ChatLM mini Chinese
1.0.0
китайский | английский
Современные большие языковые модели, как правило, имеют большие параметры, а компьютеры потребительского уровня медленно делают простой вывод, не говоря уже о обучении модели с нуля. Целью этого проекта является обучение модели генеративного языка с нуля, включая очистку данных, обучение токенизатору, предварительное обучение модели, точную настройку инструкций SFT, оптимизацию RLHF и т. д.
ChatLM-mini-Chinese — это небольшая модель диалога на китайском языке с параметрами модели всего 0,2 МБ (около 210 МБ, включая общие веса). Ее можно предварительно обучить на машине с минимум 4 ГБ видеопамяти ( batch_size=1 , fp16 или bf16 ). ), а для загрузки и вывода float16 требуется как минимум 512 МБ видеопамяти.
Huggingface , включающую в себя transformers , accelerate , trl , peft и т. д.trainer поддерживает предварительное обучение и тонкую настройку SFT на одной машине с одной картой или с несколькими картами на одной машине. Он поддерживает остановку в любом положении во время тренировки и продолжение тренировки в любом положении.Text-to-Text и предварительное обучение прогнозированию без mask .sentencepiece и huggingface tokenizers ;batch_size=1, max_len=320 предварительное обучение поддерживается на машине с объемом памяти не менее 16 ГБ + 4 ГБ видеопамяти;trainer поддерживает быструю настройку команд и поддерживает любую точку останова для продолжения обучения;sequence to sequence тонких настроек Huggingface trainer ;peft lora для оптимизации предпочтений;Lora adapter можно объединить с исходной моделью.Если вам нужно выполнить расширенную генерацию поиска (RAG) на основе небольших моделей, вы можете обратиться к другому моему проекту Phi2-mini-Chinese. Код см. в rag_with_langchain.ipynb.
? Последние обновления
Все наборы данных взяты из наборов данных однораундовых разговоров, опубликованных в Интернете. После очистки и форматирования данных они сохраняются в виде паркетных файлов. О процессе обработки данных см. utils/raw_data_process.py . Основные наборы данных включают в себя:
Belle_open_source_1M , train_2M_CN и train_3.5M_CN , которые имеют короткие ответы, не содержат сложных структур таблиц и задач перевода (без списка английских слов), всего 3,7 миллиона строк, а после очистки остается 3,38 миллиона строк.N слов энциклопедии являются ответами. Используя 202309 данных энциклопедии, после очистки остается 1,19 миллиона подсказок и ответов. Загрузка Wiki: zhwiki, конвертируйте загруженный файл bz2 в ссылку wiki.txt: WikiExtractor. Общее количество наборов данных составляет 10,23 миллиона: набор предварительного обучения преобразования текста в текст: 9,3 миллиона, оценочный набор: 25 000 (поскольку декодирование происходит медленно, оценочный набор не устанавливается слишком большим). Тестовый набор: 900 000. Наборы данных точной настройки SFT и оптимизации DPO показаны ниже.
Модель T5 (преобразователь преобразования текста в текст), подробности см. в статье «Исследование ограничений трансферного обучения с помощью унифицированного преобразователя текста в текст».
Исходный код модели получен от Huggingface, см.: T5ForConditionalGeneration.
См. model_config.json для конфигурации модели. Официальная T5-base : encoder layer и decoder layer имеют 12 уровней. В этом проекте эти два параметра изменены до 10 уровней.
Параметры модели: 0,2В. Размер списка слов: 29298, включая только китайский и немного английского.
аппаратное обеспечение:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Обучение токенизатора . Существующая библиотека обучения tokenizer имеет проблемы с OOM при работе с большим корпусом. Поэтому полный корпус объединяется и конструируется на основе частоты слов в соответствии с методом, аналогичным BPE , на выполнение которого уходит полдня.
