[Бумага] [Страница проекта] [Модель miniFLUX] [Модель SD3 ⚡️] [демо ?]
Это официальный репозиторий Pyramid Flow, эффективного для обучения метода авторегрессионной генерации видео, основанного на Flow Matching . Обучаясь только на наборах данных с открытым исходным кодом , он может генерировать высококачественные 10-секундные видеоролики с разрешением 768p и частотой 24 кадра в секунду и, естественно, поддерживает генерацию изображения в видео.
| 10 с, 768p, 24 кадра в секунду | 5 с, 768p, 24 кадра в секунду | Преобразование изображения в видео |
|---|---|---|
фейерверк.mp4 | трейлер.mp4 | воскресенье.mp4 |
2024.11.13 Выпускаем КПП miniFLUX 768p (до 10с).
Мы переключили структуру модели с SD3 на mini FLUX, чтобы исправить проблемы со структурой человека. Попробуйте нашу контрольную точку изображения 1024p, контрольную точку видео 384p (до 5 с) и контрольную точку видео 768p (до 10 с). Новая модель miniflux демонстрирует значительное улучшение структуры человека и стабильности движений.
2024.10.29 ⚡️⚡️⚡️ Мы выпускаем обучающий код для VAE, код тонкой настройки для DiT и новые контрольные точки модели со структурой FLUX, обученной с нуля.
2024.10.13 Поддерживаются вывод нескольких графических процессоров и разгрузка ЦП. Используйте его с менее чем 8 ГБ памяти графического процессора с большим ускорением на нескольких графических процессорах.
2024.10.11 ??? Доступна демо-версия Hugging Face. Спасибо @multimodalart за участие!
2024.10.10 Мы публикуем технический отчет, страницу проекта и контрольную точку модели Pyramid Flow.
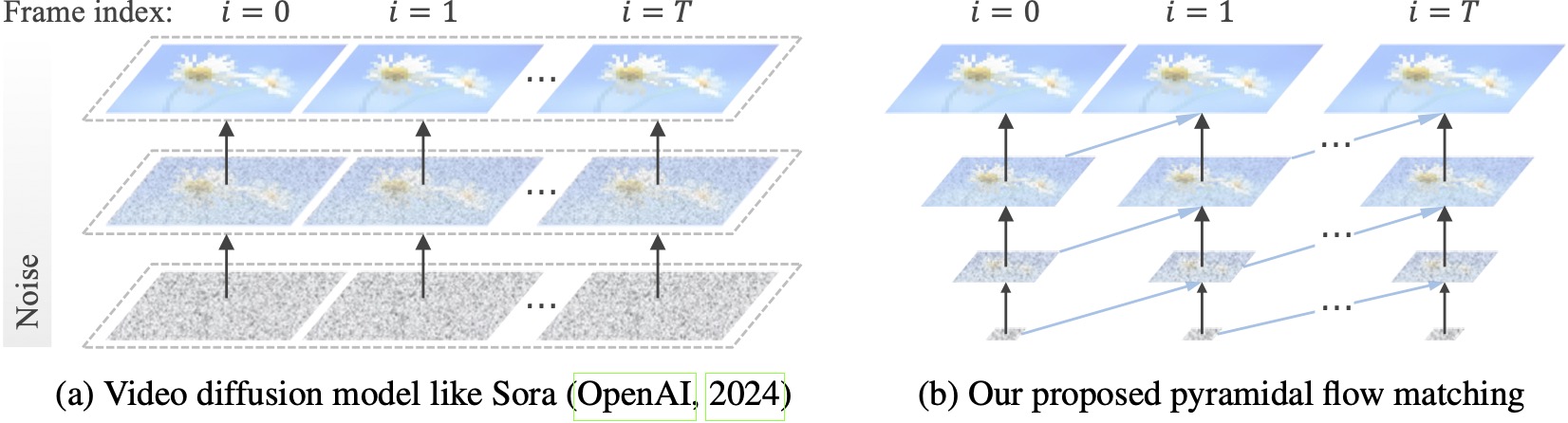
Существующие модели распространения видео работают с полным разрешением, тратя много вычислений на очень шумные латентные характеристики. Напротив, наш метод использует гибкость согласования потоков (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023) для интерполяции между латентными значениями различного разрешения и уровнями шума, что позволяет одновременно генерировать и декомпрессия визуального контента с большей вычислительной эффективностью. Вся платформа полностью оптимизирована с помощью одного DiT (Peebles & Xie, 2023), генерирующего высококачественные 10-секундные видеоролики с разрешением 768p и частотой 24 кадра в секунду в течение 20,7 тыс. часов обучения графического процессора A100.
