nim anywhere
1.0.0

Пожалуйста, присоединяйтесь к каналу Slack #cdd-nim-anywhere, если вы являетесь внутренним пользователем. Если вы внешний пользователь, откройте проблему, чтобы задать вопросы и оставить отзыв.
Одним из основных преимуществ использования ИИ для предприятий является возможность работать со своими внутренними данными и учиться на их основе. Поисково-дополненная генерация (RAG) — один из лучших способов сделать это. NVIDIA разработала набор микросервисов под названием NIM microservice, чтобы помочь нашим партнерам и клиентам с легкостью построить эффективный конвейер RAG.
NIM Anywhere содержит все инструменты, необходимые для интеграции NIM с RAG. Он изначально масштабируется до полноразмерных лабораторий и до производственных сред. Это отличная новость для построения архитектуры RAG и легкого добавления NIM по мере необходимости. Если вы не знакомы с RAG, он динамически извлекает соответствующую внешнюю информацию во время вывода, не изменяя саму модель. Представьте, что вы технический руководитель компании с локальной базой данных, содержащей конфиденциальную и актуальную информацию. Вы не хотите, чтобы OpenAI имел доступ к вашим данным, но вам нужна модель, чтобы понимать их и точно отвечать на вопросы. Решение состоит в том, чтобы подключить вашу языковую модель к базе данных и передать им информацию.
Чтобы узнать больше о том, почему RAG является отличным решением для повышения точности и надежности ваших генеративных моделей ИИ, прочитайте этот блог.
Начните работу с NIM Anywhere прямо сейчас, воспользовавшись краткими инструкциями, и создайте свое первое приложение RAG с использованием NIM!
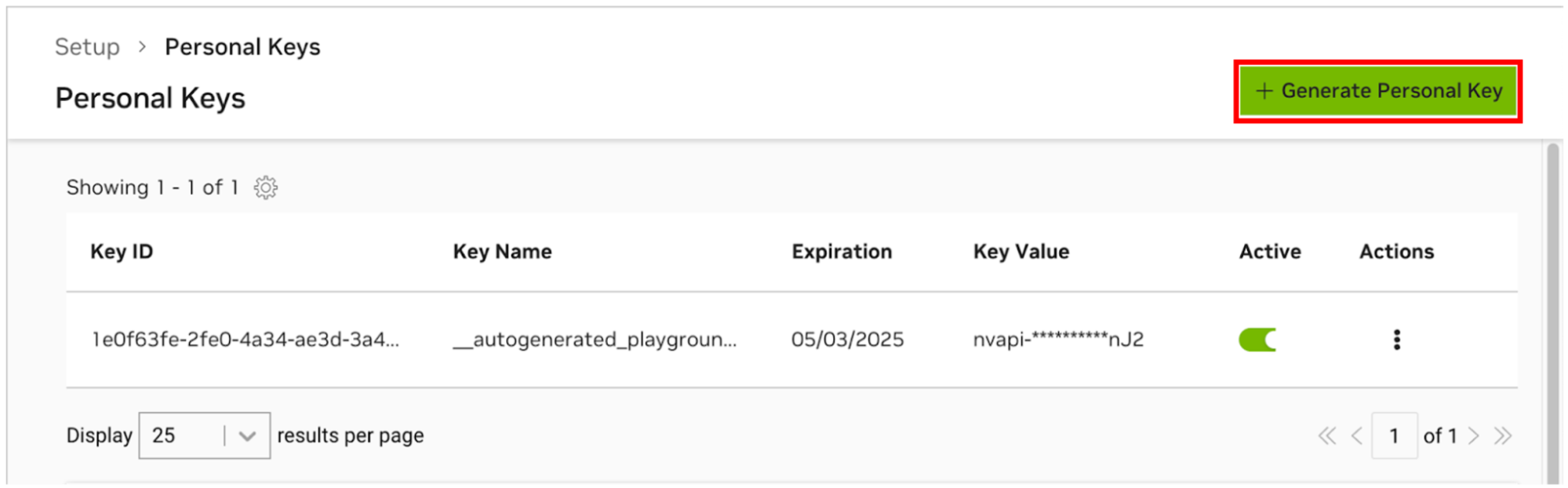
Чтобы предоставить AI Workbench доступ к облачным ресурсам NVIDIA, вам необходимо предоставить ему личный ключ. Эти ключи начинаются с nvapi- .
Перейдите в Диспетчер личных ключей NGC. Если вам будет предложено это сделать, зарегистрируйте новую учетную запись и войдите в систему.
СОВЕТ. Вы можете найти этот инструмент, войдя на ngc.nvidia.com, развернув меню своего профиля в правом верхнем углу, выбрав «Настройка» , а затем выбрав «Создать личный ключ» .
Выберите «Создать личный ключ» .
