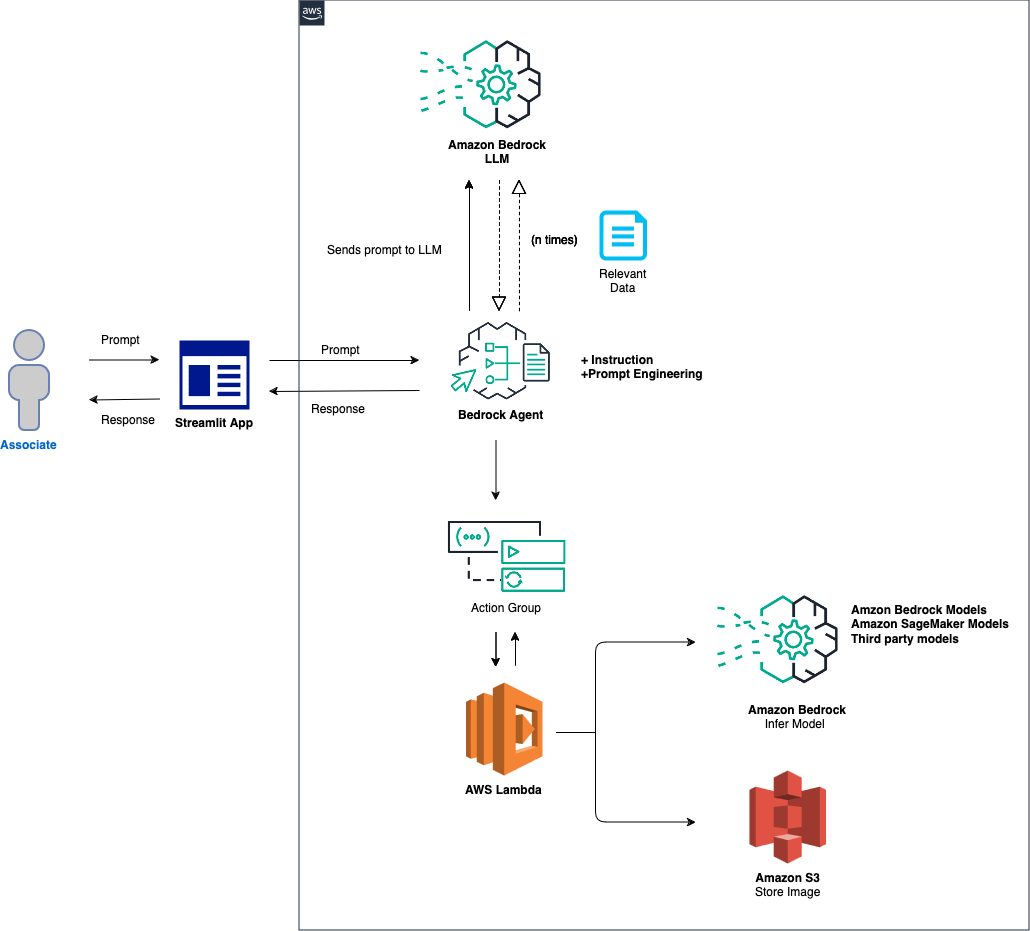
Общий обзор решения выглядит следующим образом:
Настройка агента и среды. Решение начинается с настройки агента Amazon Bedrock, функции AWS Lambda и корзины Amazon S3. На этом этапе закладывается основа для взаимодействия с моделью и обработки данных, а также подготовка системы к получению и обработке запросов от внешнего приложения. Обработка подсказки и вывод модели. Когда подсказка получена от внешнего приложения, агент Bedrock оценивает и отправляет подсказку вместе с указанным идентификатором модели в функцию Lambda, используя механизм группы действий. На этом этапе используется схема API группы действий для точной обработки параметров, что облегчает эффективный вывод модели на основе приглашения ввода. Обработка данных и генерация ответов. Для задач, связанных с преобразованием изображения в текст или текста в изображение, функция Lambda взаимодействует с ведром S3 для выполнения необходимых операций чтения или записи изображений. Этот шаг обеспечивает динамическую обработку мультимедийного контента, кульминацией которой является генерация ответов или преобразований, диктуемых исходным запросом.
В следующих разделах мы расскажем вам:
AWS SAM (модель бессерверных приложений) — это платформа с открытым исходным кодом, которая помогает создавать бессерверные приложения на AWS. Он упрощает развертывание, управление и мониторинг бессерверных ресурсов, таких как AWS Lambda, Amazon API Gateway, Amazon DynamoDB и других. Вот подробное руководство по настройке и использованию AWS SAM.
Платформа упрощает процесс создания, развертывания и управления бессерверными приложениями, абстрагируя сложности облачной инфраструктуры. Он обеспечивает унифицированный способ определения бессерверных ресурсов и управления ими с помощью файла конфигурации и набора команд.
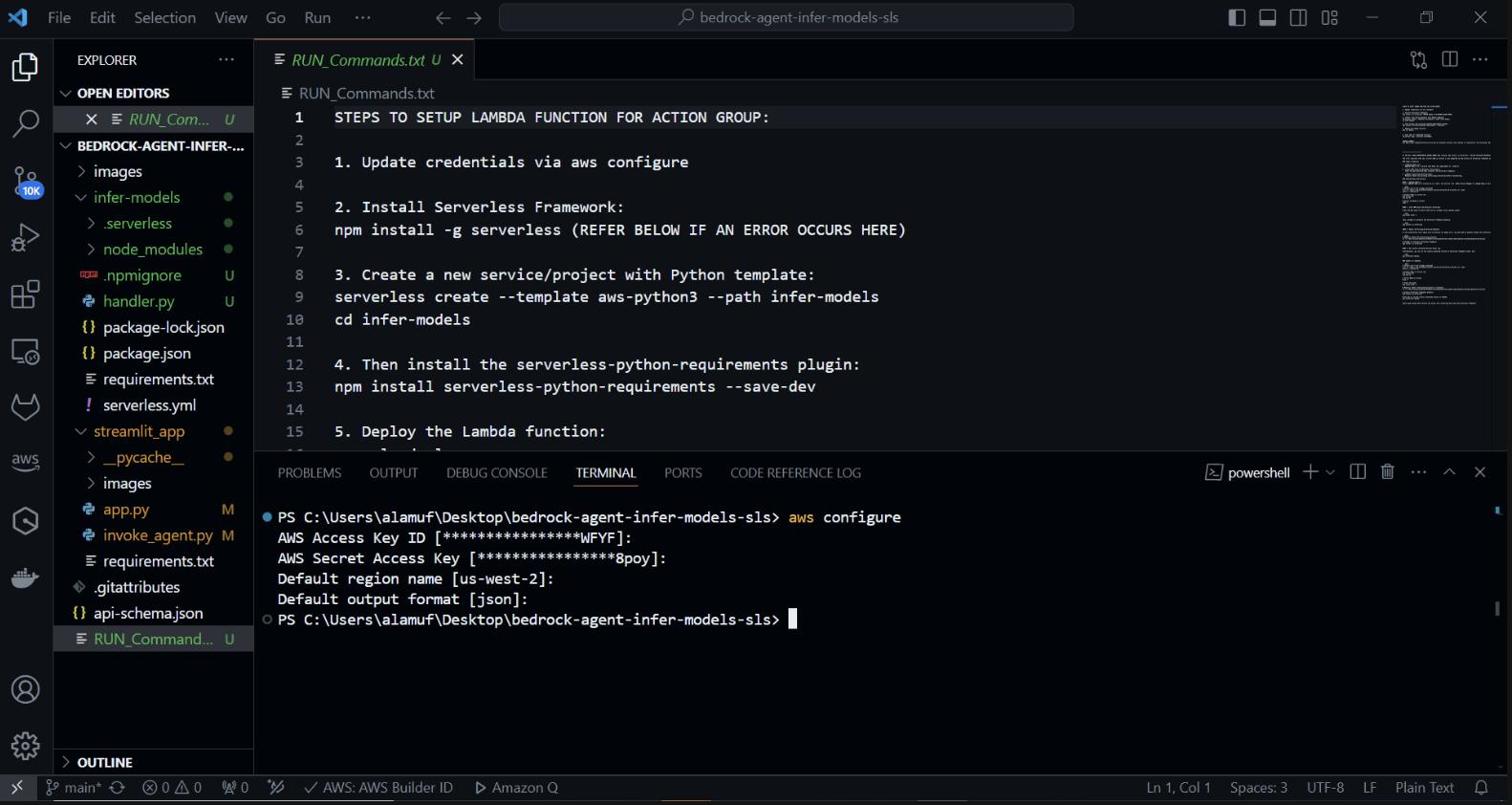
Создайте новый бессерверный проект с помощью шаблона Python. В своем терминале запустите: cd infer-models Затем запустите бессерверный режим. 
