Facebook Messenger Bot
1.0.0
Чат-бот FB Messenger, которого я научил говорить, как я. Соответствующее сообщение в блоге.
Для этого проекта я хотел обучить модель Sequence To Sequence на основе моих прошлых журналов разговоров с различных сайтов социальных сетей. Вы можете прочитать больше о мотивации этого подхода, подробностях модели машинного обучения и назначении каждого скрипта Python в сообщении блога, но я хочу использовать этот README, чтобы объяснить, как вы можете научить своего собственного чат-бота говорить так, как вы. .
Для запуска этих сценариев вам потребуются следующие библиотеки.
Загрузите и разархивируйте весь этот репозиторий с GitHub либо в интерактивном режиме, либо введя следующую команду в своем терминале.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitПерейдите в верхний каталог репозитория на вашем компьютере.
cd Facebook-Messenger-BotНаша первая задача — загрузить все данные ваших разговоров с различных сайтов социальных сетей. Я использовал Facebook, Google Hangouts и LinkedIn. Если у вас есть другие сайты, с которых вы получаете данные, это нормально. Вам просто нужно будет создать новый метод в createDataset.py.
Данные Facebook : Загрузите свои данные отсюда. После загрузки у вас должен получиться довольно большой файл messages.htm . Это будет довольно большой файл (для меня более 190 МБ). Нам нужно будет проанализировать этот большой файл и извлечь все разговоры. Для этого мы воспользуемся инструментом, исходный код которого Диллон Диксон любезно предоставил. Вы продолжите установку этого инструмента, запустив
pip install fbchat-archive-parserа затем работает:
fbcap ./messages.htm > fbMessages.txtЭто предоставит вам все ваши разговоры в Facebook в достаточно унифицированном текстовом файле. Спасибо, Диллон! Продолжайте и сохраните этот файл в папке Facebook-Messenger-Bot.
Данные LinkedIn : Загрузите свои данные отсюда. После загрузки вы должны увидеть файл inbox.csv . Здесь нам не нужно предпринимать никаких других действий, мы просто хотим скопировать его в нашу папку.
Данные Google Hangouts : загрузите форму данных здесь. После загрузки вы получите файл JSON, который нам нужно будет проанализировать. Для этого мы воспользуемся парсером, найденным в этом феноменальном посте в блоге. Нам нужно сохранить данные в текстовые файлы, а затем скопировать папку в нашу.