Мы рекомендуем настроить среду с помощью conda. В настоящее время в базе кода используются Python 3.8.10 и PyTorch 2.1.2 (руководство), и мы активно работаем над поддержкой более широкого спектра версий.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtЗатем загрузите модель с Huggingface (есть два варианта: miniFLUX или SD3). Модели miniFLUX поддерживают создание изображений 1024p, видео 384p и 768p, а модели на базе SD3 поддерживают создание видео 768p и 384p. Контрольная точка 384p генерирует 5-секундное видео со скоростью 24 кадра в секунду, а контрольная точка 768p генерирует до 10 секунд видео со скоростью 24 кадра в секунду.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )Чтобы начать, сначала установите Gradio, укажите путь к модели #L36, а затем запустите на локальном компьютере:
python app.pyДемо-версия Gradio откроется в браузере. Благодаря @tpc2233 за коммит, подробности см. в #48.
Или попробуйте это без особых усилий на Hugging Face Space? создано @multimodalart. Из-за ограничений графического процессора эта онлайн-демо может генерировать только 25 кадров (экспорт со скоростью 8 или 24 кадра в секунду). Дублируйте пространство, чтобы создавать более длинные видео.
Чтобы быстро опробовать Pyramid Flow в Google Colab, запустите приведенный ниже код:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
Чтобы использовать нашу модель, следуйте коду вывода в video_generation_demo.ipynb по этой ссылке. Мы настоятельно рекомендуем вам попробовать последнюю опубликованную пирамиду-минифлюс, которая демонстрирует значительное улучшение структуры человека и стабильности движений. Установите для параметра model_name значение pyramid_flux , чтобы использовать его. Мы еще больше упростим его до следующей двухэтапной процедуры. Сначала загрузите скачанную модель:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()Затем вы можете попробовать преобразовать текст в видео по собственным подсказкам. Обратите внимание, что версия 384p теперь поддерживает только 5 с (установите температуру до 16)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )Будучи авторегрессионной моделью, наша модель также поддерживает (с текстовым условием) генерацию изображения в видео:
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )Мы также поддерживаем два типа разгрузки ЦП, чтобы снизить требования к памяти графического процессора. Обратите внимание, что они могут принести в жертву эффективность.
cpu_offloading=True в функцию генерации позволяет делать выводы при объеме памяти графического процессора менее 12 ГБ . Эту функцию предоставил @Ednaordinary, подробности см. в № 23.model.enable_sequential_cpu_offload() перед вышеуказанной процедурой позволяет сделать вывод при объеме памяти графического процессора менее 8 ГБ . Эту функцию предоставил @rodjjo, подробности см. в №75. Благодаря @niw пользователи Apple Silicon (например, MacBook Pro с M2 24 ГБ) также могут опробовать нашу модель, используя серверную часть MPS! Подробности см. в № 113.
Для пользователей с несколькими графическими процессорами мы предоставляем сценарий вывода, который использует параллелизм последовательностей для экономии памяти на каждом графическом процессоре. Это также обеспечивает значительное ускорение: создание видео 5 с, 768p и 24 кадров в секунду занимает всего 2,5 минуты на 4 графических процессорах A100 (по сравнению с 5,5 минутами на одном графическом процессоре A100). Запустите его на двух графических процессорах с помощью следующей команды:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shВ настоящее время он поддерживает 2 или 4 графических процессора (для версии SD3), при этом в исходном сценарии доступны дополнительные конфигурации. Вы также можете запустить демонстрационную версию Gradio с несколькими графическими процессорами, созданную @tpc2233, подробности см. в #59.