Это запустит процесс интерактивного создания проекта Serverless Framework. Вам будет предложено несколько вариантов: Выберите «Создать новое бессерверное приложение». Выберите шаблон «aws-python3» и укажите «infer-models» в качестве имени своего проекта.
Это создаст новый каталог под названием infer-models с базовой структурой бессерверного проекта и шаблоном Python.
Вам также может быть предложено войти/зарегистрироваться. выберите опцию «Войти/Зарегистрироваться». Откроется окно браузера, в котором вы сможете создать новую учетную запись или войти в систему, если она у вас уже есть. После входа в систему или создания учетной записи выберите опцию «Framework Open Source», которую можно использовать бесплатно.
Если ваш стек не удалось развернуть, закомментируйте вторую строку файла serverless.yml.
После выполнения бессерверной команды и следования подсказкам будет создан новый каталог с именем проекта (например, infer-models), содержащий шаблонную структуру и файлы конфигурации для бессерверного проекта.
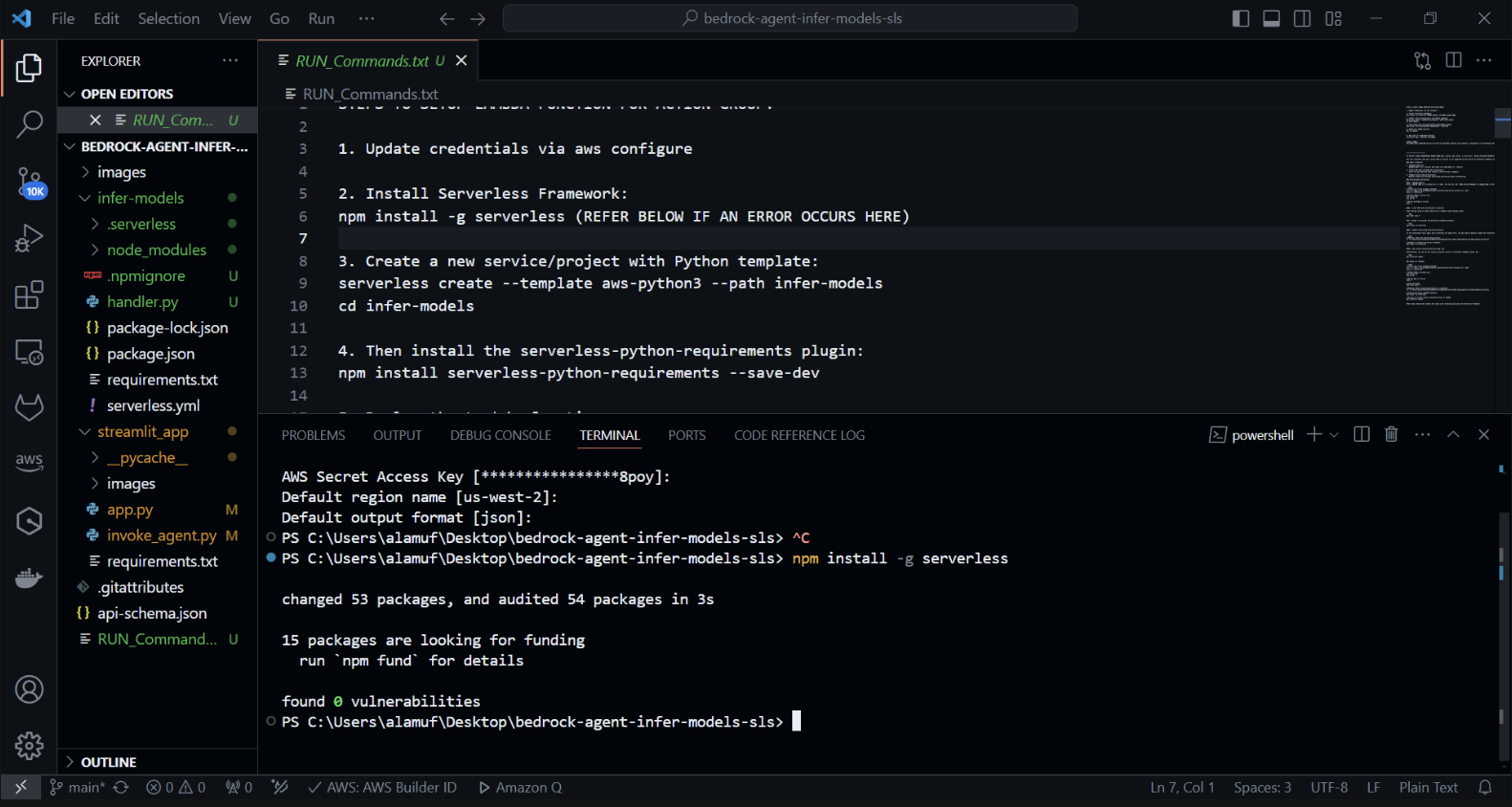
Теперь мы установим плагин serverless-python-requirements: плагин serverless-python-requirements помогает управлять зависимостями Python для вашего бессерверного проекта. Установите его, запустив:
npm install serverless-python-requirements —save-dev
3.) npx sls deploy
(ПЕРЕД ВЫПОЛНЕНИЕМ КОМАНДЫ НЕОБХОДИМО УСТАНОВИТЬ И ЗАПУСТИТЬ DOCKER ENGINE. ДОПОЛНИТЕЛЬНУЮ ИНФОРМАЦИЮ МОЖНО НАЙТИ ЗДЕСЬ)
(Это упакует и развернет функцию AWS Lambda) 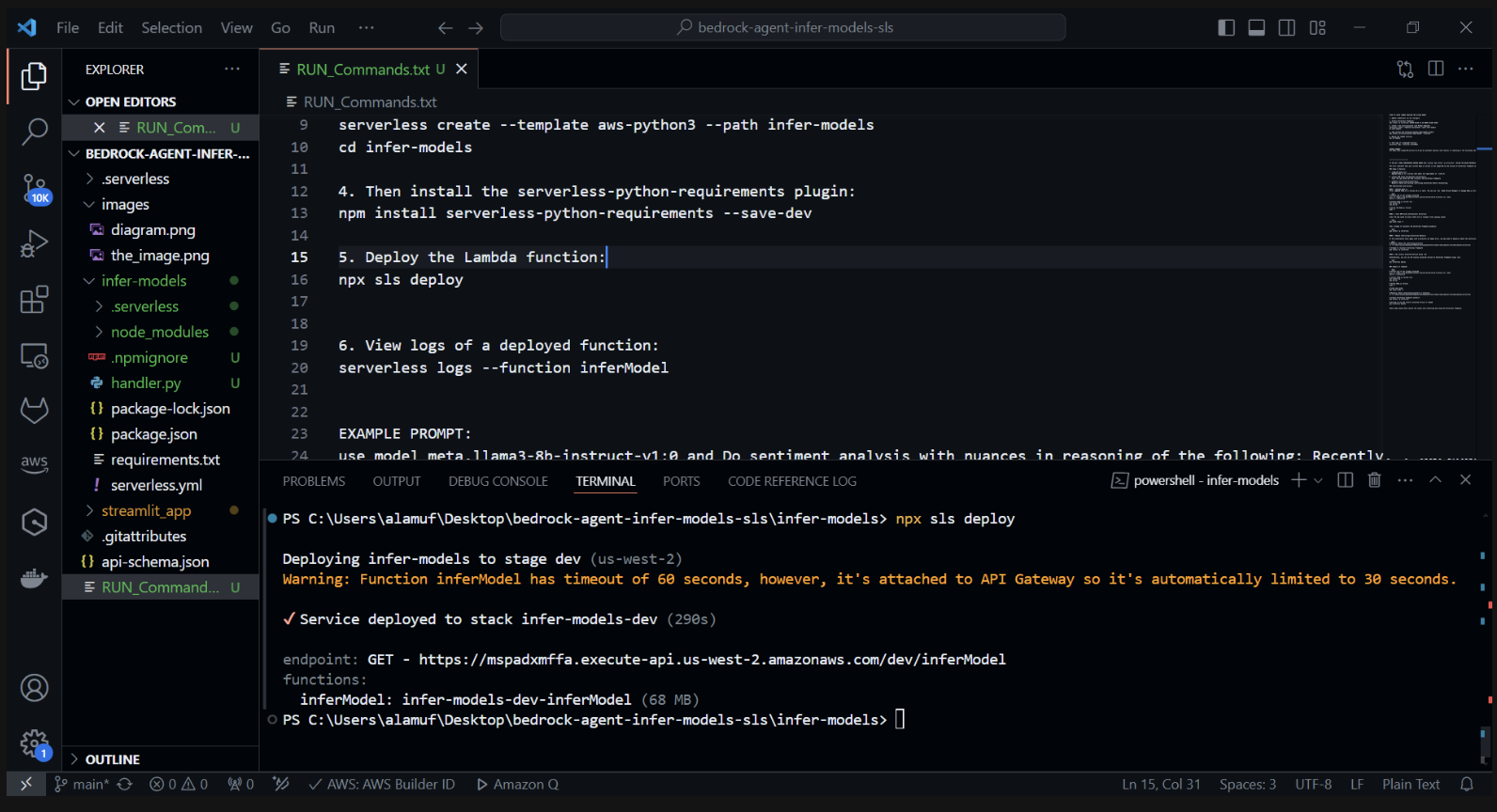
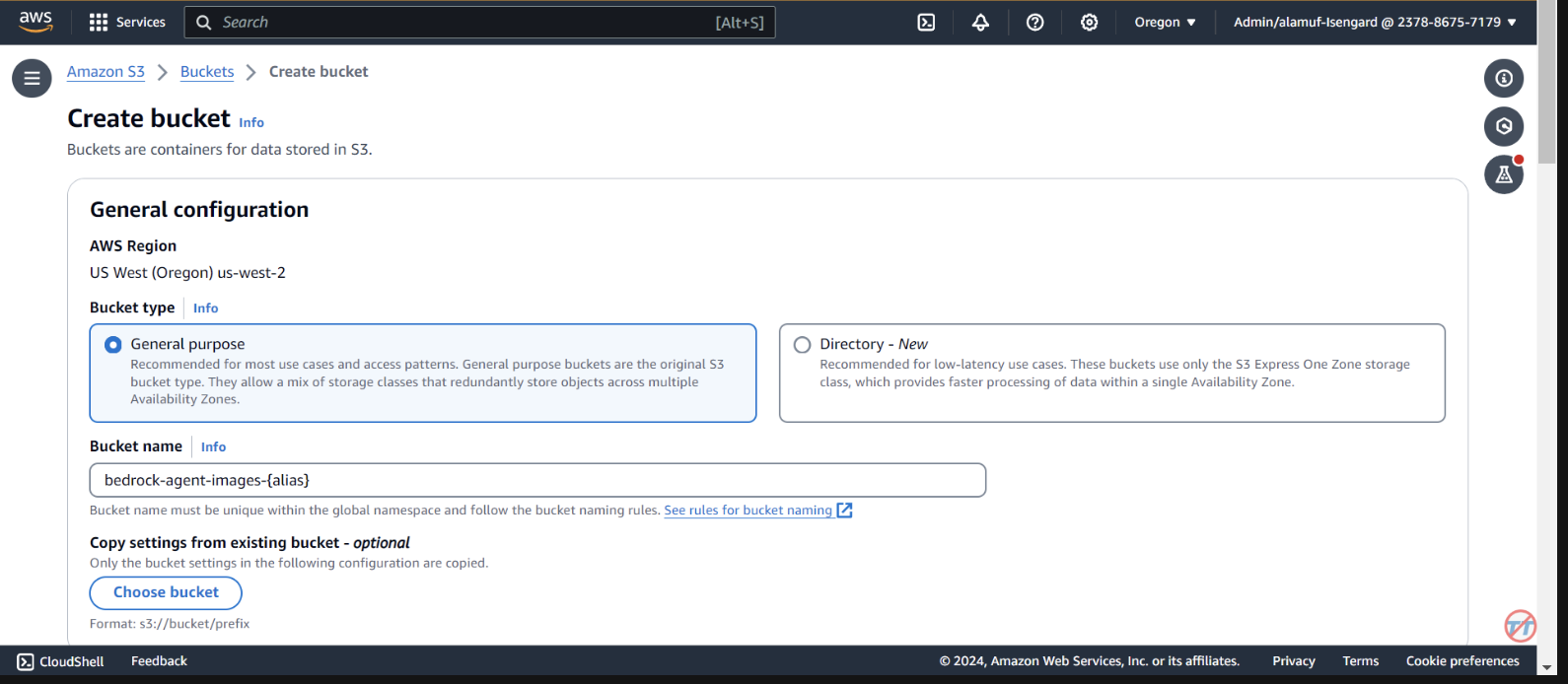
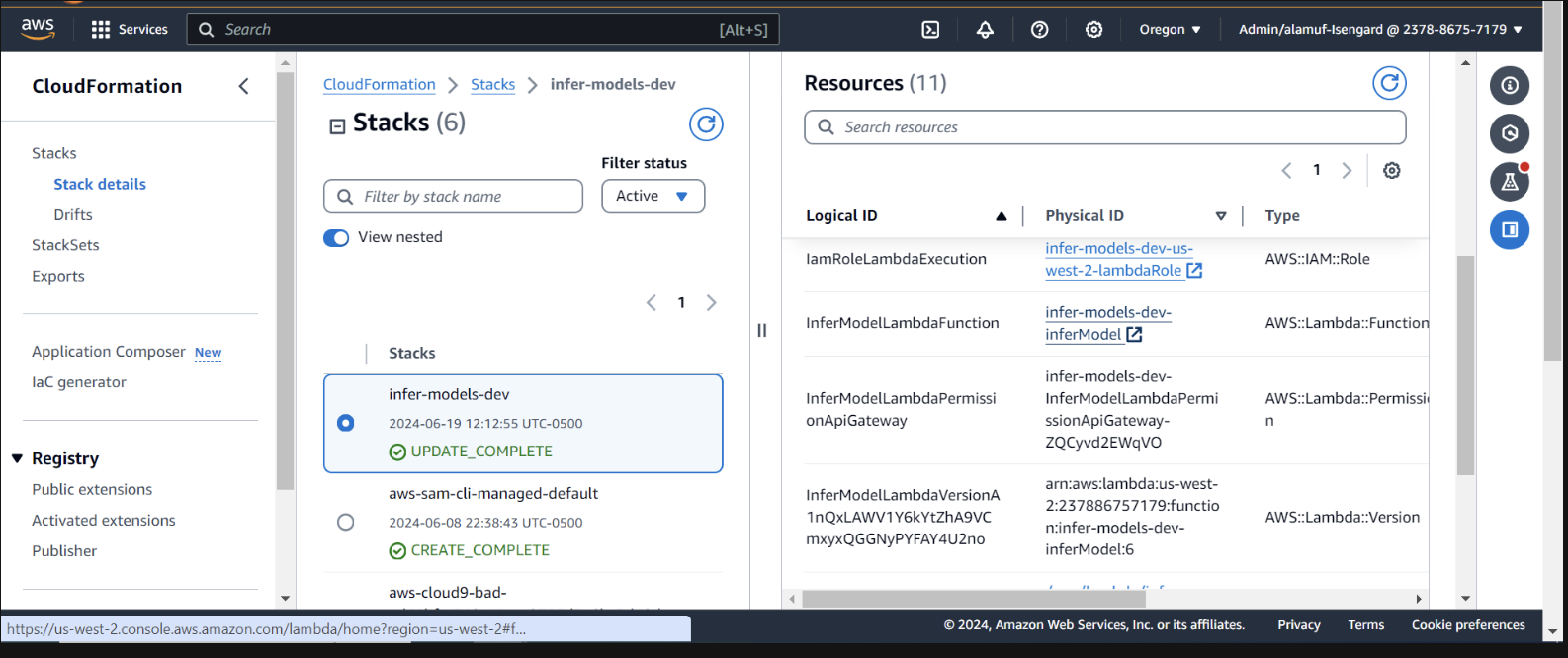
Проверьте развертывание в CloudFormation в консоли AWS.