В конце всего этого у вас должна получиться вот такая структура каталогов. Обязательно переименуйте папки и имена файлов, если у вас другие.
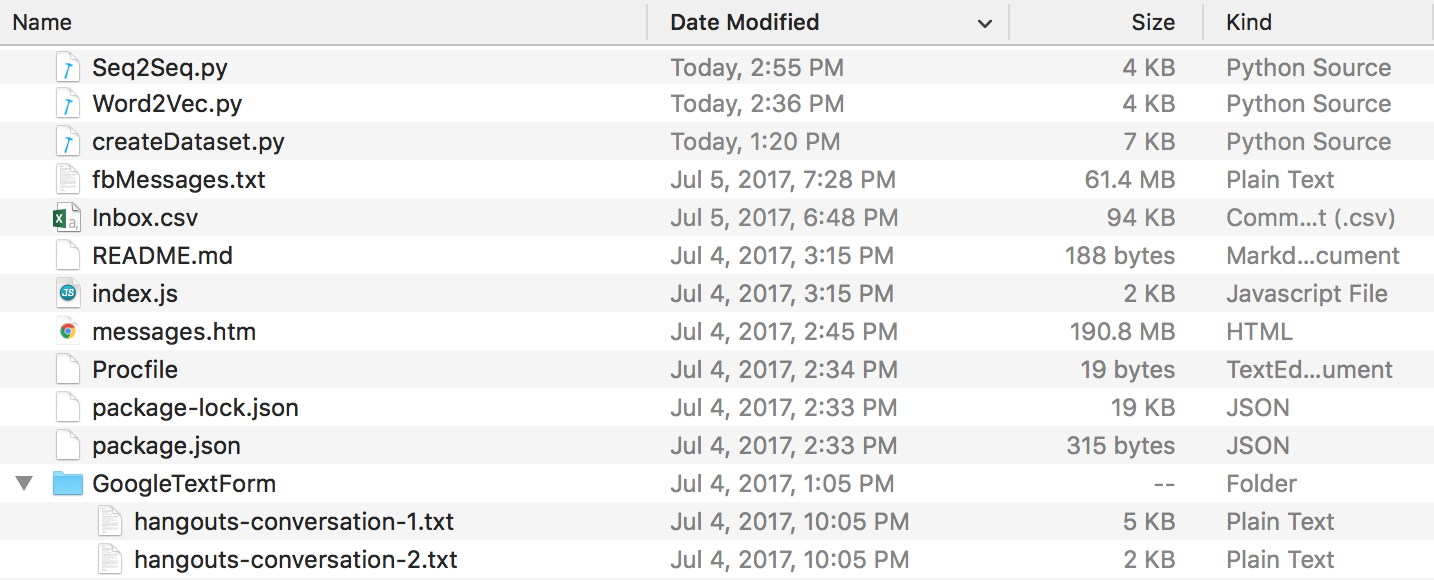
Данные Discord : вы можете извлечь журналы чатов Discord с помощью этого замечательного DiscordChatExporter, созданного Tyrrrz. Следуйте его документации, чтобы извлечь нужные отдельные журналы чата в формате .txt (это важно). Затем вы можете поместить их все в папку с именем DiscordChatLogs в каталоге репо.
Данные WhatsApp : убедитесь, что у вас есть мобильный телефон, и укажите для него формат даты в США, если это еще не так (это будет важно позже, когда вы преобразуете файл журнала в .csv). Вы не можете использовать WhatsApp Web для этой цели. Откройте чат, который хотите отправить, нажмите кнопку меню, нажмите «Еще», затем нажмите «Отправить чат по электронной почте». Отправьте электронное письмо себе и загрузите его на свой компьютер. Это даст вам файл .txt, для его анализа мы преобразуем его в .csv. Для этого перейдите по этой ссылке и введите весь текст в свой файл журнала. Нажмите «Экспорт», загрузите файл CSV и просто сохраните его в папке Facebook-Messenger-Bot под именем «whatsapp_chats.csv».
ПРИМЕЧАНИЕ . Парсер, представленный в приведенной выше ссылке, похоже, был удален. Если у вас все еще есть файл .csv в правильном формате , вы все равно можете его использовать. В противном случае загрузите журналы чата WhatsApp в виде файлов .txt и поместите их все в папку с именем WhatsAppChatLogs в каталоге репо. Вместо этого createDataset.py будет работать с этими файлами тогда и только тогда, когда он НЕ НАХОДИТ файл .csv с именем whatsapp_chats.csv .
Если вы используете журналы чата в .txt , обратите внимание, что ожидаемый формат:
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(ИЛИ)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
Теперь, когда у нас есть все журналы разговоров в чистом формате, мы можем продолжить и создать набор данных. В нашем каталоге запустим:
python createDataset.pyЗатем вам будет предложено ввести свое имя (чтобы сценарий знал, кого искать) и сайты социальных сетей, для которых у вас есть данные. Этот скрипт создаст файл с именем диалогаDictionary.npy , который представляет собой объект Numpy, содержащий пары в форме (FRIENDS_MESSAGE, ВАШ ОТВЕТ). Также будет создан файл разговораData.txt . Это просто большой текстовый файл со словарными данными в унифицированном виде.