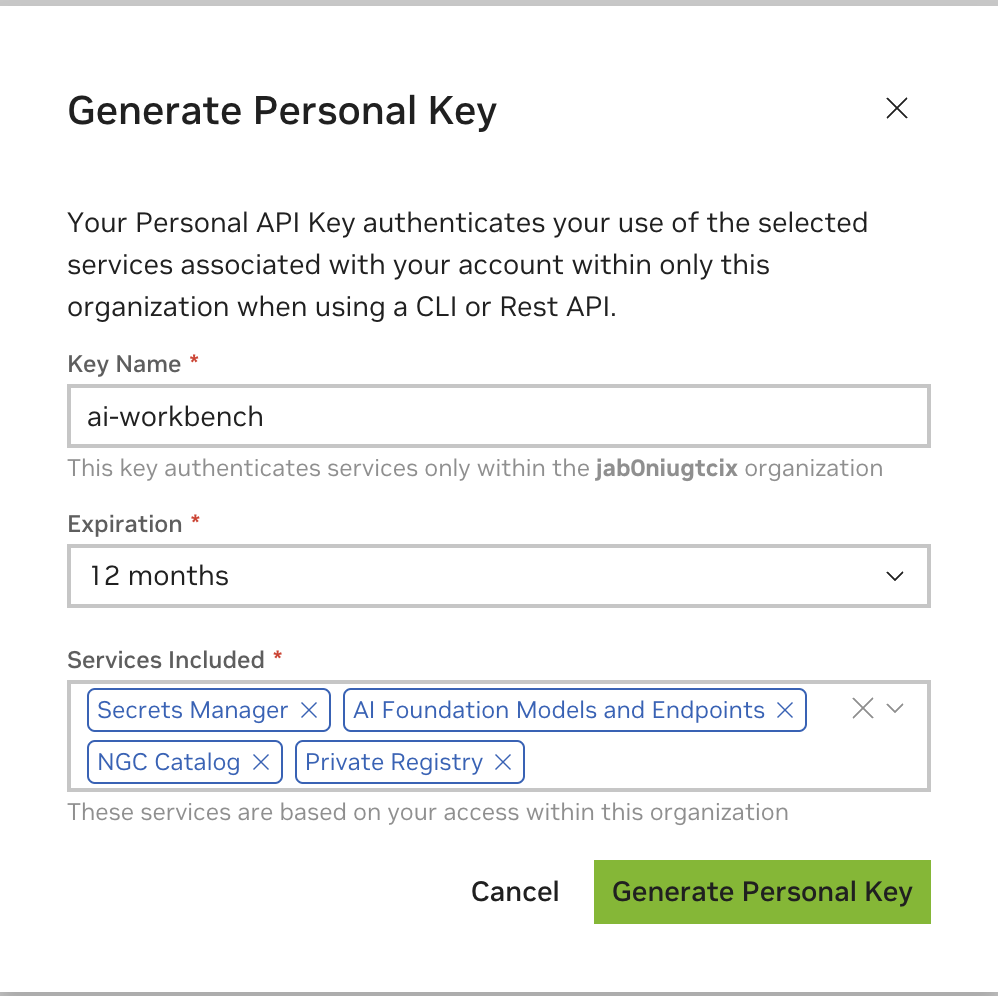
Введите любое значение в качестве имени ключа, срок действия 12 месяцев подойдет, и выберите все услуги. Когда закончите, нажмите «Создать личный ключ» .
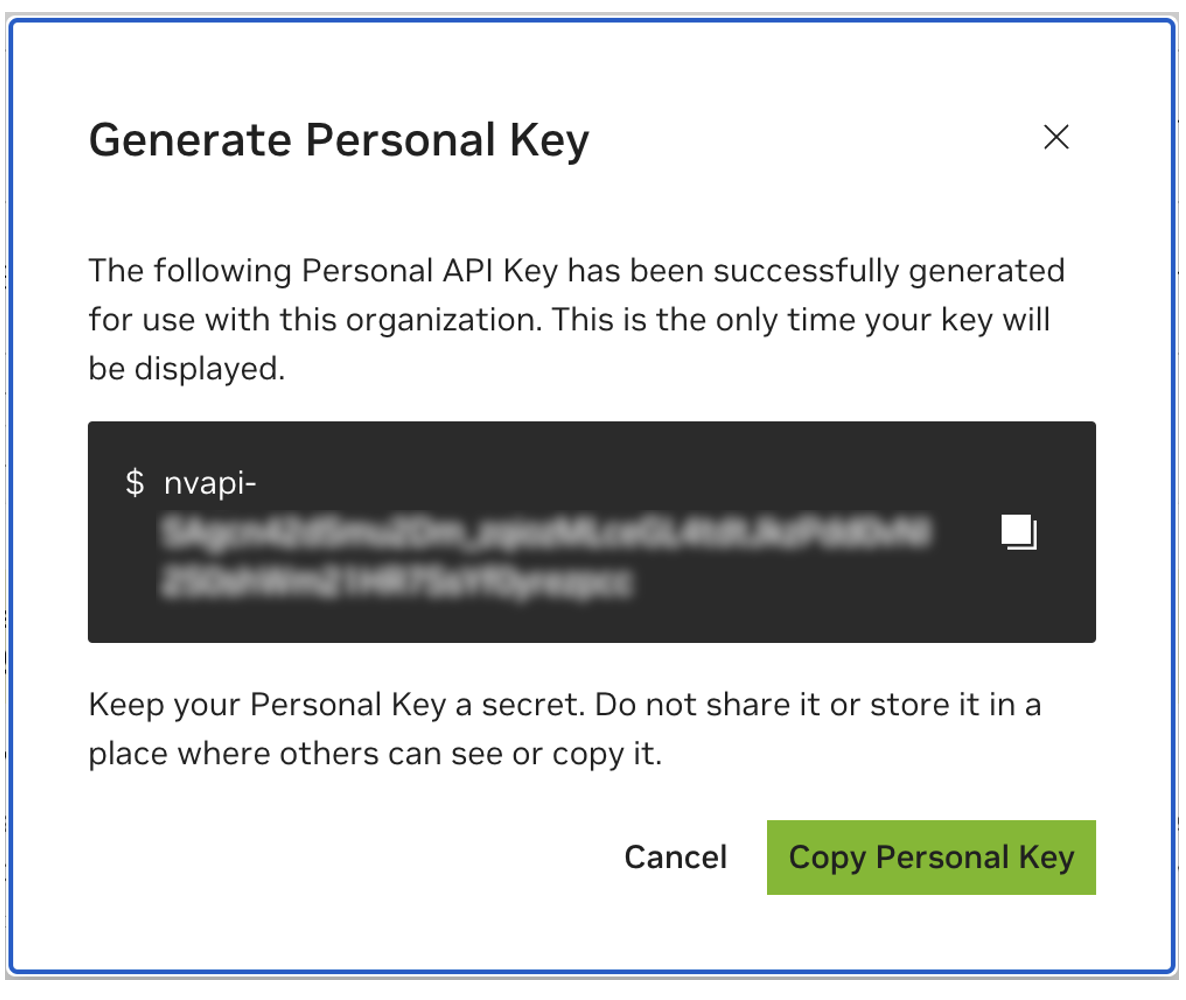
Сохраните свой личный ключ на будущее. Он понадобится Workbench, и позже его невозможно будет получить. Если ключ утерян, необходимо создать новый. Защитите этот ключ, как если бы это был пароль.