Нам необходимо предоставить базовому агенту разрешения на вызов лямбда-функции. Откройте лямбда-функцию и прокрутите вниз, чтобы выбрать вкладку «Конфигурация» . Слева выберите Разрешения . Прокрутите вниз до раздела «Заявления политики на основе ресурсов» и выберите «Добавить разрешения».
Выберите сервис AWS посередине для вашего заявления о политике. Выберите «Другое» для своей службы и укажите параметр «allow-agent» для StatementID. Для принципала укажите Bedrock.amazonaws.com .
Введите arn:aws:bedrock:us-west-2:{aws-account-id}:agent/* . Обратите внимание: AWS рекомендует использовать минимальные привилегии, поэтому только разрешенный агент может вызывать эту функцию Lambda. Символ * в конце ARN предоставляет любому агенту в учетной записи доступ для вызова этой лямбды. В идеале мы бы не использовали это в производственной среде. Наконец, для действия выберите лямбда:InvokeFunction , затем Сохранить. 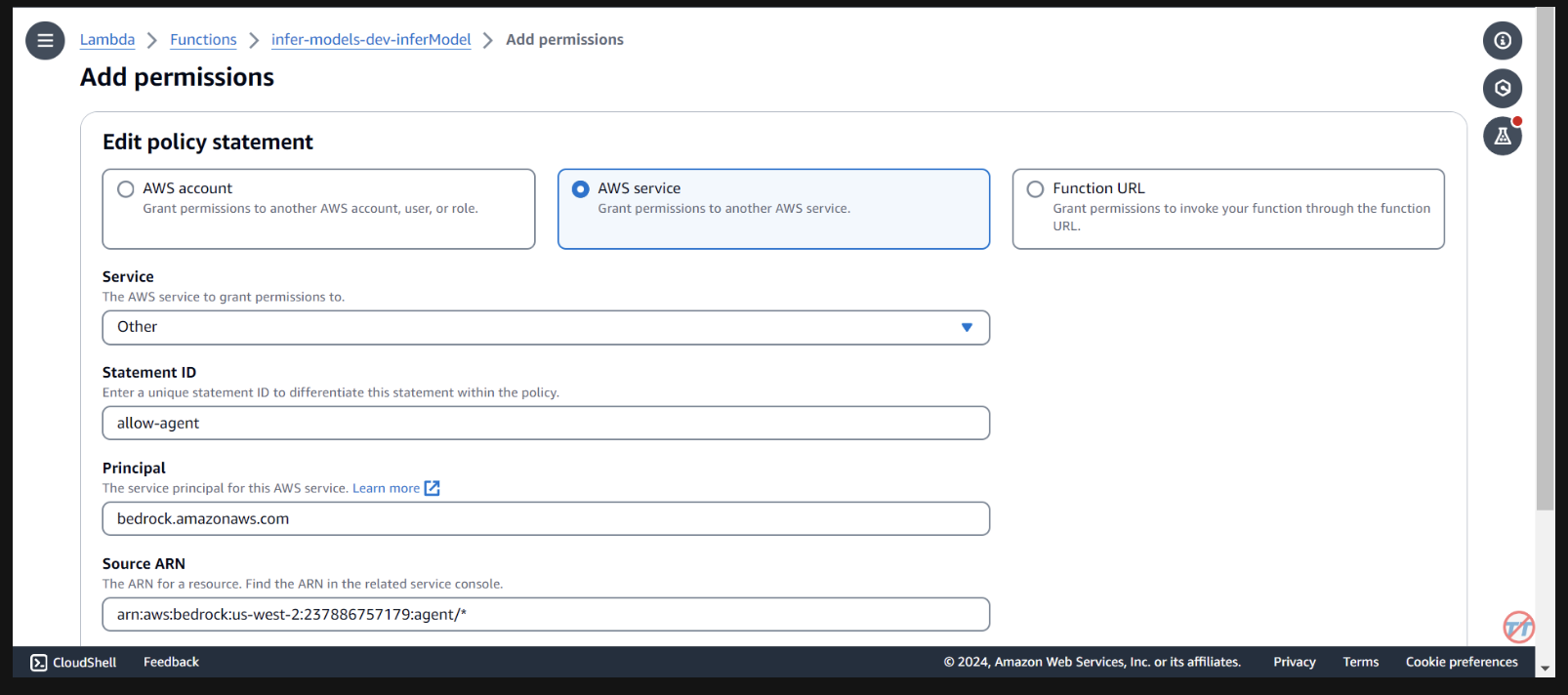
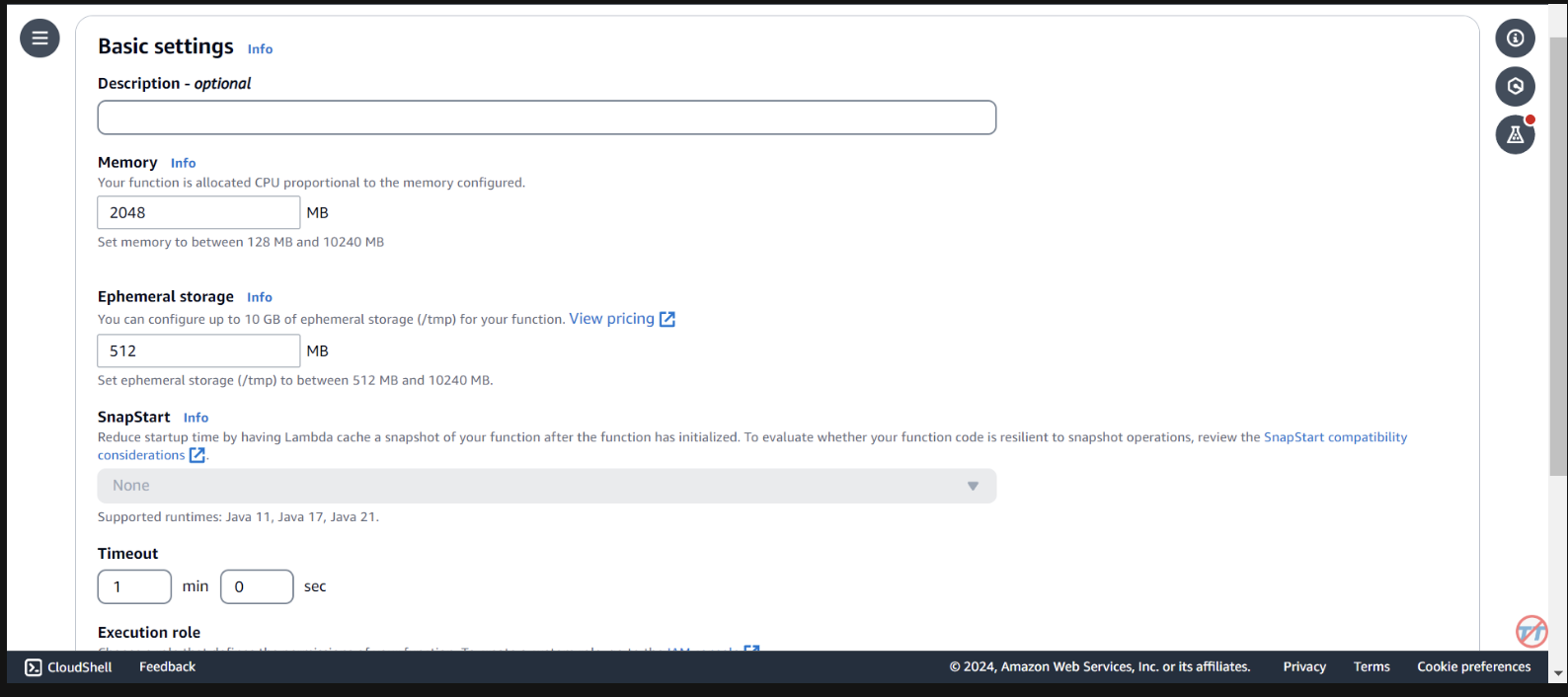
Чтобы помочь с выводом, мы увеличим процессор/память функции Lambda. Мы также увеличим время ожидания, чтобы у функции было достаточно времени для завершения вызова. Выберите «Общая конфигурация» слева, затем «Изменить» справа.
