AttackVLM
1.0.0
[Страница проекта] | [Слайды] | [arXiv] | [Хранилище данных]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

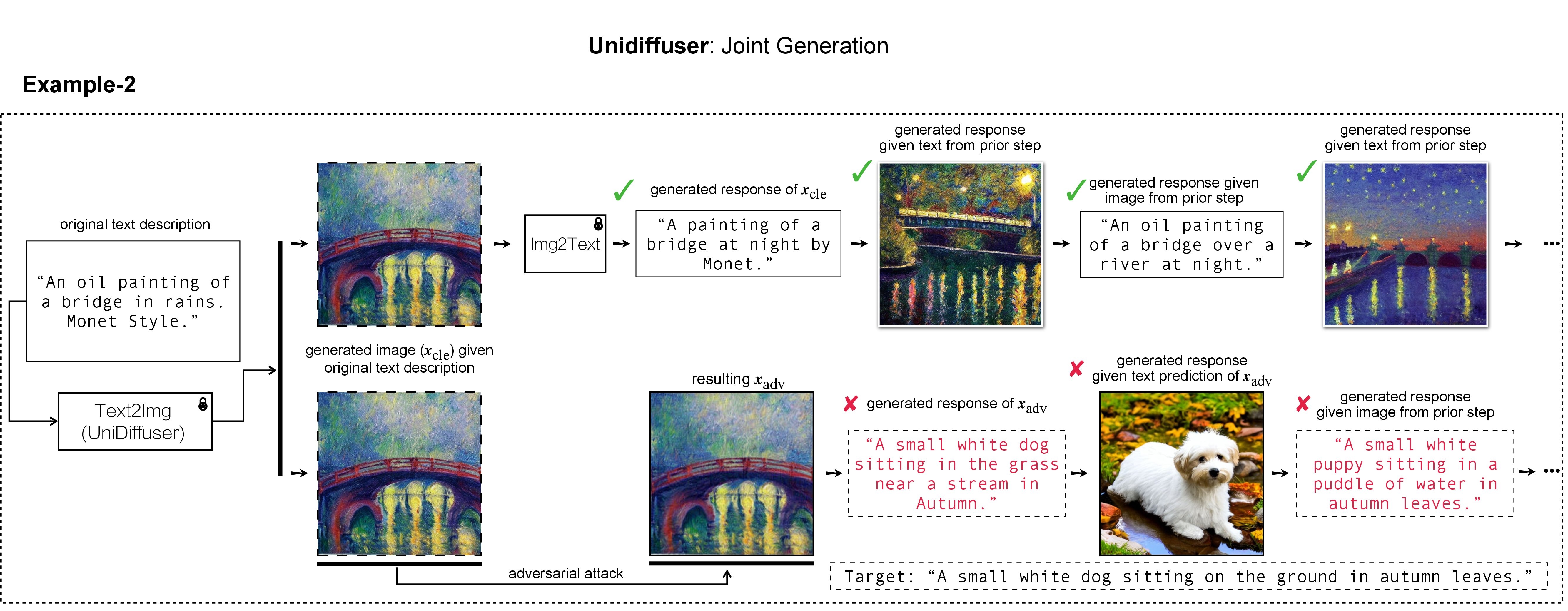
В нашей работе мы использовали DALL-E, Midjourney и Stable Diffusion для генерации и демонстрации целевого изображения. Для крупномасштабных экспериментов мы применяем стабильную диффузию для генерации целевого изображения. Чтобы установить Stable Diffusion, мы инициализируем нашу среду conda, следуя моделям скрытой диффузии. Подходящую базовую среду conda с именем ldm можно создать и активировать с помощью:
conda env create -f environment.yaml
conda activate ldm
Обратите внимание, что для разных моделей жертв мы будем следовать их официальным реализациям и средам conda.
 Как обсуждалось в нашей статье, для достижения гибкой целевой атаки мы используем предварительно обученную модель преобразования текста в изображение для создания целевого изображения с использованием одной подписи в качестве целевого текста. Следовательно, таким образом вы можете сами указать целевой заголовок для атаки!
Как обсуждалось в нашей статье, для достижения гибкой целевой атаки мы используем предварительно обученную модель преобразования текста в изображение для создания целевого изображения с использованием одной подписи в качестве целевого текста. Следовательно, таким образом вы можете сами указать целевой заголовок для атаки!