Спойлер: мы даже не использовали параллелизм последовательностей при обучении благодаря нашей эффективной конструкции пирамидального потока.
guidance_scale управляет качеством изображения. Мы предлагаем использовать рекомендации из [7, 9] для контрольной точки 768p во время генерации текста в видео и 7 для контрольной точки 384p.video_guidance_scale управляет движением. Большее значение увеличивает степень динамики и смягчает деградацию авторегрессионной генерации, а меньшее значение стабилизирует видео.Требования к оборудованию для обучения VAE — не менее 8 графических процессоров A100. Пожалуйста, обратитесь к этому документу. Это MAGVIT-v2, подобный непрерывному 3D VAE, который должен быть достаточно гибким. Не стесняйтесь создавать свою собственную генеративную видеомодель на основе этой части обучающего кода VAE.
Аппаратные требования для точной настройки DiT — не менее 8 графических процессоров A100. Пожалуйста, обратитесь к этому документу. Мы предоставляем инструкции как для авторегрессионной, так и для неавторегрессионной версии Pyramid Flow. Первый более ориентирован на исследования, а второй более стабилен (но менее эффективен без темпоральной пирамиды).
Следующие примеры видео создаются со скоростью 5 с, 768p, 24 кадра в секунду. Для получения дополнительных результатов посетите страницу нашего проекта.
Токио.mp4 | эйфель.mp4 |
волны.mp4 | рельс.mp4 |
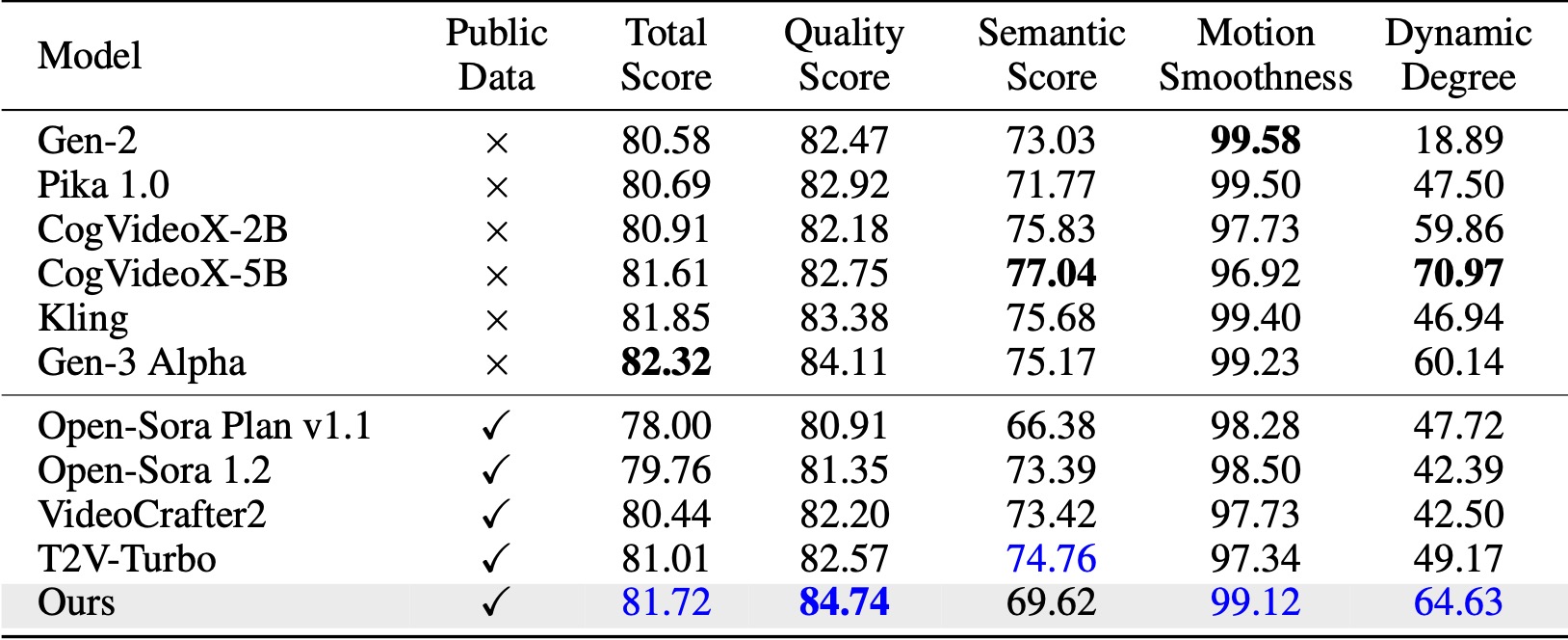
На VBench (Хуанг и др., 2024) наш метод превосходит все сравниваемые базовые версии с открытым исходным кодом. Даже при использовании только общедоступных видеоданных он достигает производительности, сравнимой с такими коммерческими моделями, как Kling (Kuaishou, 2024) и Gen-3 Alpha (Runway, 2024), особенно по показателю качества (84,74 против 84,11 у Gen-3) и плавности движения. .
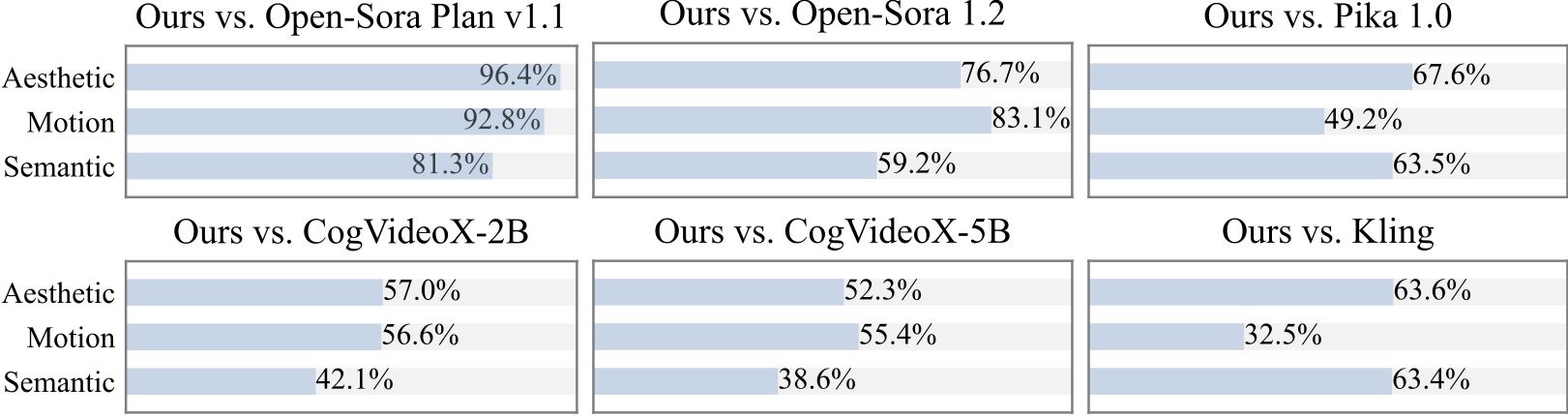
Мы проводим дополнительное исследование пользователей с участием 20+ участников. Как можно видеть, наш метод предпочтительнее моделей с открытым исходным кодом, таких как Open-Sora и CogVideoX-2B, особенно с точки зрения плавности движения.
Мы благодарны за следующие замечательные проекты при внедрении Pyramid Flow:
Подумайте о том, чтобы дать этому репозиторию звезду и ссылаться на Pyramid Flow в своих публикациях, если это поможет вашим исследованиям.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