Измените Память на 2048 МБ и время ожидания на 1 минуту . Прокрутите вниз и выберите Сохранить.
Agents . Укажите имя агента, например multi-model-agent, затем создайте агент. 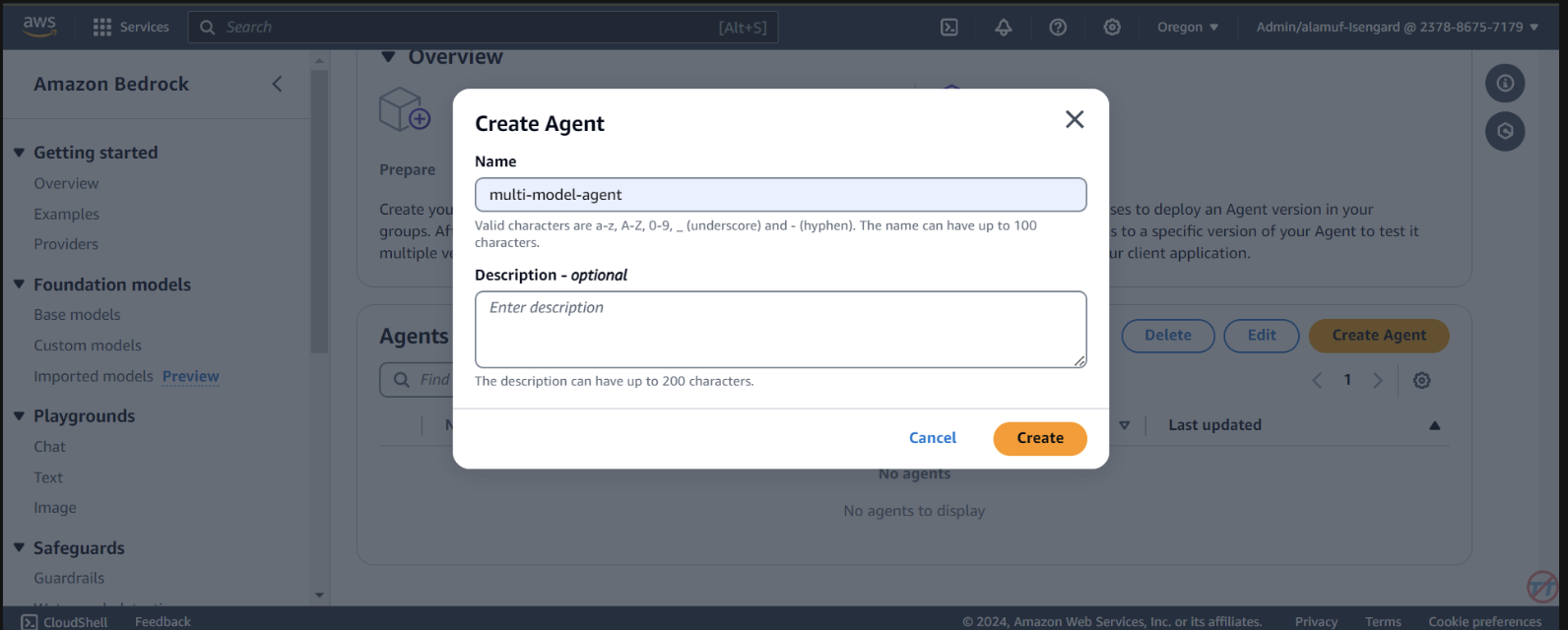
You are a research agent that interacts with various large language models. You pass the model ID and prompt from requests to large language models to create and store images. Then, the LLM will return a presigned URL to the image similar to the URL example provided. You also call LLMS for text and code generation, summarization, problem solving, text-to-sql, response comparisons and ratings. Remeber. you use other large language models for inference. Do not decide when to provide your own response, unless asked.
После этого обязательно прокрутите страницу вверх и нажмите кнопку «Сохранить», прежде чем переходить к следующему шагу.
Далее мы добавим группу действий. Прокрутите вниз до Action groups затем выберите «Добавить» . Вызовите группу действий call-model .
Для типа группы действий выберите Определить с помощью схем API.
В следующем разделе мы выберем существующую функцию Lambda infer-models-dev-inferModel .