В наших экспериментах мы используем Stable Diffusion, DALL-E или Midjourney в качестве генераторов текста в изображение. Здесь мы используем Stable Diffusion для демонстрации (спасибо за открытый исходный код!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
затем подготовьте полные целевые подписи из MS-COCO или загрузите нашу обработанную и очищенную версию:
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
и переместите его в ./stable-diffusion/ . В экспериментах можно случайным образом выбрать подмножество подписей COCO (например, 10 , 100 , 1K , 10K , 50K ) для состязательной атаки. Например, предположим, что мы случайным образом выбрали 10K подписей COCO в качестве целевого текста c_tar и сохранили их в следующем файле:
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
Целевые изображения h_ξ(c_tar) можно получить с помощью Stable Diffusion, прочитав текстовую подсказку из выборочных подписей COCO с помощью сценария ниже и txt2img_coco.py (пожалуйста, переместите txt2img_coco.py в ./stable-diffusion/ , обратите внимание, что гиперпараметры могут быть корректируется по вашему желанию):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
где ckpt предоставляется Stable Diffusion v1 и может быть загружен здесь: sd-v1-4-full-ema.ckpt.
Дополнительные подробности реализации преобразования текста в изображение с помощью Stable Diffusion можно найти ЗДЕСЬ.
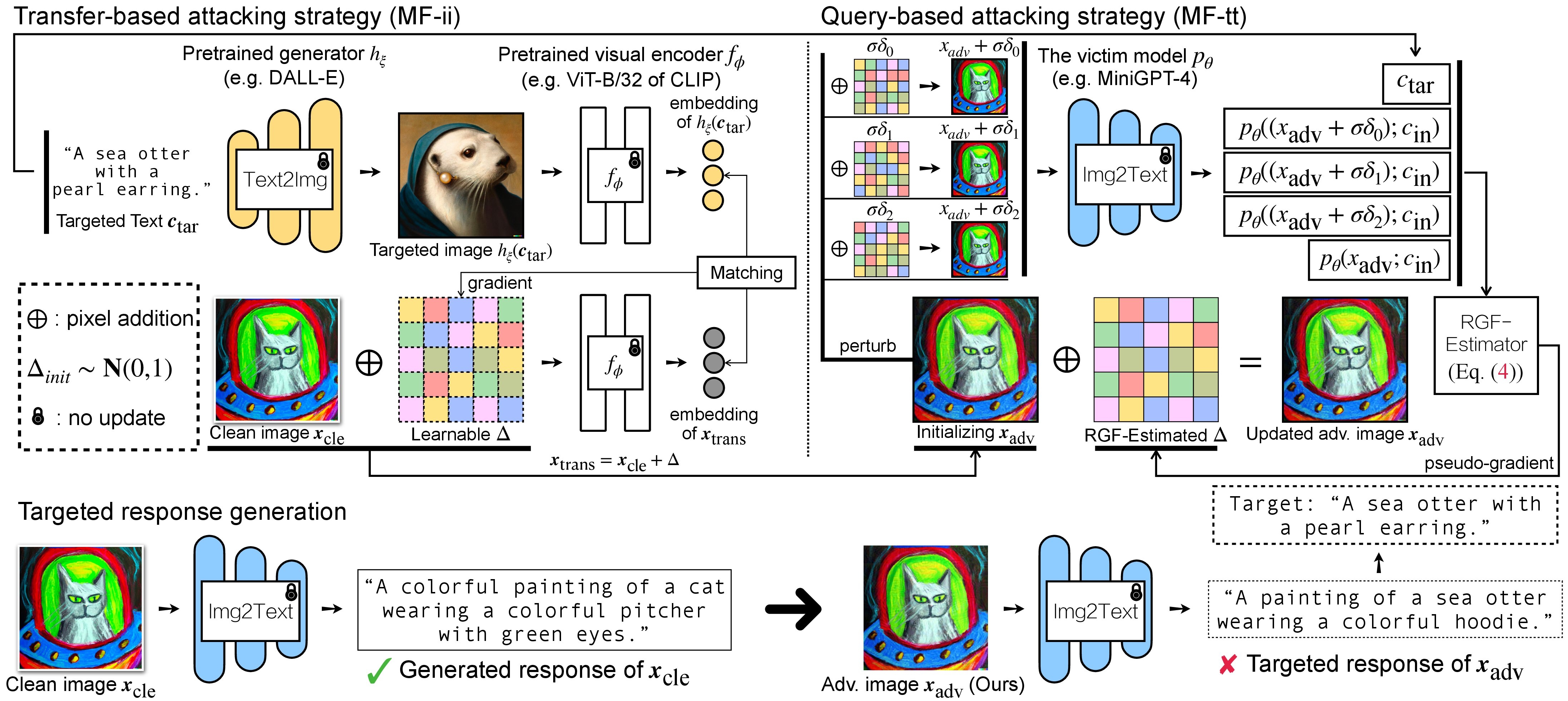
Существует два этапа состязательной атаки на VLM: (1) стратегия атаки на основе передачи и (2) стратегия атаки на основе запросов с использованием (1) в качестве инициализации. Для моделей BLIP/BLIP-2/Img2Prompt см. ./LAVIS_tool . Здесь мы используем Unidiffuser для примера.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
затем создайте подходящую среду conda с именем unidiffuser следуя инструкциям ЗДЕСЬ, и подготовьте соответствующие веса модели (мы используем uvit_v1.pth в качестве веса U-ViT).