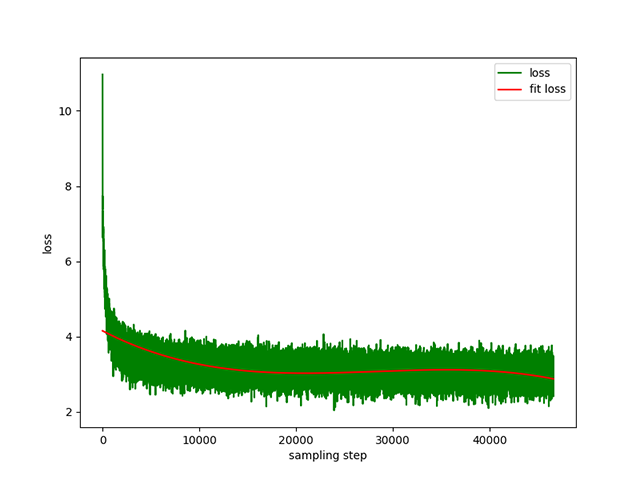
Предварительное обучение преобразованию текста в текст : динамическая скорость обучения от 1e-4 до 5e-3 и время предварительного обучения 8 дней. Тренировочные потери:
belle (длина инструкций и ответов меньше 512), скорость обучения представляет собой динамическую скорость обучения от 1e-7 до 5e-5 , а время точной настройки это 2 дня. Потери при точной настройке: 
chosen текста. На шаге 2 пакет модели SFT generate запросы в наборе данных и получает rejected текст. Это занимает 1 день. для оптимизации полного предпочтения dpo и обучения. Скорость le-5 , половинная точность fp16 , всего 2 epoch , и это занимает 3 часа. потеря ДПО: 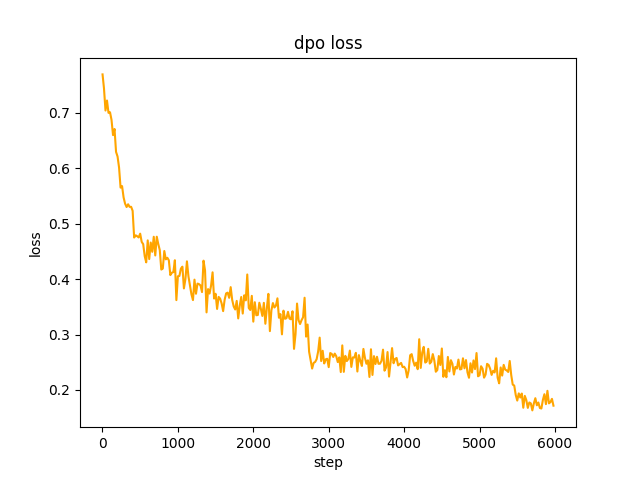
По умолчанию TextIteratorStreamer huggingface transformers используется для реализации потокового диалога, который поддерживает только greedy search . Если вам нужны другие методы генерации, такие как beam sample , измените stream_chat файла cli_demo.py на False . 

Есть проблемы: набор данных для предварительного обучения насчитывает всего более 9 миллионов, а параметры модели — всего 0,2B. Он не может охватить все аспекты, и возникнут ситуации, когда ответ неправильный, а генератор — ерунда.
Если не удается подключиться к Huggingface, используйте modelscope.snapshot_download , чтобы загрузить файл модели из modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Осторожность
Моделью этого проекта является модель TextToText . В prompt , response и других полях на этапах предварительного обучения, SFT и RLFH обязательно добавьте метку конца последовательности [EOS] .
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese В этом проекте рекомендуется использовать python 3.10 . Старые версии Python могут быть несовместимы со сторонними библиотеками, от которых они зависят.
установка пипа:
pip install -r ./requirements.txtЕсли pip установил версию pytorch для CPU, вы можете установить версию pytorch для CUDA с помощью следующей команды:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118установка конды:
conda install --yes --file ./requirements.txt Используйте команду git для загрузки весов модели и файлов конфигурации из Hugging Face Hub . Сначала необходимо установить Git LFS, а затем запустить:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save Вы также можете вручную загрузить его прямо со склада Hugging Face Hub ChatLM-Chinese-0.2B и переместить загруженный файл в каталог model_save .
Требования к корпусу должны быть максимально полными. Рекомендуется добавлять несколько корпусов, например энциклопедии, кодексы, статьи, блоги, беседы и т. д.
Этот проект в основном основан на китайской энциклопедии Wiki. Как получить корпус китайской вики: Адрес загрузки китайской вики: zhwiki, загрузите файл zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 , около 2,7 ГБ, преобразуйте загруженный файл bz2 в ссылку wiki.txt: WikiExtractor , Затем используйте библиотеку OpenCC Python, чтобы преобразовать его в упрощенный китайский язык, и, наконец, поместите полученный wiki.simple.txt в каталог data корневого каталога проекта. Пожалуйста, объедините несколько корпусов в один txt файл самостоятельно.
Поскольку обучающий токенизатор потребляет много памяти, если ваш корпус очень велик (объединенный txt файл превышает 2 ГБ), рекомендуется выполнить выборку корпуса по категориям и пропорциям, чтобы сократить время обучения и потребление памяти. Для обучения txt файла размером 1,7 ГБ требуется около 48 ГБ памяти (по оценкам, у меня всего 32 ГБ, часто вызывается обмен, компьютер зависает на долгое время T_T), процессор 13600k занимает около 1 часа.
