SDV
v1.17.2 - 2024-11-18
Этот репозиторий является частью проекта Synthetic Data Vault Project от DataCebo.



Synthetic Data Vault (SDV) — это библиотека Python, предназначенная для универсального создания табличных синтетических данных. SDV использует различные алгоритмы машинного обучения для изучения закономерностей на основе реальных данных и их эмуляции в синтетических данных.
? Создавайте синтетические данные с помощью машинного обучения. SDV предлагает множество моделей: от классических статистических методов (GaussianCopula) до методов глубокого обучения (CTGAN). Генерируйте данные для отдельных таблиц, нескольких связанных таблиц или последовательных таблиц.
Оценивайте и визуализируйте данные. Сравните синтетические данные с реальными данными по различным показателям. Диагностируйте проблемы и создавайте отчеты о качестве, чтобы получить более подробную информацию.
Предварительная обработка, анонимизация и определение ограничений. Управляйте обработкой данных, чтобы улучшить качество синтетических данных, выбирайте различные типы анонимизации и определяйте бизнес-правила в виде логических ограничений.
| Важные ссылки | |
|---|---|
 Учебники Учебники | Получите практический опыт работы с SDV. Запустите учебные блокноты и запустите код самостоятельно. |
| Документы | Узнайте, как использовать библиотеку SDV, с помощью руководств пользователя и справочников по API. |
| ? Блог | Получите больше информации об использовании SDV, развертывании моделей и нашем сообществе по синтетическим данным. |
 Сообщество Сообщество | Присоединяйтесь к нашему рабочему пространству Slack для объявлений и обсуждений. |
| Веб-сайт | Посетите веб-сайт SDV для получения дополнительной информации о проекте. |
SDV общедоступен по лицензии Business Source. Установите SDV с помощью pip или conda. Мы рекомендуем использовать виртуальную среду, чтобы избежать конфликтов с другим программным обеспечением на вашем устройстве.
pip install sdvconda install -c pytorch -c conda-forge sdvЗагрузите демонстрационный набор данных, чтобы начать. Этот набор данных представляет собой единую таблицу, описывающую гостей, остановившихся в вымышленном отеле.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )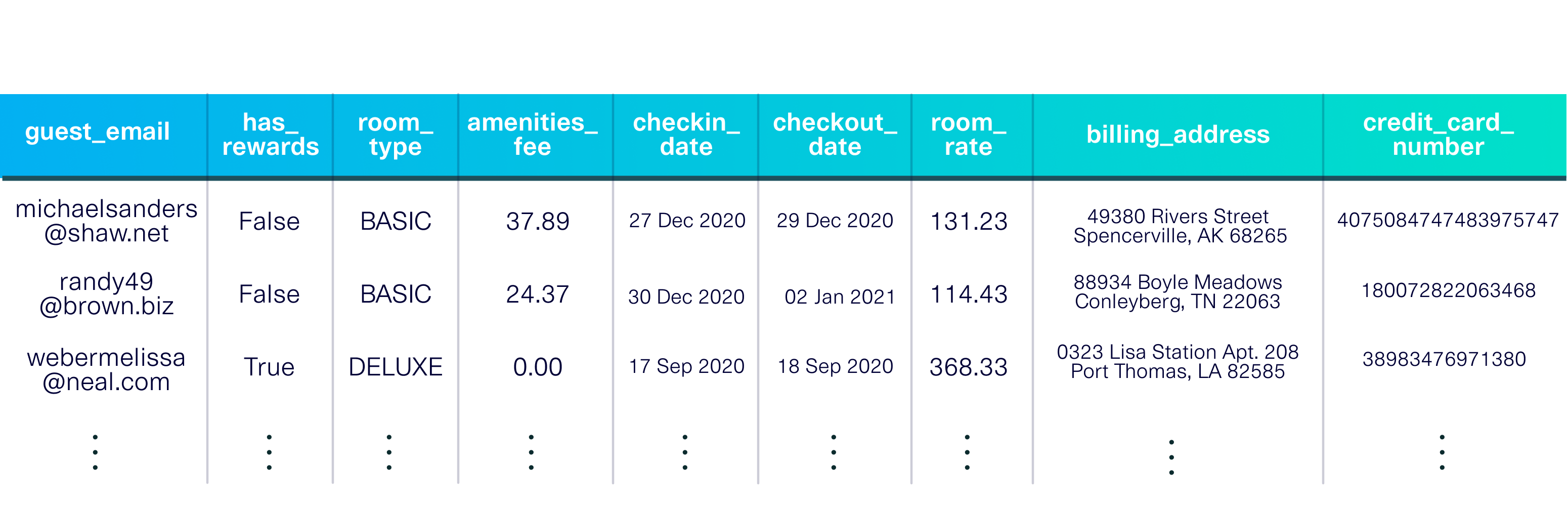
Демо-версия также включает метаданные , описание набора данных, включая типы данных в каждом столбце и первичный ключ ( guest_email ).