Этот проект предназначен для использования с NVIDIA AI Workbench. Хотя это не является обязательным требованием, запуск этой демонстрации без AI Workbench потребует ручной работы, поскольку предварительно настроенные средства автоматизации и интеграции могут быть недоступны.
В этом кратком руководстве предполагается, что для разработки используется удаленная лабораторная машина, а локальная машина представляет собой тонкий клиент для удаленного доступа к машине разработки. Это позволяет вычислительным ресурсам оставаться централизованными, а разработчикам — более портативными. Обратите внимание: на удаленном лабораторном компьютере должна работать Ubuntu, а на локальном клиенте может работать Windows, MacOS или Ubuntu. Чтобы установить этот проект только локально, просто пропустите удаленную установку.
блок-схема LR
местный
лабораторная среда подграфа
удаленная лабораторная машина
конец
локальный <-.ssh.-> удаленная-лабораторная машина
Ubuntu требуется, если локальный клиент также будет использоваться для разработки. При использовании удаленного лабораторного компьютера это может быть Windows, MacOS или Ubuntu.
Полные инструкции см. в Руководстве пользователя NVIDIA AI Workbench.
Установите необходимое программное обеспечение
Загрузите установщик NVIDIA AI Workbench и запустите его. Авторизуйте Windows, чтобы позволить установщику вносить изменения.
Следуйте инструкциям мастера установки. Если вам нужно установить WSL2, разрешите Windows внести изменения и перезагрузите локальный компьютер по запросу. После перезапуска системы работа установщика NVIDIA AI Workbench должна возобновиться автоматически.
Выберите Docker в качестве среды выполнения контейнера.
Войдите в свою учетную запись GitHub, используя опцию «Войти через GitHub.com» .
Введите информацию об авторе git, если потребуется.
Полные инструкции см. в Руководстве пользователя NVIDIA AI Workbench.
Установите необходимое программное обеспечение
Загрузите образ диска NVIDIA AI Workbench (файл .dmg ) и откройте его.
Перетащите AI Workbench в папку «Приложения» и запустите NVIDIA AI Workbench из панели запуска приложений. 
Выберите Docker в качестве среды выполнения контейнера.
Войдите в свою учетную запись GitHub, используя опцию «Войти через GitHub.com» .
Введите информацию об авторе git, если потребуется.
Полные инструкции см. в Руководстве пользователя NVIDIA AI Workbench. Запустите эту установку от имени пользователя, который будет пользователем Workbench. Не выполняйте эти шаги от имени root .
Установите необходимое программное обеспечение
Загрузите установщик NVIDIA AI Workbench, сделайте его исполняемым и запустите. Вы можете сделать файл исполняемым с помощью следующей команды:
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench установит для вас драйверы NVIDIA (при необходимости). После установки драйверов вам потребуется перезагрузить локальный компьютер, а затем перезапустить установку AI Workbench, дважды щелкнув значок NVIDIA AI Workbench на рабочем столе.
Выберите Docker в качестве среды выполнения контейнера.
Войдите в свою учетную запись GitHub, используя опцию «Войти через GitHub.com» .
Введите информацию об авторе git, если потребуется.
Для удаленных компьютеров поддерживается только Ubuntu.
Полные инструкции см. в Руководстве пользователя NVIDIA AI Workbench. Запустите эту установку от имени пользователя, который будет использовать Workbench. Не выполняйте эти шаги от имени root .
Убедитесь, что аутентификация на основе ключа SSH включена при переходе с локального компьютера на удаленный компьютер. Если это в настоящее время не включено, следующие команды позволят включить это в большинстве ситуаций. Измените REMOTE_USER и REMOTE-MACHINE , чтобы отразить ваш удаленный адрес.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINESSH на удаленный хост. Затем используйте следующие команды для загрузки и запуска установщика NVIDIA AI Workbench.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench установит для вас драйверы NVIDIA (при необходимости). Вам потребуется перезагрузить удаленный компьютер после установки драйверов, а затем перезапустить установку AI Workbench, повторно выполнив команды на предыдущем шаге.
Выберите Docker в качестве среды выполнения контейнера.
Войдите в свою учетную запись GitHub, используя опцию «Войти через GitHub.com» .
Введите информацию об авторе git, если потребуется.
После завершения удаленной установки удаленное местоположение можно добавить в локальный экземпляр AI Workbench. Откройте приложение AI Workbench, нажмите «Добавить удаленное местоположение» , а затем введите необходимую информацию. По завершении нажмите «Добавить местоположение» .
REMOTE-MACHINE .REMOTE_USER ./home/USER/.ssh/id_rsa .Есть два способа загрузить этот проект для локального использования: клонирование и разветвление.
Клонирование этого репозитория — рекомендуемый способ начать. Это не позволит вносить локальные изменения, но позволит быстрее начать работу. Это также позволяет упростить получение обновлений.
Для разработки рекомендуется создать форк этого репозитория, поскольку изменения можно будет сохранить. Однако для получения обновлений сопровождающему форка придется регулярно получать обновления из восходящего репозитория. Чтобы работать с форком, следуйте инструкциям GitHub, а затем укажите URL-адрес своего личного форка в оставшейся части этого раздела.
Откройте локальное окно NVIDIA AI Workbench. Из отображаемого списка местоположений выберите либо удаленное, которое вы только что настроили, либо локальное, если вы собираетесь работать локально.