Для схемы API мы выберем Define with in-line OpenAPI schema editor . Скопируйте и вставьте схему ниже во встроенный редактор схемы OpenAPI , затем выберите «Добавить» : 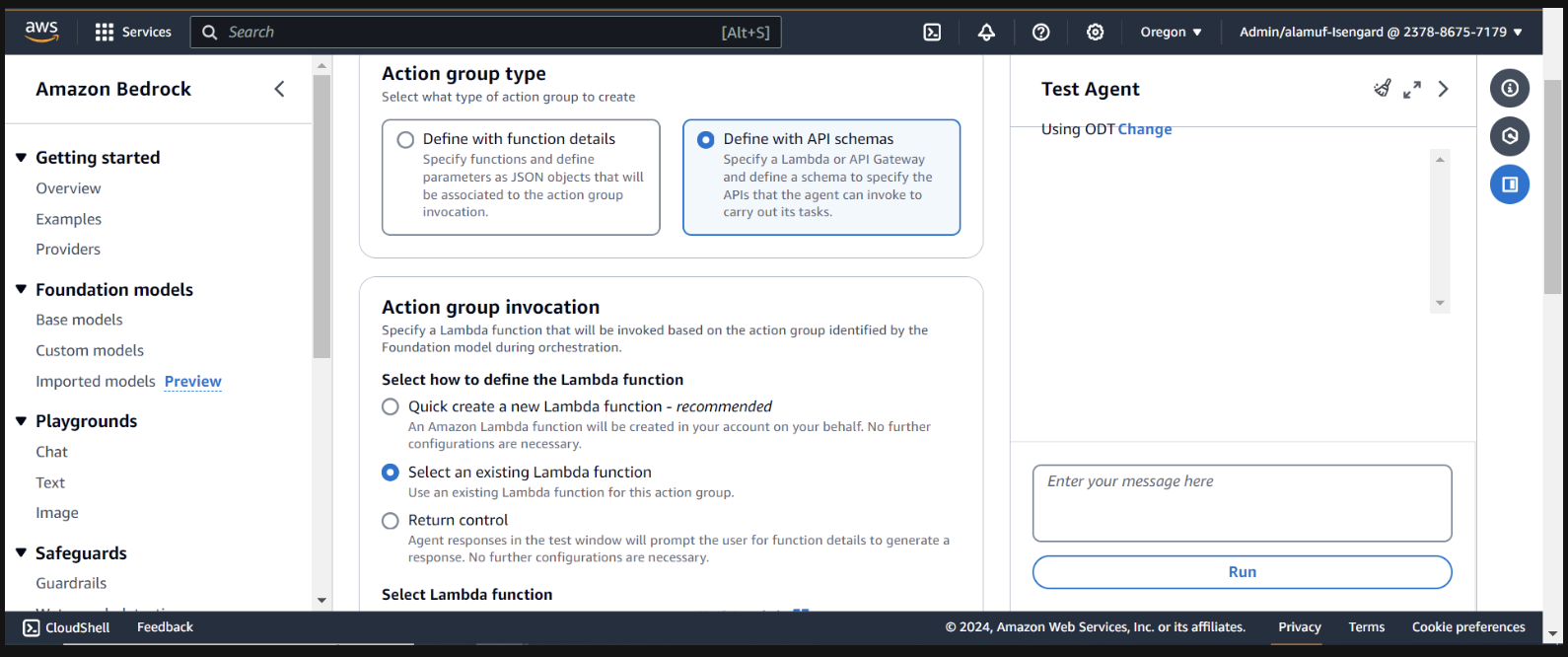
(This API schema is needed so that the bedrock agent knows the format structure and parameters required for the action group to interact with the Lambda function.)
{
"openapi": "3.0.0",
"info": {
"title": "Model Inference API",
"description": "API for inferring a model with a prompt, and model ID.",
"version": "1.0.0"
},
"paths": {
"/callModel": {
"post": {
"description": "Call a model with a prompt, model ID, and an optional image",
"parameters": [
{
"name": "modelId",
"in": "query",
"description": "The ID of the model to call",
"required": true,
"schema": {
"type": "string"
}
},
{
"name": "prompt",
"in": "query",
"description": "The prompt to provide to the model",
"required": true,
"schema": {
"type": "string"
}
}
],
"requestBody": {
"required": true,
"content": {
"multipart/form-data": {
"schema": {
"type": "object",
"properties": {
"modelId": {
"type": "string",
"description": "The ID of the model to call"
},
"prompt": {
"type": "string",
"description": "The prompt to provide to the model"
},
"image": {
"type": "string",
"format": "binary",
"description": "An optional image to provide to the model"
}
},
"required": ["modelId", "prompt"]
}
}
}
},
"responses": {
"200": {
"description": "Successful response",
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"result": {
"type": "string",
"description": "The result of calling the model with the provided prompt and optional image"
}
}
}
}
}
}
}
}
}
}
}
Orchestration » включите параметр Override orchestration template defaults . 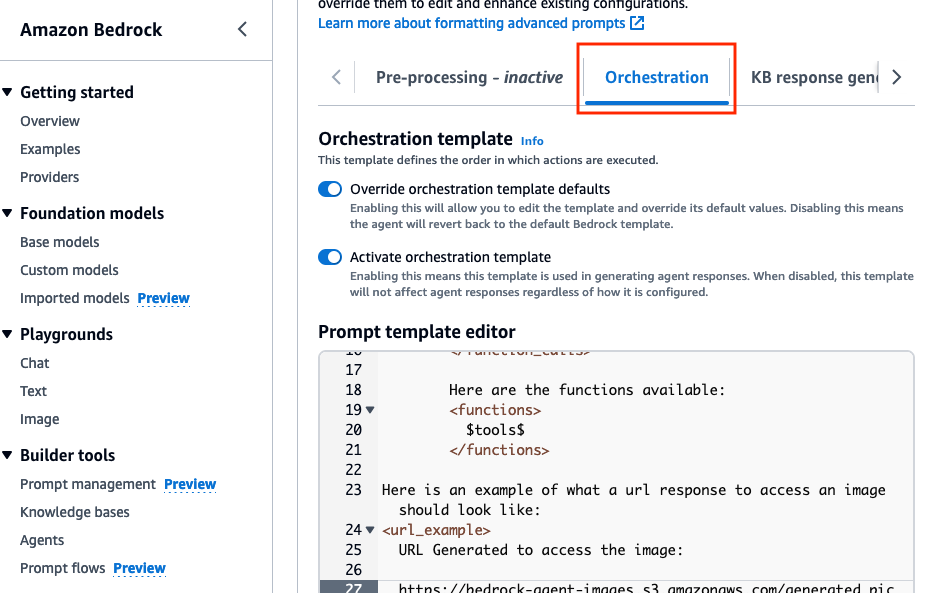
Here is an example of what a url response to access an image should look like:
<url_example>
URL Generated to access the image:
https://bedrock-agent-images.s3.amazonaws.com/generated_pic.png?AWSAccessKeyId=123xyz&Signature=rlF0gN%2BuaTHzuEDfELz8GOwJacA%3D&x-amz-security-token=IQoJb3JpZ2msqKr6cs7sTNRG145hKcxCUngJtRcQ%2FzsvDvt0QUSyl7xgp8yldZJu5Jg%3D%3D&Expires=1712628409
</url_example>
Этот запрос помогает предоставить агенту пример форматирования ответа по заранее заданному URL-адресу после создания изображения в корзине S3. Кроме того, существует возможность использовать специальную функцию синтаксического анализатора Lambda для более детального форматирования.
Прокрутите страницу вниз и нажмите кнопку Save and exit .
После этого обязательно снова нажмите кнопку Save and exit вверху, а затем кнопку «Подготовить» вверху пользовательского интерфейса агента тестирования справа. Это позволит нам протестировать последние изменения.
(Прежде чем продолжить, обязательно включите все модели через консоль Amazon Bedrock, с которыми вы планируете проводить тестирование.)