Далее мы можем создать синтезатор SDV — объект, который можно использовать для создания синтетических данных. Он изучает закономерности на основе реальных данных и воспроизводит их для создания синтетических данных. Давайте воспользуемся синтезатором GaussianCopulaSynthesizer.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )И теперь синтезатор готов создавать синтетические данные!
synthetic_data = synthesizer . sample ( num_rows = 500 )Синтетические данные будут иметь следующие свойства:
Библиотека SDV позволяет оценивать синтетические данные, сравнивая их с реальными данными. Начните с создания отчета о качестве.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
Этот объект вычисляет общий показатель качества по шкале от 0 до 100 % (100 — лучший показатель), а также детализированную разбивку. Для получения дополнительной информации вы также можете визуализировать синтетические и реальные данные.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()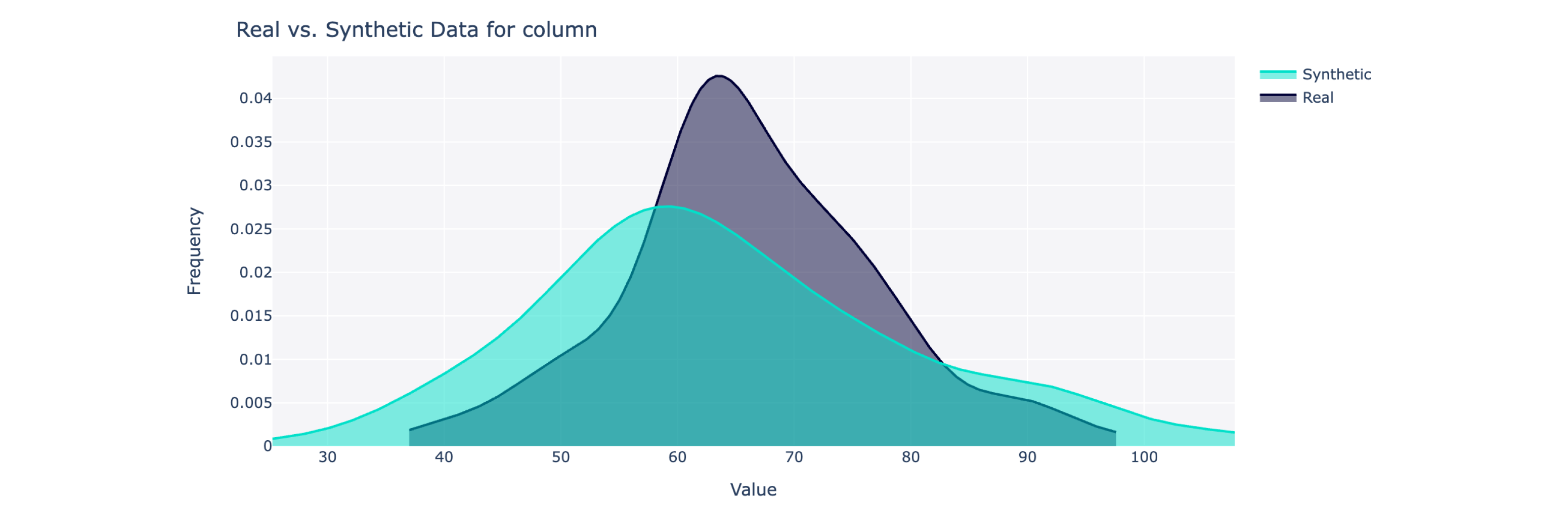
Используя библиотеку SDV, вы можете синтезировать одну таблицу, несколько таблиц и последовательные данные. Вы также можете настроить полный рабочий процесс с синтетическими данными, включая предварительную обработку, анонимизацию и добавление ограничений.
Чтобы узнать больше, посетите демо-страницу SDV.
Спасибо нашей команде участников, которые на протяжении многих лет создавали и поддерживали экосистему SDV!
Просмотреть участников
Если вы используете SDV для своих исследований, пожалуйста, дайте ссылку на следующую статью:
Неха Патки, Рой Ведж, Калян Вирамачанени . Синтетическое хранилище данных. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
Проект Synthetic Data Vault был впервые создан в лаборатории Data to AI Lab Массачусетского технологического института в 2016 году. После 4 лет исследований и сотрудничества с предприятием мы создали DataCebo в 2020 году с целью развития проекта. Сегодня DataCebo является гордым разработчиком SDV, крупнейшей экосистемы для создания и оценки синтетических данных. Здесь находится множество библиотек, поддерживающих синтетические данные, в том числе:
Начните использовать пакет SDV — полностью интегрированное решение и универсальный магазин синтетических данных. Или используйте автономные библиотеки для конкретных нужд.


