LipGER
Initial Release
Это официальная реализация нашей статьи LipGER: визуально обусловленная генеративная коррекция ошибок для надежного автоматического распознавания речи на выставке InterSpeech 2024, которая выбрана для устной презентации .
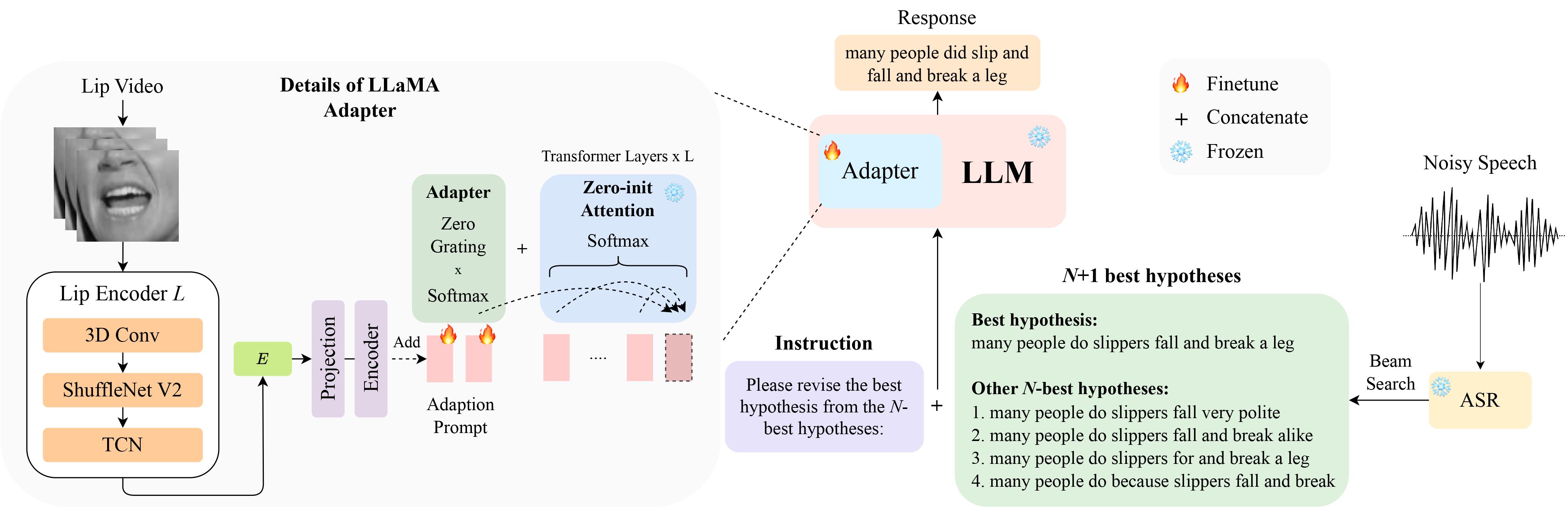
Вы можете скачать данные LipHyp здесь!
pip install -r requirements.txt
Сначала подготовьте контрольно-пропускные пункты, используя:
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hfЧтобы просмотреть все доступные контрольные точки, запустите:
python scripts/download.py | grep Llama-2За более подробной информацией вы также можете обратиться по этой ссылке, где также можно подготовить другие КПП для других моделей. В частности, для наших экспериментов мы используем TinyLlama.
КПП доступен здесь. После загрузки измените здесь путь к контрольной точке.
LipGER ожидает, что все файлы train, val и test будут в формате sample_data.json. Экземпляр в файле выглядит так:
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
Вам необходимо передать речевые файлы через обученную модель ASR, способную генерировать N-лучших гипотез. В этом репозитории мы предлагаем 2 способа, которые помогут вам добиться этого. Не стесняйтесь использовать другие методы.
pip install whisper , а затем запустите nhyps.py из папки data , все будет хорошо! Обратите внимание, что для обоих методов первая в списке — это лучшая гипотеза, а остальные — N-лучшие гипотезы (они передаются как поле списка nhyps_base JSON и используются для создания подсказки на следующих шагах).
Кроме того, предоставленные методы используют в качестве входных данных только речь. Для генерации аудиовизуальных N-лучших гипотез мы использовали Auto-AVSR. Если вам нужна помощь с кодом, пожалуйста, поднимите вопрос!
Предполагая, что у вас есть соответствующие видео для всех ваших речевых файлов, выполните следующие действия, чтобы обрезать рентабельность инвестиций в рот из видео.
python crop_mouth_script.py
python covert_lip.py
Это преобразует ROI mp4 в hdf5, код изменит путь ROI mp4 на ROI hdf5 в том же файле JSON. Вы можете выбрать детекторы «mediapipe» и «retinaface», изменив «детектор» в default.yaml.
Получив N-лучших гипотез, создайте файл JSON в нужном формате. Мы не предоставляем конкретный код для этой части, поскольку подготовка данных может отличаться для всех, но код должен быть простым. Опять же, поднимите вопрос, если у вас есть какие-либо сомнения!
Сценарии обучения LipGER не используют JSON для обучения или оценки. Вам необходимо преобразовать их в pt-файл. Для этого вы можете запустить Convert_to_pt.py! Измените model_name по своему желанию в строке 27 и добавьте путь к вашему JSON в строке 58.
Чтобы настроить LipGER, просто запустите:
sh finetune.sh
где вам нужно вручную установить значения для data (с именем набора данных), --train_path и --val_path (с абсолютными путями для обучения и действительными файлами .pt).
Для вывода сначала измените соответствующие пути в Lipger.py ( exp_path и checkpoint_dir ), а затем запустите (с соответствующим аргументом пути к тестовым данным):
sh infer.sh
Код для обрезки рентабельности инвестиций в рот основан на Visual_Speech_Recognition_for_Multiple_Languages.
Наш код для LipGER основан на RobustGER. Пожалуйста, процитируйте их статью, если вы найдете нашу статью или код полезными.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