Разница между char level и byte level заключается в следующем (пожалуйста, найдите информацию самостоятельно, чтобы узнать о конкретных различиях в использовании). Токенизатор по умолчанию обучает char level . Если требуется byte level , просто установите token_type='byte' в train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Начать обучение:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab или блокнот Jupyter:
См. файл train.ipynb . Рекомендуется использовать jupyter-lab, чтобы избежать ситуации, когда процесс терминала завершается после отключения от сервера.
Консоль:
При обучении консоли необходимо учитывать, что процесс будет завершен после отключения соединения. Для установления сеанса соединения рекомендуется использовать инструмент Supervisor программы процесса или screen .
Сначала настройте accelerate , выполните следующую команду и выберите согласно подсказкам. accelerate.yaml внимание: DeepSpeed сложнее установить на Windows .
accelerate config Начните обучение. Если вы хотите использовать конфигурацию, предоставленную проектом, добавьте параметр --config_file ./accelerate.yaml после следующей команды accelerate launch . Конфигурация основана на конфигурации с двумя графическими процессорами для одного компьютера.
Существует два скрипта для предварительного обучения: трейнер, реализованный в этом проекте, соответствует train.py , а трейнер, реализованныйhuggingface, соответствует pre_train.py . Вы можете использовать любой из них, и эффект будет одинаковым. Тренажер, реализованный в этом проекте, отображает более красивую информацию о обучении и упрощает изменение деталей обучения (например, функций потерь, записей журнала и т. д.). Тренажер, реализованный в этом проекте, поддерживает продолжение обучения после. точка останова в любой позиции. Нажмите ctrl+c чтобы сохранить информацию о точке останова при выходе из сценария.
Одна машина и одна карта:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Одна машина с несколькими картами: 2 — это количество видеокарт, измените его в соответствии с вашей реальной ситуацией.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyПродолжить обучение с точки останова:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyВесь набор данных SFT получен благодаря вкладу босса BELLE, спасибо. Наборы данных SFT:generated_chat_0.4M, train_0.5M_CN и train_2M_CN, после очистки осталось примерно 1,37 миллиона строк. Пример тонкой настройки набора данных с помощью команды sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Создайте свой собственный набор данных, воспользовавшись образцом файла parquet в каталоге data . Формат набора данных: файл parquet разделен на два столбца: один столбец текста prompt , который представляет подсказку, и один столбец текста response . который представляет ожидаемый результат модели. Подробности о тонкой настройке см. в методе train в model/trainer.py . Если для is_finetune установлено значение True , точная настройка по умолчанию заморозит уровень внедрения и уровень кодировщика и обучит только декодер. слой. Если вам нужно заморозить другие параметры, измените код самостоятельно.
Запустите тонкую настройку SFT:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyВот два наиболее распространенных метода: PPO и DPO. Найдите конкретные реализации в статьях и блогах.
Метод PPO (приблизительная оптимизация предпочтений, оптимизация проксимальной политики)
Шаг 1. Используйте набор данных точной настройки для контролируемой точной настройки (SFT, контролируемая точная настройка).
Шаг 2. Используйте набор данных о предпочтениях (подсказка содержит как минимум 2 ответа, один желаемый ответ и один нежелательный ответ. Несколько ответов можно отсортировать по баллам, при этом наиболее желательный ответ имеет наивысший балл) для обучения модели вознаграждения (RM , Модель вознаграждения). Вы можете использовать библиотеку peft , чтобы быстро построить модель вознаграждения Лоры.
Шаг 3. Используйте RM для контролируемого обучения PPO на модели SFT, чтобы модель соответствовала предпочтениям.
Используйте тонкую настройку DPO (Direct Preference Optimization) ( в данном проекте используется метод тонкой настройки DPO, который экономит видеопамять ). На основе получения модели SFT нет необходимости обучать модель вознаграждения для получения положительных ответов (). выбрано) и отрицательные ответы (отклонено), чтобы начать тонкую настройку. Точно настроенный chosen текст берется из исходного набора данных alpaca-gpt4-data-zh, а rejected текст — из выходных данных модели после точной настройки SFT для 1 эпохи. Два других набора данных: huozi_rlhf_data_json и rlhf-reward-. single-round-trans_chinese, после слияния Всего 80 000 данных dpo.
Информацию о процессе обработки набора данных dpo см. в разделе utils/dpo_data_process.py .