Теперь, когда у нас есть эти два файла, мы можем начать создавать векторы слов с помощью модели Word2Vec. Этот шаг немного отличается от остальных. Функция Tensorflow, которую мы увидим позже (в seq2seq.py), на самом деле также обрабатывает часть внедрения. Таким образом, вы можете либо решить обучать свои собственные векторы, либо поручить это функции seq2seq, что я и сделал. Если вы хотите создать свои собственные векторы слов с помощью Word2Vec, скажите «y» в командной строке (после выполнения следующей команды). Если нет, то ничего страшного, ответьте n, и эта функция создаст только wordList.txt.
python Word2Vec.pyЕсли вы запустите word2vec.py полностью, будет создано 4 разных файла. Word2VecXTrain.npy и Word2VecYTrain.npy — это обучающие матрицы, которые будет использовать Word2Vec. Мы сохраняем их в нашей папке на случай, если нам понадобится снова обучить нашу модель Word2Vec с другими гиперпараметрами. Мы также сохраняем wordList.txt , который просто содержит все уникальные слова в нашем корпусе. Последний сохраненный файл — embeddingMatrix.npy , который представляет собой матрицу Numpy, содержащую все сгенерированные векторы слов.
Теперь мы можем использовать создание и обучение нашей модели Seq2Seq.
python Seq2Seq.pyЭто создаст 3 или более разных файла. Seq2SeqXTrain.npy и Seq2SeqYTrain.npy — это обучающие матрицы, которые будет использовать Seq2Seq. Опять же, мы сохраняем их на тот случай, если захотим внести изменения в архитектуру нашей модели и не захотим пересчитывать наш обучающий набор. Последними файлами будут файлы .ckpt, в которых хранится наша сохраненная модель Seq2Seq. Модели будут сохраняться в разные периоды времени в цикле обучения. Они будут использоваться и развернуты после создания нашего чат-бота.
Теперь, когда у нас есть сохраненная модель, давайте создадим нашего чат-бота Facebook. Для этого я бы рекомендовал следовать этому руководству. Вам не нужно ничего читать в разделе «Настройте то, что говорит бот». Наша модель Seq2Seq справится с этой частью. ВАЖНО. В руководстве вам будет предложено создать новую папку, в которой будет лежать проект Node. Имейте в виду, что эта папка будет отличаться от нашей. Вы можете думать об этой папке как о месте предварительной обработки данных и обучения модели, в то время как другая папка строго зарезервирована для приложения Express (РЕДАКТИРОВАНИЕ: я считаю, что вы можете следовать шагам руководства внутри нашей папки и просто создать проект Node, Procfile и файлы index.js, если хотите). Самого руководства должно быть достаточно, но вот краткое изложение шагов.
Правильно выполнив шаги, вы сможете отправить сообщение чат-боту и получить ответы.
Ах, вы почти закончили! Теперь нам нужно создать сервер Flask, на котором мы сможем развернуть сохраненную модель Seq2Seq. У меня есть код для этого сервера. Поговорим об общей структуре. Серверы Flask обычно имеют один основной файл .py, в котором вы определяете все конечные точки. В нашем случае это будет app.py. Именно сюда мы загружаем нашу модель. Вам следует создать папку под названием «модели» и заполнить ее четырьмя файлами (файл контрольной точки, файл данных, индексный файл и метафайл). Это файлы, которые создаются при сохранении модели Tensorflow.

В этом файле app.py мы хотим создать маршрут (в моем случае /prediction), где входные данные маршрута будут переданы в нашу сохраненную модель, а выходные данные декодера — это возвращаемая строка. Продолжайте и взгляните на app.py, если это все еще вас немного сбивает с толку. Теперь, когда у вас есть файл app.py и модели (и другие вспомогательные файлы, если они вам нужны), вы можете развернуть свой сервер. Мы снова будем использовать Heroku. Существует множество различных руководств по развертыванию серверов Flask в Heroku, но мне особенно нравится этот (разделы Foreman и Logging не нужны).
Вот так. У вас должна быть возможность отправлять сообщения чат-боту и видеть интересные ответы, которые (надеюсь) чем-то напоминают вас самих.
Пожалуйста, дайте мне знать, если у вас возникнут какие-либо проблемы или у вас есть предложения по улучшению этого README. Если вам кажется, что какой-то шаг неясен, дайте мне знать, и я постараюсь отредактировать README и внести какие-либо разъяснения.