Чтобы начать тестирование, подготовьте агент, найдя кнопку подготовки на странице конструктора агентов. 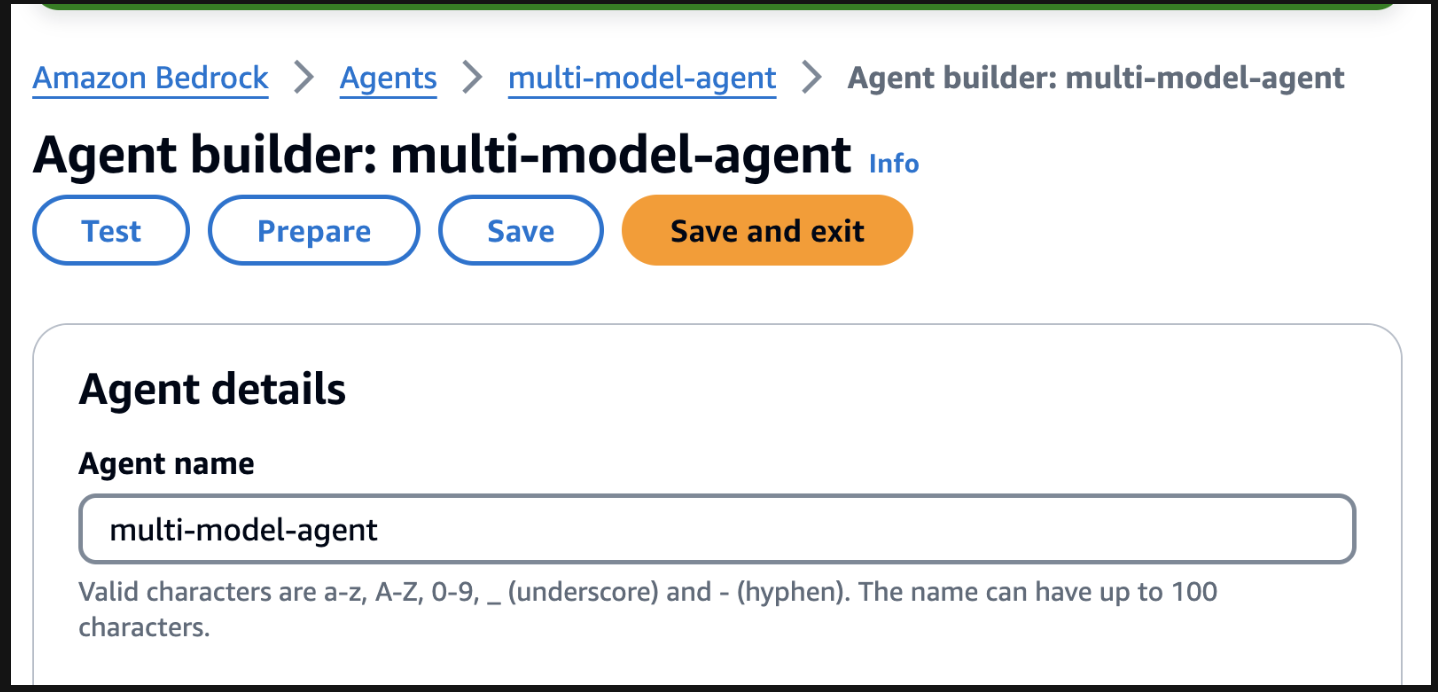
Справа вы должны увидеть возможность протестировать агент с помощью поля пользовательского ввода. Ниже приведены несколько подсказок, которые вы можете проверить. Тем не менее, рекомендуется проявить творческий подход и протестировать варианты подсказок.
Перед тестированием следует отметить одну вещь. Когда вы выполняете преобразование текста в изображение или изображения в текст, код проекта статически ссылается на один и тот же файл .png. В идеальной среде этот шаг можно настроить более динамично.
Use model amazon.titan-image-generator-v1 and create me an image of a woman in a boat on a river.
Use model anthropic.claude-3-haiku-20240307-v1:0 and describe to me the image that is uploaded. The model function will have the information needed to provide a response. So, dont ask about the image.
Use model stability.stable-diffusion-xl-v1. Create an image of an astronaut riding a horse in the desert.
Use model meta.llama3-70b-instruct-v1:0. You are a gifted copywriter, with special expertise in writing Google ads. You are tasked to write a persuasive and personalized Google ad based on a company name and a short description. You need to write the Headline and the content of the Ad itself. For example: Company: Upwork Description: Freelancer marketplace Headline: Upwork: Hire The Best - Trust Your Job To True Experts Ad: Connect your business to Expert professionals & agencies with specialized talent. Post a job today to access Upwork's talent pool of quality professionals & agencies. Grow your team fast. 90% of customers rehire. Trusted by 5M+ businesses. Secure payments. - Write a persuasive and personalized Google ad for the following company. Company: Click Description: SEO services
(Если вы хотите настроить пользовательский интерфейс для этого проекта, перейдите к шагу 6)
Для этого шага вам понадобится agent alias ID , а также agent ID . Перейдите в консоль управления Bedrock, затем выберите свой многомодельный агент. Скопируйте Agent ID из правого верхнего угла раздела Agent overview . Затем прокрутите вниз до пункта «Псевдонимы» и выберите «Создать» . Назовите псевдоним a1 , затем создайте агента. Сохраните созданный идентификатор псевдонима , а НЕ имя псевдонима. 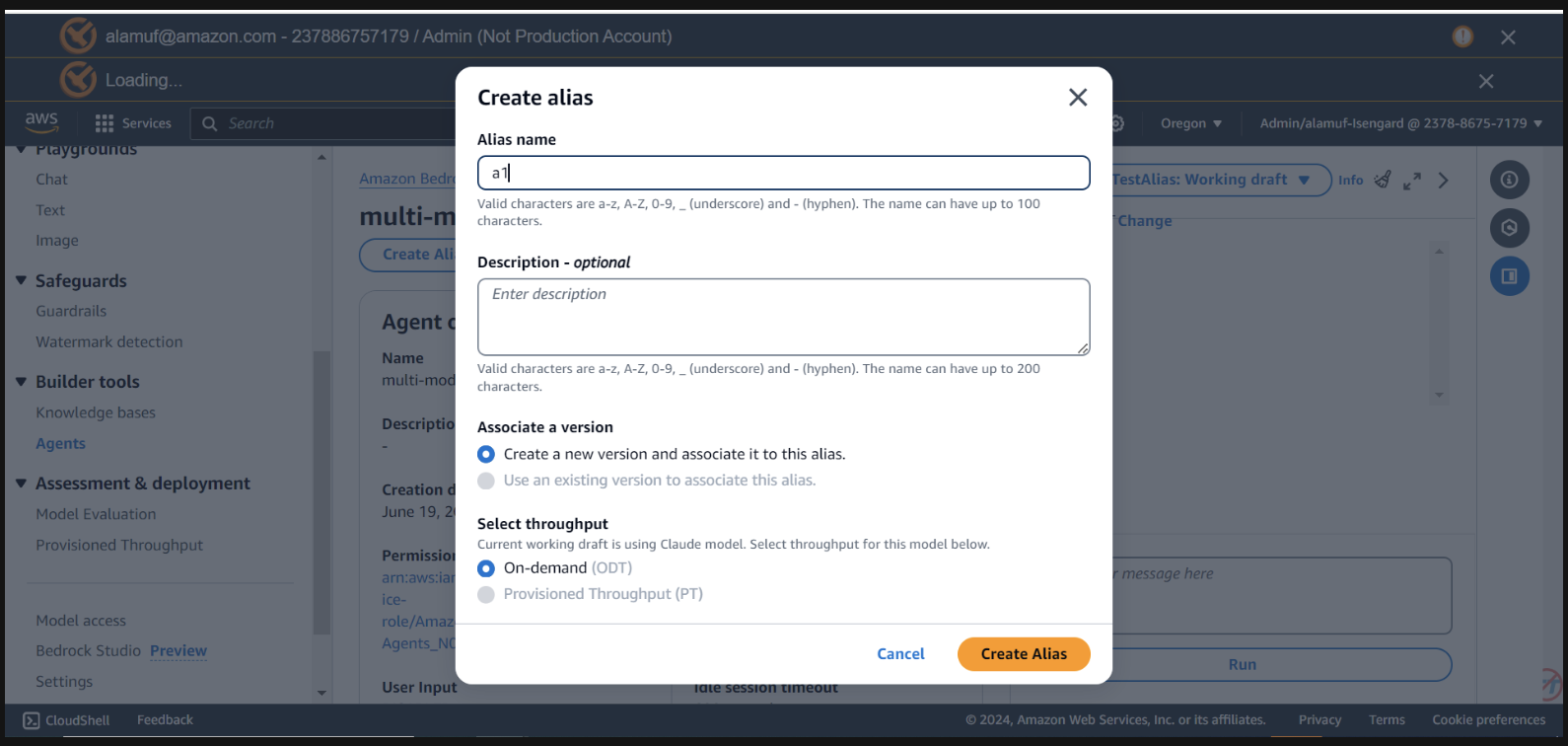
теперь вернитесь к IDE, которую вы использовали для открытия проекта.