conda activate unidiffuser
bash _train_adv_img_trans.sh
созданные рекламные изображения x_trans будут храниться в dir of white-box transfer images указанных в --output . Затем мы выполняем преобразование изображения в текст и сохраняем сгенерированный ответ x_trans. Этого можно достичь путем:
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
где сгенерированные ответы будут храниться в dir of white-box transfer captions в формате .txt . Мы будем использовать их для оценки псевдоградиента с помощью RGF-оценщика.
MF-ii + MF-tt (например, 8 пикселей). bash _train_trans_and_query_fixed_budget.sh
С другой стороны, если вы хотите провести атаку на основе передачи+запроса с отдельным бюджетом возмущения , мы дополнительно предоставляем скрипт:
bash _train_trans_and_query_more_budget.sh
Здесь мы используем wandb для динамического мониторинга скользящего среднего показателя CLIP (например, RN50, ViT-B/32, ViT-L/14 и т. д.), чтобы оценить сходство между (a) сгенерированным ответом (транс/ изображения запроса) и (б) предопределенный целевой текст c_tar .
Пример показан ниже, где пунктирная линия обозначает скользящее среднее показателя CLIP (подписей к изображениям) после запроса: 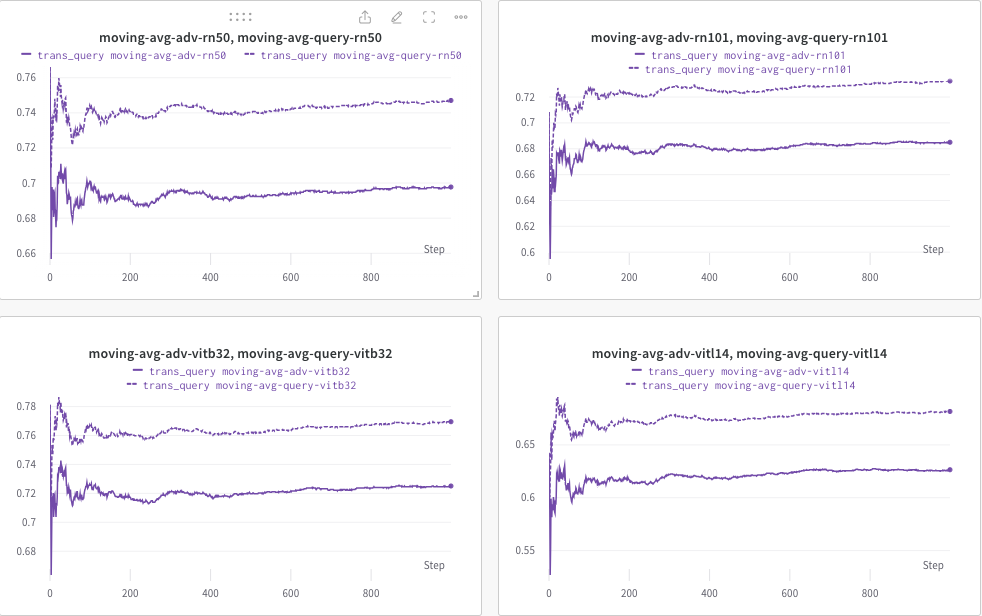
При этом подпись к изображению после запроса будет сохранена, а каталог можно указать с помощью --output .
Если вы найдете этот проект полезным для ваших исследований, пожалуйста, процитируйте нашу статью:
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
Между тем, соответствующее исследование, направленное на встраивание водяного знака в (мультимодальные) модели диффузии:
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
Мы ценим прекрасную базовую реализацию MiniGPT-4, LLaVA, Unidiffuser, LAVIS и CLIP. Мы также благодарим @MetaAI за открытие исходного кода своих контрольных точек LLaMA. Мы благодарим SiSi за предоставление приятных и визуально приятных изображений, созданных @Midjourney для нашего исследования.