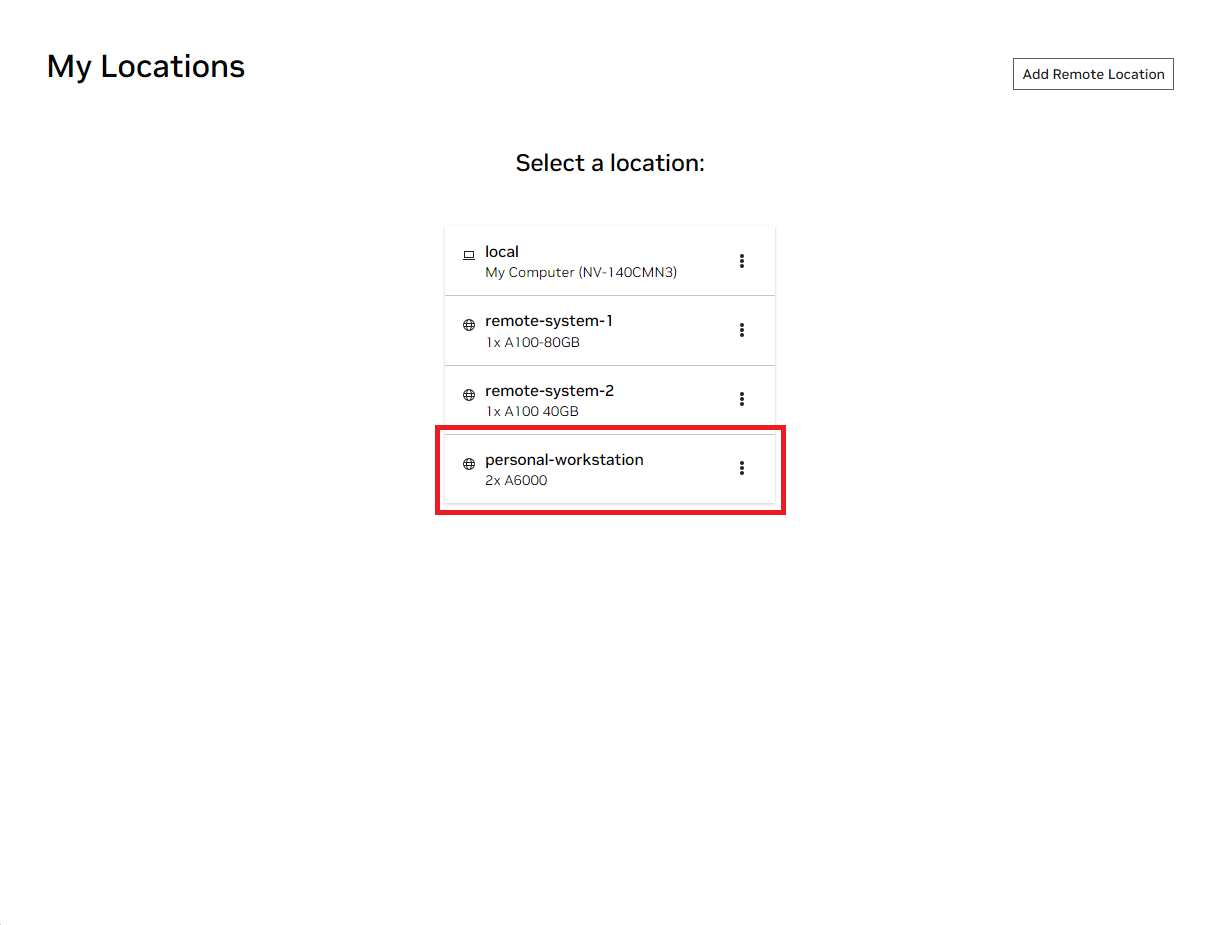
Оказавшись внутри локации, выберите «Клонировать проект» .
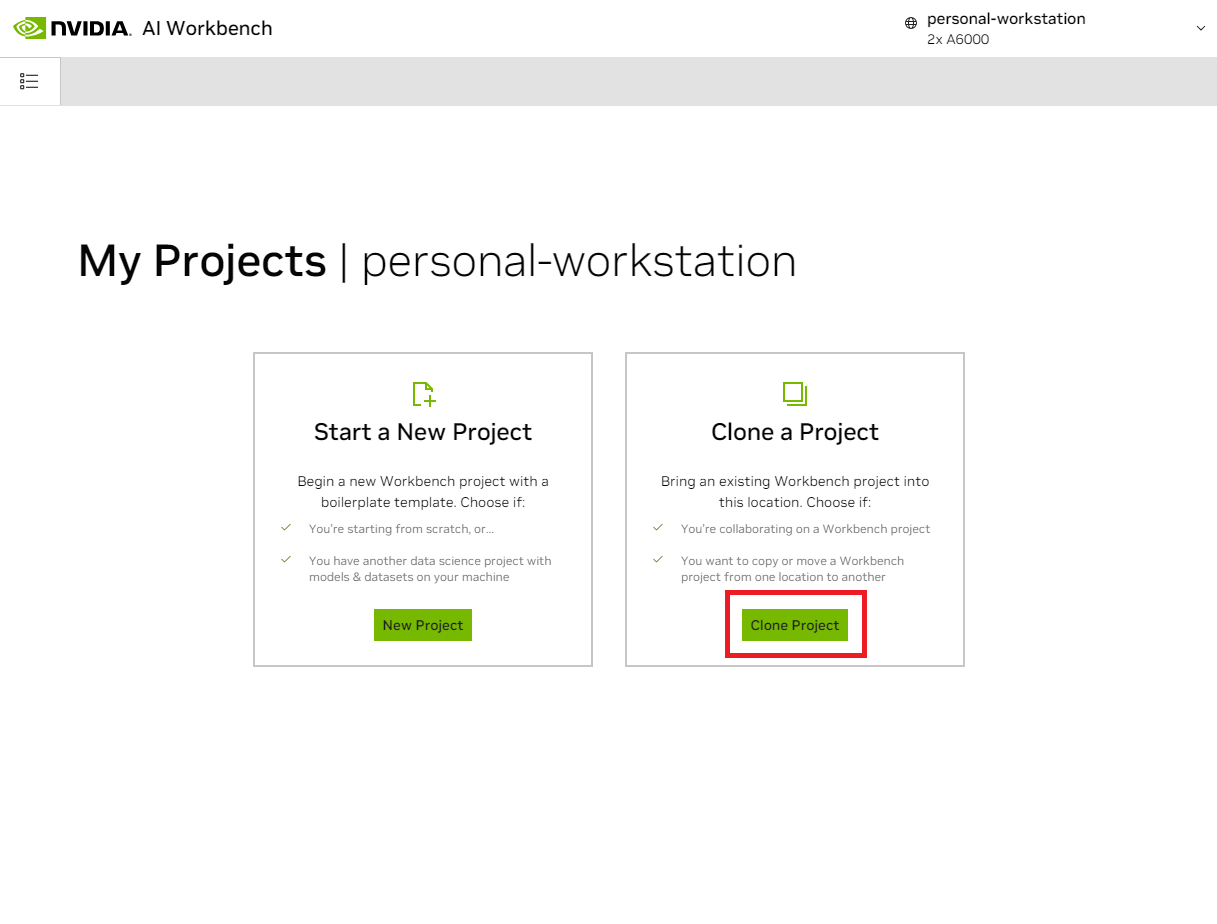
Во всплывающем окне «Клонировать проект» установите URL-адрес репозитория https://github.com/NVIDIA/nim-anywhere.git . Вы можете оставить путь по умолчанию /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git . Нажмите «Клонировать ».