Перейдите в каталогstreamlit_app :
Обновить конфигурацию :
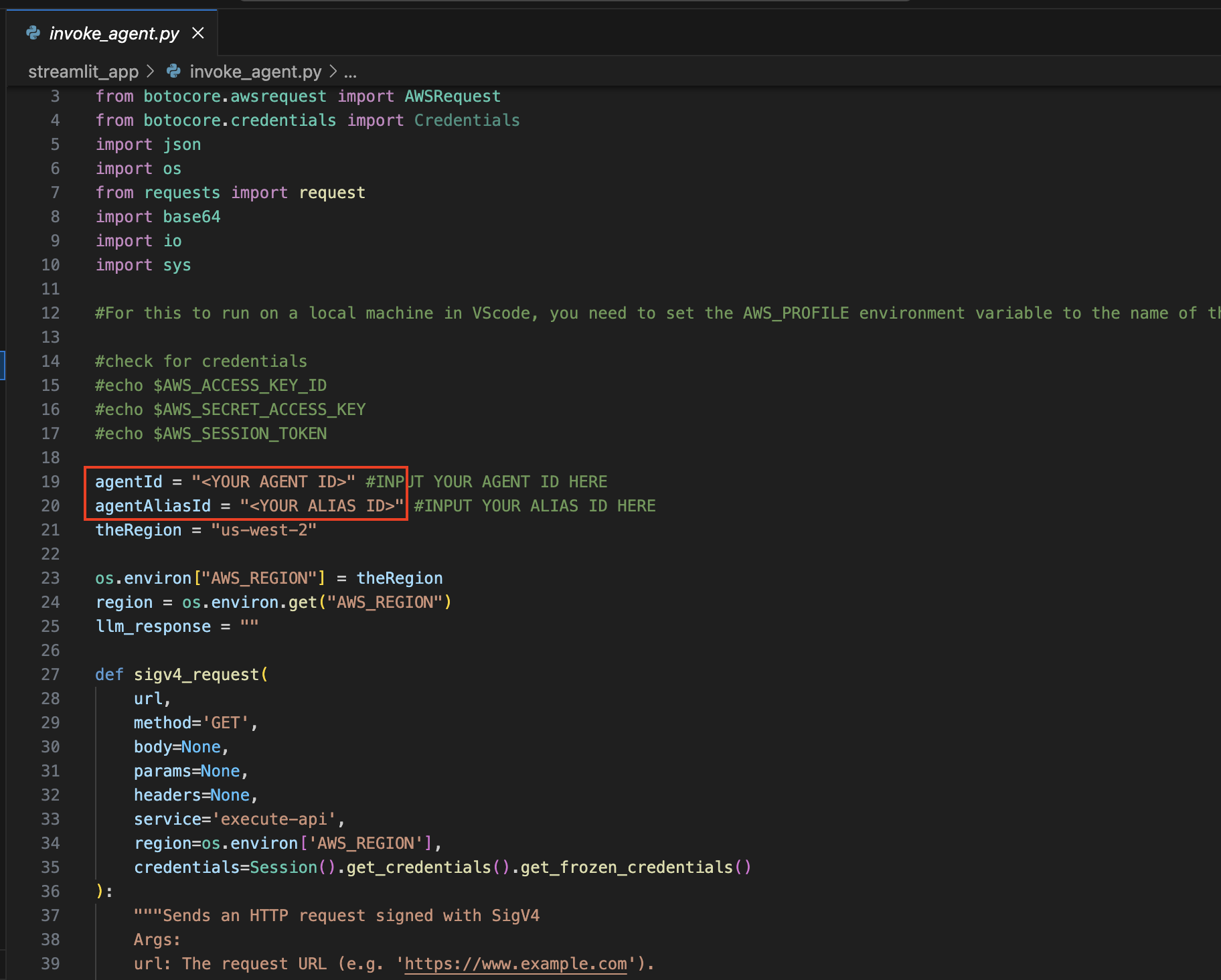
Откройте файл ignore_agent.py .
В строках 19 и 20 обновите переменные agentId и agentAliasId соответствующими значениями, а затем сохраните их.
Установите Streamlit (если еще не установлен):
Запустите следующую команду, чтобы установить все необходимые зависимости:
pip install streamlit boto3 pandasЗапустите приложение Streamlit :
streamlit_app : streamlit run app.py
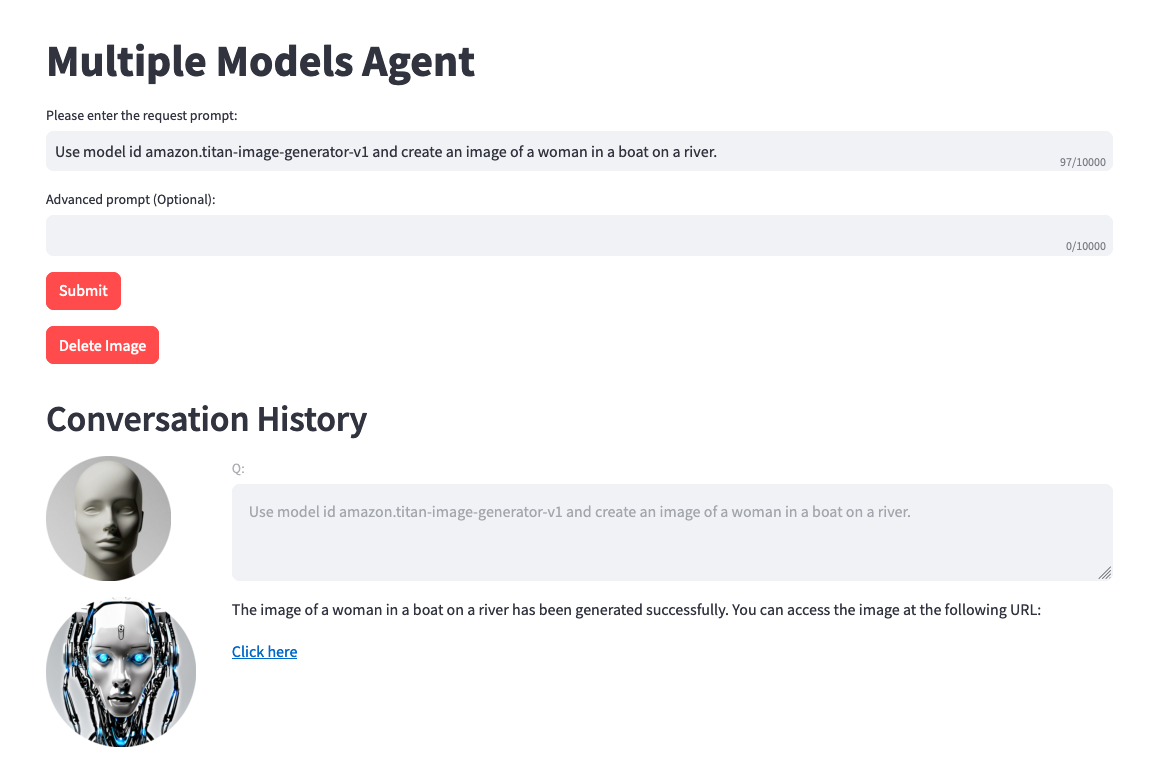
Помните , что вы можете использовать любую доступную модель от Amazon Bedrock и не ограничиваться приведенным выше списком. Если идентификатор модели не указан, обратитесь к последним доступным моделям (идентификаторам) на странице документации Amazon Bedrock здесь.
Вы можете использовать предоставленный проект для точной настройки и сравнения этого решения с вашими собственными наборами данных и вариантами использования. Исследуйте различные комбинации моделей, расширяйте границы возможного и внедряйте инновации в постоянно развивающуюся среду генеративного искусственного интеллекта.
См. ВКЛАД для получения дополнительной информации.
Эта библиотека лицензируется по лицензии MIT-0. См. файл ЛИЦЕНЗИИ.


