./imagesDockerfile , включив в него ваши двоичные файлы.f()TUPLE_CODECS
docker build -t image_compression_comparison .
docker run -it -v $(pwd):/image_compression_comparison image_compression_comparison
python3 script_compress_parallel.py
Выполняется кодирование, ориентированное на определенные значения метрик, и результаты сохраняются в соответствующих файлах базы данных, например:
main(metric='ssim', target_arr=[0.92, 0.95, 0.97, 0.99], target_tol=0.005, db_file_name='encoding_results_ssim.db')main(metric='vmaf', target_arr=[75, 80, 85, 90, 95], target_tol=0.5, db_file_name='encoding_results_vmaf.db')
compression_results_[PID]_[TIMESTAMP].txtcompression_results_worker_[PID]_[TIMESTAMP].txt В файлах базы данных sqlite3, например, encoding_results_vmaf.db encoding_results_ssim.db .
Процентные ставки BD можно вычислить с помощью сценария compute_BD_rates.py . Скрипт принимает один аргумент:
python3 compute_BD_rates.py [db file name]
и печатает значения для BD Rate VMAF , BD Rate SSIM , BDRate MS_SSIM , BDRate VIF , BDRate PSNR_Y и BDRate PSNR_AVG для каждого исходного изображения, а также среднее значение для исходного набора данных. Ставки BD печатаются как для 420 , так и для 444 подвыборки. PSNR_AVG получается из MSE_AVG , который представляет собой взвешенную MSE по всем цветовым компонентам, взвешенную в соответствии с количеством выборок в соответствующих цветовых компонентах.
Также в комплект поставки входит скрипт analyze_encoding_results.py , который
Скрипт принимает два аргумента:
python3 analyze_encoding_results.py [metric_name like vmaf OR ssim] [db file name]
Следует отметить, что ставка BD представляет собой одно агрегированное число по всему диапазону целевых качеств. Глядя только на скорость BD, можно упустить определенную информацию, например, как сравнивается эффективность сжатия, скажем, для конкретной рабочей точки VMAF = 95?
Другой пример: скажем, уровень BD равен нулю. Вполне возможно, что кривые скорости и качества пересекаются, и один кодек значительно лучше другого, скажем, в рабочей точке VMAF=95, и хуже в области более низкого битрейта.
В идеале, когда ресурсы изображения кодируются для использования в пользовательском интерфейсе, желательно иметь четко определенное рабочее качество, например VMAF=95. И, возможно, результаты из региона более низкого качества могут быть несущественными. Понимание, описанное в (b), таким образом, дополняет «общее» понимание, обеспечиваемое уровнем BD.
Количество одновременных рабочих процессов можно указать в
pool = multiprocessing.Pool(processes=4, initializer=initialize_worker)
Учитывая систему, в которой вы работаете, разумный параллелизм может быть ограничен количеством ядер процессора или объемом доступной оперативной памяти по сравнению с памятью, потребляемой наиболее требовательным процессом кодирования в ансамбле тестируемых кодеков. Например, если экземпляр encoder_A обычно потребляет 5 ГБ ОЗУ, а у вас общий объем ОЗУ 32 ГБ, тогда разумный параллелизм может быть ограничен до 6 (32/5), даже если у вас 24 (или больше 6) ядер процессора.
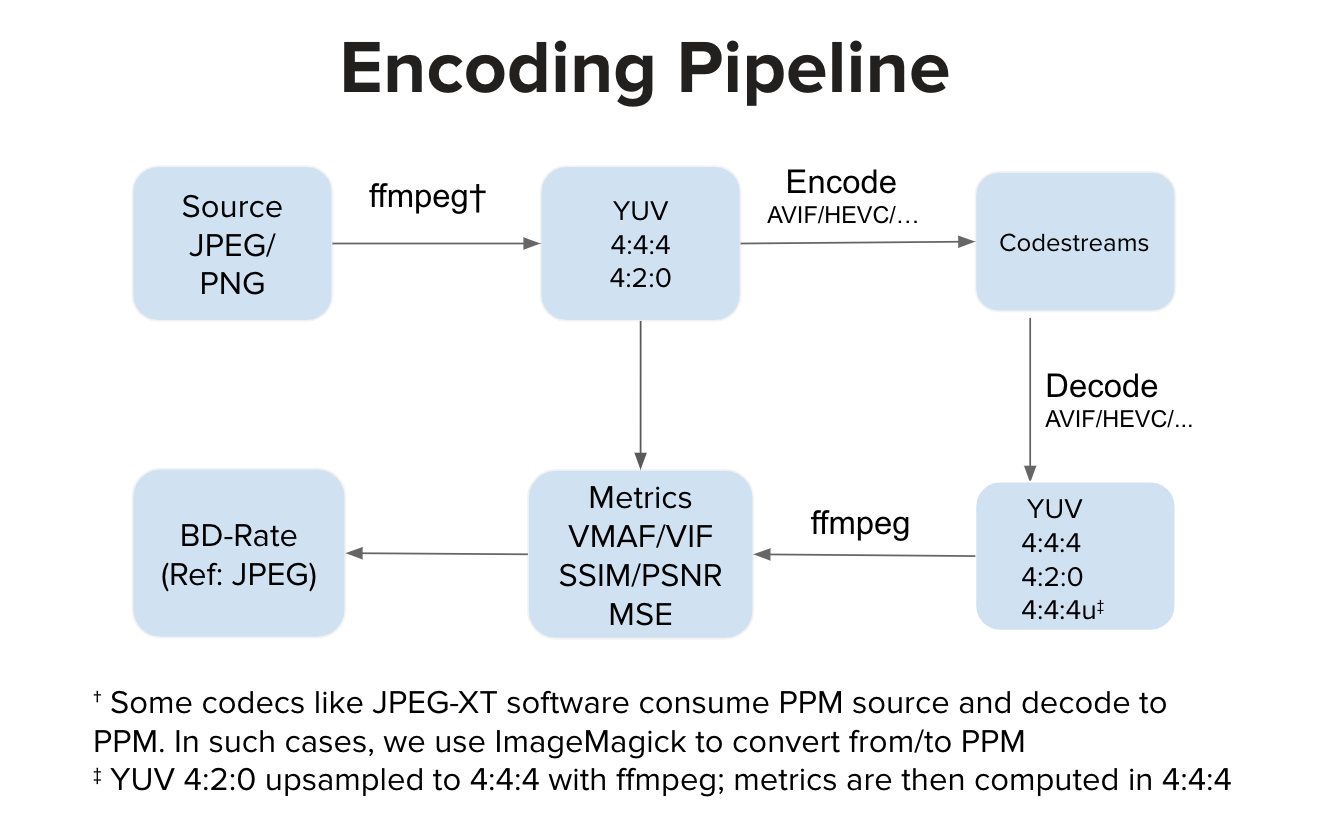
В идеале реализация кодера потребляет входные данные YUV и генерирует кодовый поток. В идеале реализация декодера потребляет кодовый поток и декодирует его в выходной формат YUV. Затем мы вычисляем метрики в пространстве YUV. Однако существуют реализации, такие как программное обеспечение JPEG-XT, которые потребляют входной сигнал PPM и производят выходной сигнал PPM. В таких случаях перед вычислением качества в пространстве YUV может быть преобразование исходного PPM в YUV, а также декодированное преобразование PPM в YUV. Дополнительные шаги преобразования по сравнению с обычным конвейером могут внести небольшие искажения, но в наших экспериментах эти шаги не оказывают заметного влияния на оценку VMAF.