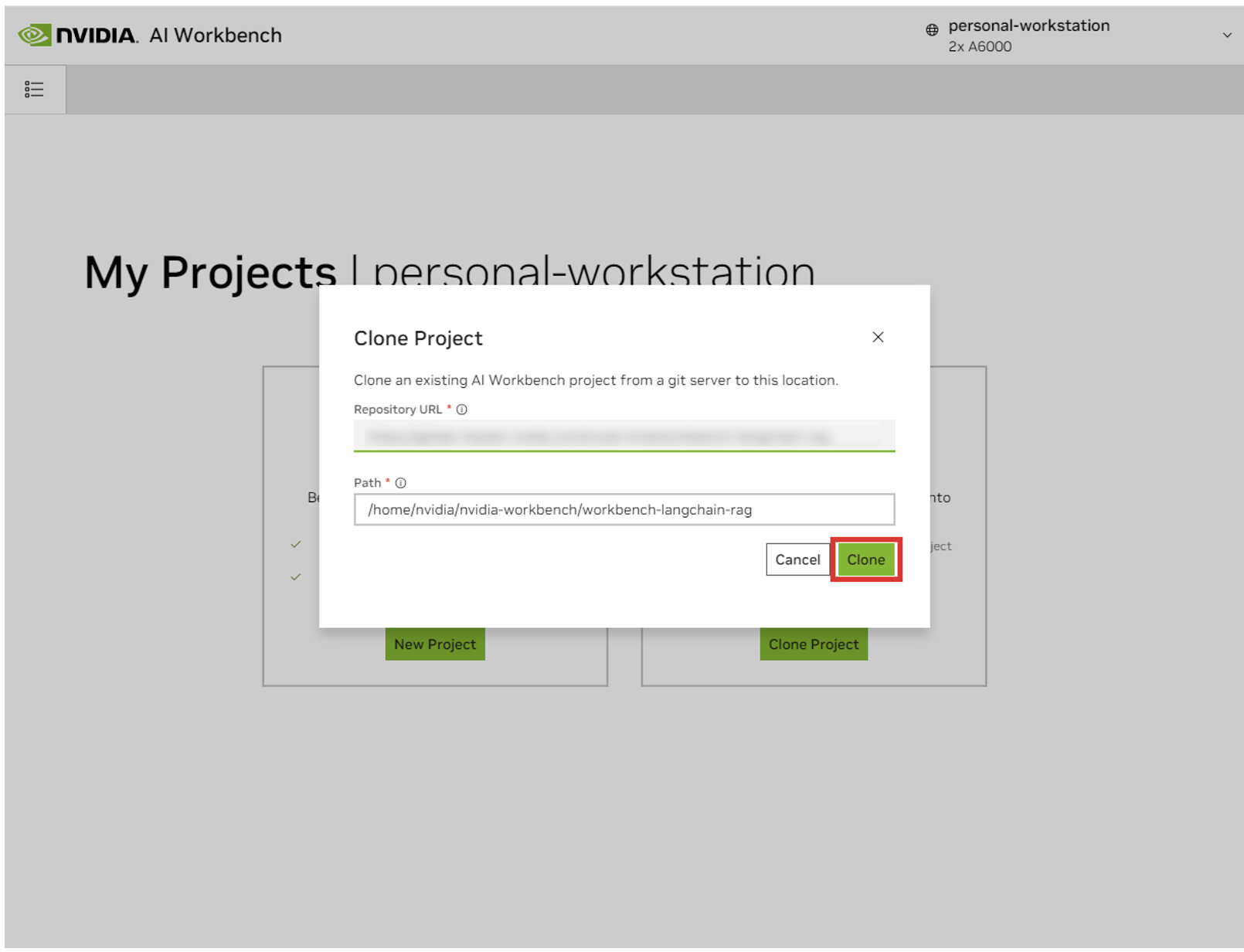
Вы будете перенаправлены на страницу нового проекта. Workbench автоматически загрузит среду разработки. Вы можете просмотреть прогресс в реальном времени, развернув вывод в нижней части окна.
Проект должен быть настроен для работы с локальными машинными ресурсами.
Перед первым запуском необходимо предоставить конкретную конфигурацию проекта. Конфигурация проекта выполняется с помощью вкладки «Среда» на левой панели.
Прокрутите вниз до раздела «Переменные» и найдите запись NGC_HOME . Должно быть установлено что-то вроде ~/.cache/nvidia-nims . Значение здесь используется рабочей средой. Это же местоположение также отображается в разделе «Маунты» , который монтирует этот каталог в контейнер.
Прокрутите вниз до раздела «Секреты» и найдите запись NGC_API_KEY . Нажмите «Настроить» и укажите личный ключ для NGC, сгенерированный ранее.
Прокрутите вниз до раздела «Маунты» . Здесь нужно настроить два крепления.