Пример набора данных оптимизации предпочтений DPO:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Запустите оптимизацию предпочтений:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Убедитесь, что в каталоге model_save есть следующие файлы. Эти файлы можно найти в хранилище ChatLM-Chinese-0.2B Hugging Face Hub :
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyПример вызова API:
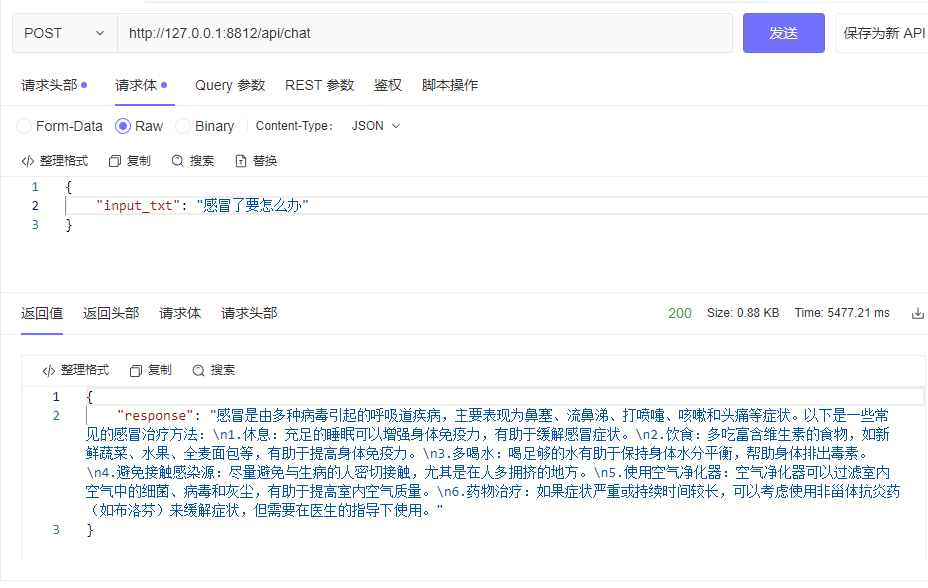
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Здесь мы берем информацию о триплете в тексте в качестве примера для последующей тонкой настройки. Традиционный метод извлечения данных глубокого обучения для этой задачи см. в хранилище pytorch_IE_model. Извлеките все тройки в фрагменте текста, например, предложение 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮, извлеките тройки (写生随笔,作者,张来亮) и (写生随笔,出版社,冶金工业) .
Исходный набор данных: набор данных тройного извлечения Baidu. Пример формата обработанного набора точно настроенных данных:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} Вы можете напрямую использовать сценарий sft_train.py для тонкой настройки. Скрипт Finetune_IE_task.ipynb содержит подробный процесс декодирования. Набор обучающих данных содержит около 17000 элементов, скорость обучения 5e-5 , а эпоха обучения 5 . Диалоговые возможности других задач после доработки не исчезли.

Эффект тонкой настройки: используйте набор данных dev , опубликованный百度三元组抽取数据集в качестве тестового набора для сравнения с традиционным методом pytorch_IE_model.
| Модель | Оценка F1 | Точность П | Напомним, Р |
|---|---|---|---|
| ЧатLM-Китайский-0.2B тонкая настройка | 0,74 | 0,75 | 0,73 |
| ЧатLM-Китайский-0.2B без предварительной подготовки | 0,51 | 0,53 | 0,49 |
| Традиционные методы глубокого обучения | 0,80 | 0,79 | 80,1 |
Примечание. ChatLM-Chinese-0.2B无预训练означает прямую инициализацию случайных параметров и начало обучения со скоростью обучения 1e-4 . Остальные параметры соответствуют точной настройке.
Сама модель не обучается с использованием более крупного набора данных и не настроена на инструкции по ответам на вопросы с несколькими вариантами ответов. Оценка C-Eval, по сути, является базовым уровнем и при необходимости может использоваться в качестве справочного материала. Оценочный код C-Eval см.: eval/c_eavl.ipynb
| категория | правильный | вопрос_количество | точность |
|---|---|---|---|
| Гуманитарные науки | 63 | 257 | 24,51% |
| Другой | 89 | 384 | 23,18% |
| КОРЕНЬ | 89 | 430 | 20,70% |
| Социальные науки | 72 | 275 | 26,18% |
Если вы считаете, что этот проект полезен для вас, процитируйте его.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
Этот проект не несет никаких рисков и ответственности, вытекающих из рисков безопасности данных и общественного мнения, вызванных моделями и кодами с открытым исходным кодом, а также введением в заблуждение, злоупотреблением, распространением или ненадлежащим использованием какой-либо модели.