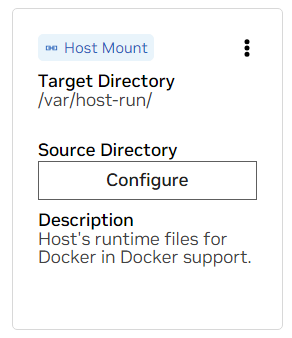
а. Найдите монтирование для /var/host-run. Это используется, чтобы позволить среде разработки получить доступ к демону Docker хоста по шаблону под названием Docker out of Docker. Нажмите «Настроить» и укажите каталог /var/run .
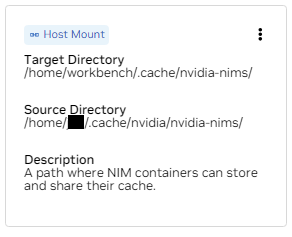
б. Найдите монтирование для /home/workbench/.cache/nvidia-nims. Это монтирование используется в качестве кэша времени выполнения для NIM, где они могут кэшировать файлы моделей. Совместное использование этого кэша с хостом снижает использование диска и пропускную способность сети.
Если у вас еще нет кэша nim или вы не уверены, используйте следующие команды, чтобы создать его в /home/USER/.cache/nvidia-nims .
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsПерестроение произойдет после изменения этих настроек.
Как только сборка завершится сообщением о готовности сборки , все приложения станут вам доступны.
Даже самые простые сети LLM зависят от нескольких дополнительных микросервисов. Их можно игнорировать во время разработки альтернатив в памяти, но тогда для перехода к производству потребуются изменения кода. К счастью, Workbench управляет этими дополнительными микросервисами для сред разработки.
СОВЕТ: Для каждого приложения выходные данные отладки можно отслеживать в пользовательском интерфейсе, щелкнув ссылку «Вывод» в левом нижнем углу, выбрав раскрывающееся меню и выбрав интересующее приложение.
Всеми приложениями, включенными в эту рабочую область, можно управлять, перейдя в раздел «Среда» > «Приложения» .
Сначала включите Milvus Vector DB и Redis . Milvus используется как неструктурированная база знаний, а Redis — для хранения истории разговоров.
После запуска этих служб можно безопасно запустить цепной сервер . Он содержит специальный код LangChain для выполнения нашей цепочки рассуждений. По умолчанию будут использоваться локальные Milvus и Redis, но для вывода моделей LLM и внедрения используется ai.nvidia.com .
[НЕОБЯЗАТЕЛЬНО]: Затем запустите LLM NIM . При первом запуске LLM NIM загрузка образа и оптимизированных моделей займет некоторое время.
а. Во время длительного запуска, чтобы убедиться в запуске LLM NIM, за ходом работы можно следить, просматривая журналы с помощью панели «Вывод» в левом нижнем углу пользовательского интерфейса.
б. Если журналы указывают на ошибку аутентификации, это означает, что предоставленный NGC_API_KEY не имеет доступа к NIM. Убедитесь, что он был сгенерирован правильно и в организации NGC, имеющей поддержку или пробную версию NVIDIA AI Enterprise.
в. Если кажется, что бревна застряли ..........: Pull complete . ..........: Verifying complete или ..........: Download complete ; это обычный вывод Docker о том, что различные слои образа контейнера были загружены.
д. Любые другие неисправности здесь необходимо устранить.
Как только сервер цепочки будет запущен, можно будет запустить интерфейс чата . Запуск интерфейса автоматически откроет его в окне браузера.
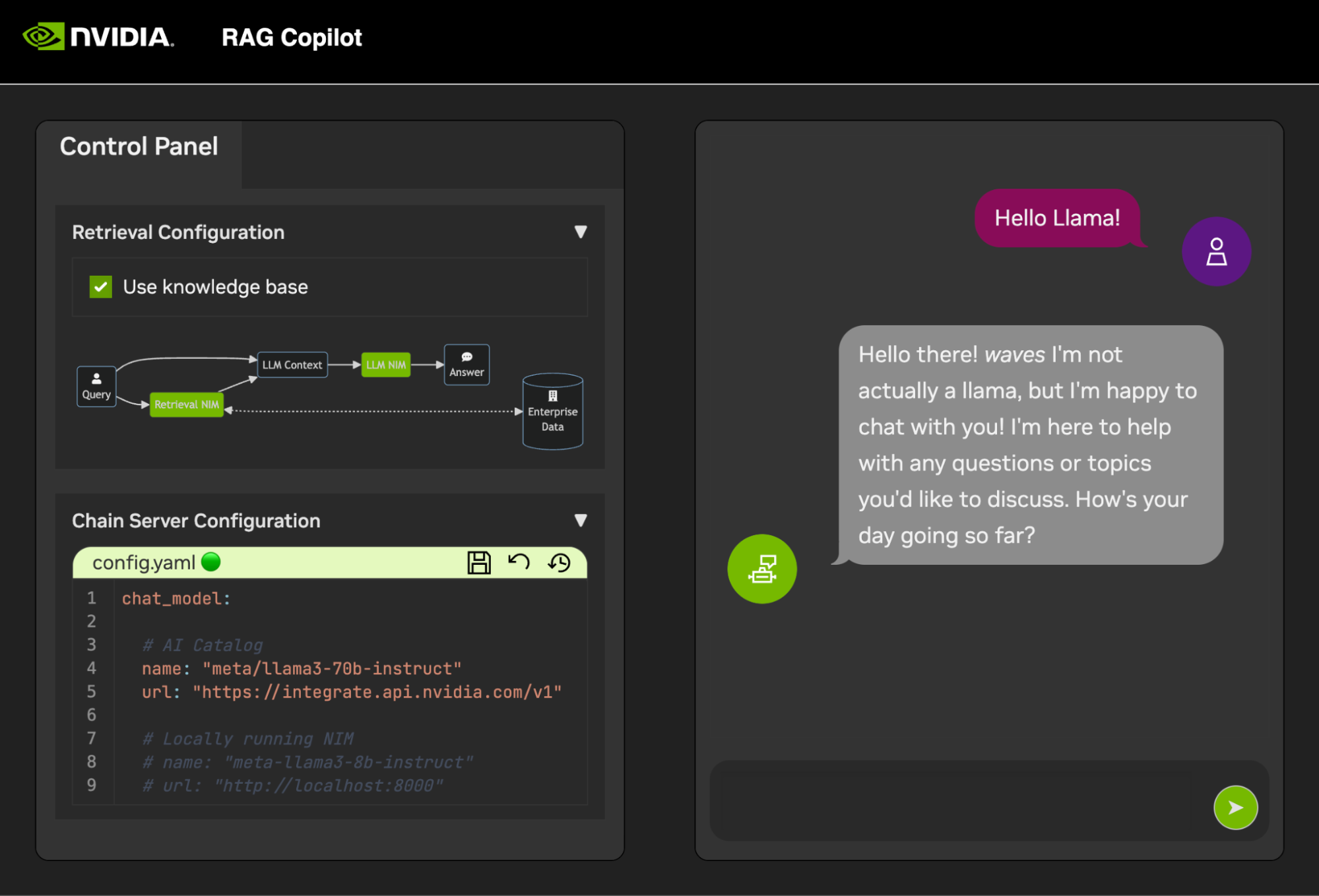
Чтобы приступить к разработке демонстраций, предоставляется образец набора данных вместе с блокнотом Jupyter, показывающим, как данные вводятся в базу данных Vector.
Чтобы импортировать PDF-документацию в базу данных вектора, откройте Jupyter с помощью средства запуска приложений в AI Workbench.
Используйте блокнот Jupyter по адресу code/upload-pdfs.ipynb чтобы принять набор данных по умолчанию. При использовании набора данных по умолчанию никаких изменений не требуется.
Если вы используете собственный набор данных, загрузите его в каталог data/ в Jupyter и при необходимости измените предоставленный блокнот.
Этот проект содержит приложения для нескольких демонстрационных сервисов, а также интеграцию с внешними сервисами. Все это организовано NVIDIA AI Workbench.
Все демонстрационные сервисы находятся в папке code . На корневом уровне папки с кодом находится несколько интерактивных блокнотов, предназначенных для глубокого технического погружения. Chain Server — это пример приложения, использующего NIM с LangChain. (Обратите внимание, что сетевой сервер дает вам возможность экспериментировать с RAG и без него). Папка Chat Frontend содержит сервер интерактивного пользовательского интерфейса для работы сервера цепочки. Наконец, в каталоге оценки представлены образцы блокнотов для демонстрации оценки и проверки поиска.
карта разума
корень ((AI Workbench))
Демонстрационные услуги
Цепной сервер<br />LangChain + NIM
Интерфейс<br />Интерактивный демонстрационный интерфейс
Оценка<br />Подтверждение результатов
Ноутбуки<br />Расширенное использование
Интеграции
Redis</br>История разговоров
Милвус</br>База данных векторов
LLM NIM</br>Оптимизированные LLM
Сервер цепочки можно настроить либо с помощью файла конфигурации, либо с помощью переменных среды.
По умолчанию приложение будет искать файл конфигурации во всех следующих местах. Если обнаружено несколько файлов конфигурации, значения из нижних файлов в списке будут иметь приоритет.
Дополнительный путь к файлу конфигурации можно указать через переменную среды с именем APP_CONFIG . Значение в этом файле будет иметь приоритет над всеми местоположениями файлов по умолчанию.
export APP_CONFIG=/etc/my_config.yaml Конфигурацию также можно задать с помощью переменных среды. Имена переменных будут иметь следующий вид: APP_FIELD__SUB_FIELD Значения, указанные в качестве переменных среды, будут иметь приоритет над всеми значениями из файлов.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
Интерфейс чата также имеет несколько параметров конфигурации. Их можно настроить так же, как и сервер цепочки.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
Все отзывы и вклад в этот проект приветствуются. При внесении изменений в этот проект, как для личного использования, так и для внесения вклада, рекомендуется работать над форком этого проекта. После завершения изменений в форке следует открыть запрос на слияние.
Этот проект был настроен с использованием линтеров, которые были настроены так, чтобы код оставался согласованным, но при этом не был слишком обременительным. Мы используем следующие линтеры:
Встроенная среда VSCode настроена для выполнения анализа и проверки в реальном времени.
Чтобы вручную запустить анализ, выполняемый конвейерами CI, выполните /project/code/tools/lint.sh . Отдельные тесты можно запускать, указав их по имени: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . Запуск инструмента проверки в режиме исправления автоматически исправит все, что он может, запустив Black, обновив README и очистив вывод ячейки на всех ноутбуках Jupyter.
Интерфейс был разработан с целью минимизировать необходимость разработки HTML и Javascript. Предоставляется фирменная и стилизованная оболочка приложения, созданная с использованием стандартного HTML, Javascript и CSS. Он спроектирован таким образом, чтобы его можно было легко настроить, но это никогда не требуется. Все интерактивные компоненты интерфейса создаются в Gradio и монтируются в оболочку приложения с помощью iframe.
В верхней части оболочки приложения находится меню со списком доступных представлений. Каждое представление может иметь собственный макет, состоящий из одной или нескольких страниц.
Страницы содержат интерактивные компоненты для демонстрации. Код страниц находится в каталоге code/frontend/pages . Чтобы создать новую страницу:
__init__.py в новом каталоге, который использует Gradio для определения пользовательского интерфейса. Макет градиентных блоков должен быть определен в переменной с именем page .chat .code/frontend/pages/__init__.py , импортируйте новую страницу и добавьте новую страницу в список __all__ .ПРИМЕЧАНИЕ. Создание новой страницы не приведет к ее добавлению во внешний интерфейс. Его необходимо добавить в представление, чтобы оно появилось во внешнем интерфейсе.
Представления состоят из одной или нескольких страниц и должны функционировать независимо друг от друга. Все представления определены в модуле code/frontend/server.py . Все объявленные представления будут автоматически добавлены в строку меню внешнего интерфейса и станут доступными в пользовательском интерфейсе.
Чтобы определить новое представление, измените список с именем views . Это список объектов View . Порядок объектов будет определять их порядок в меню Frontend. Первое определенное представление будет использоваться по умолчанию.
Объекты представления описывают имя и макет представления. Их можно объявить следующим образом:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) Все объявления страниц View.left или View.right являются необязательными. Если они не объявлены, связанные iframe в веб-макете будут скрыты. Другие iframe расширятся, чтобы заполнить пробелы. На следующих диаграммах показаны различные макеты.
блок-бета
столбцы 1
меню["строка меню"]
блокировать
столбцы 2
слева направо
конец
блок-бета
столбцы 1
меню["строка меню"]
блокировать
столбцы 1
осталось:1
конец
Интерфейс содержит несколько фирменных ресурсов, которые можно настроить для различных вариантов использования.
Интерфейс содержит логотип в левом верхнем углу страницы. Чтобы изменить логотип, требуется SVG нужного логотипа. Оболочку приложения затем можно легко изменить для использования нового SVG, изменив файл code/frontend/_assets/index.html . Существует один div с идентификатором logo . Этот блок содержит один SVG. Обновите это до желаемого определения SVG.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > Стиль оболочки приложения определяется в code/frontend/_static/css/style.css . Цвета в этом файле можно безопасно изменять.
Стилизация различных страниц определяется в code/frontend/pages/*/*.css . Эти файлы также могут потребовать изменения для пользовательских цветовых схем.
Тема Gradio определяется в файле code/frontend/_assets/theme.json . Цвета в этом файле можно безопасно изменить в соответствии с желаемым брендингом. Другие стили в этом файле также могут быть изменены, но это может привести к критическим изменениям во внешнем интерфейсе. Документация Gradio содержит дополнительную информацию о темах Gradio.
ПРИМЕЧАНИЕ. Это сложная тема, которая никогда не понадобится большинству разработчиков.
Иногда может возникнуть необходимость иметь в представлении несколько страниц, которые взаимодействуют друг с другом. Для этой цели используется платформа обмена сообщениями postMessage Javascript. Любое доверенное сообщение, отправленное в оболочку приложения, будет перенаправлено в каждый iframe, где страницы смогут обработать это сообщение по своему усмотрению. Страница control использует эту функцию для изменения конфигурации страницы chat .
Следующее сообщение отправит сообщение в оболочку приложения ( window.top ). Сообщение будет содержать словарь с ключом use_kb и значением true. Используя Gradio, этот Javascript может быть выполнен любым событием Gradio.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; Это сообщение будет автоматически отправлено оболочкой приложения на все страницы. Следующий пример кода будет использовать сообщение на другой странице. Этот код будет выполняться асинхронно при получении события message . Если сообщению доверяют, компонент Gradio с elem_id use_kb будет обновлен до значения, указанного в сообщении. Таким образом, значение компонента Gradio можно дублировать на разных страницах.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; README отображается автоматически; прямые изменения будут перезаписаны. Чтобы изменить README, вам потребуется отредактировать файлы для каждого раздела отдельно. Все эти файлы будут объединены, и файл README будет сгенерирован автоматически. Вы можете найти все связанные файлы в папке docs .
Документация пишется на Github Flavored Markdown, а затем преобразуется в окончательный файл Markdown с помощью Pandoc. Детали этого процесса определены в Makefile. Порядок создаваемых файлов определяется в docs/_TOC.md . Документацию можно просмотреть в окне браузера файлов Workbench.
Заголовочный файл — это первый файл, используемый для компиляции документации. Этот файл можно найти по адресу docs/_HEADER.md . Содержимое этого файла будет записано дословно, без каких-либо манипуляций, в README прежде всего.
Сводный файл содержит краткое описание и графику, описывающую этот проект. Содержимое этого файла будет добавлено в README сразу после заголовка и непосредственно перед оглавлением. Этот файл обрабатывается Pandoc для встраивания изображений перед записью в README.
Самый важный файл документации — это файл оглавления docs/_TOC.md . Этот файл определяет список файлов, которые необходимо объединить для создания окончательного руководства README. Для включения файлы должны находиться в этом списке.
Сохраните весь статический контент, включая изображения, в папке _static . Это поможет в организации.
Может быть полезно иметь документы, которые обновляются и пишутся сами. Чтобы создать динамический документ, просто создайте исполняемый файл, который записывает документ в формате Markdown в стандартный вывод. Во время сборки, если запись в файле оглавления является исполняемой, она будет выполнена, и вместо нее будет использоваться ее стандартный вывод.
Когда отправляется фиксация, связанная с документацией, действие GitHub отображает документацию. Любые изменения в README будут автоматически зафиксированы.
Большая часть настройки среды разработки выполняется с помощью переменных среды. Чтобы внести постоянные изменения в переменные среды, измените variables.env или используйте пользовательский интерфейс Workbench.
В этом проекте используется одна среда Python по адресу /usr/bin/python3 , а зависимости управляются с помощью pip . Поскольку вся разработка выполняется внутри контейнера, любые изменения в среде Python будут эфемерными. Чтобы установить пакет Python навсегда, добавьте его в файл requirements.txt или используйте пользовательский интерфейс Workbench.
Среда разработки основана на Ubuntu 22.04. Основной пользователь имеет доступ к sudo без пароля, но все изменения в системе будут эфемерными. Чтобы внести постоянные изменения в установленные пакеты, добавьте их в файл [ apt.txt ]. Вносить другие изменения в операционную систему, например манипулировать файлами, добавлять переменные среды и т. д.; используйте файлы postBuild.bash и preBuild.bash .
Обычно хорошей практикой является ежемесячное обновление зависимостей, чтобы гарантировать отсутствие CVE из-за неправильного использования зависимостей. Следующий процесс можно использовать для исправления этого проекта. Рекомендуется запустить регрессионное тестирование после установки патча, чтобы убедиться, что в обновлении ничего не сломалось.
/project/code/tools/bump.sh ./project/code/tools/audit.sh . Этот скрипт распечатает отчет обо всех пакетах Python в состоянии предупреждения и обо всех пакетах в состоянии ошибки. Все, что находится в состоянии ошибки, должно быть устранено, поскольку оно будет иметь активные CVE и известные уязвимости.

