Seq2seq Chatbot for Keras
1.0.0
Этот репозиторий содержит новую генеративную модель чат-бота, основанную на моделировании seq2seq. Более подробную информацию об этой модели можно найти в разделе 3 статьи «Сквозное состязательное обучение для генеративных диалоговых агентов». В случае публикации с использованием идей или фрагментов кода из этого репозитория, пожалуйста, дайте ссылку на эту статью.
Обученная модель, доступная здесь, использовала небольшой набор данных, состоящий из ~ 8 тысяч пар контекста (последние два произнесения диалога до текущего момента) и соответствующего ответа. Данные были собраны из диалогов онлайн-курсов английского языка. Эту обученную модель можно точно настроить с использованием набора данных закрытого домена для реальных приложений.
Каноническая модель seq2seq стала популярной в нейронном машинном переводе — задаче, которая имеет разные априорные распределения вероятностей для слов, принадлежащих входной и выходной последовательностям, поскольку входные и выходные высказывания написаны на разных языках. Представленная здесь архитектура предполагает одинаковые априорные распределения входных и выходных слов. Таким образом, он использует общий уровень внедрения (встраивание предварительно обученных слов Glove) между процессами кодирования и декодирования за счет принятия новой модели. Чтобы улучшить чувствительность к контексту, вектор мысли (т. е. выходной сигнал кодера) кодирует два последних высказывания разговора до текущего момента. Чтобы не забыть контекст во время генерации ответа, вектор мысли объединяется с плотным вектором, который кодирует неполный ответ, сгенерированный до текущей точки. Результирующий вектор передается плотным слоям, которые предсказывают текущий токен ответа. См. раздел 3.1 нашей статьи, чтобы лучше понять преимущества нашей модели.
Алгоритм выполняет итерацию, включая предсказанный токен в неполный ответ и возвращая его обратно в правый входной слой модели, показанной ниже.
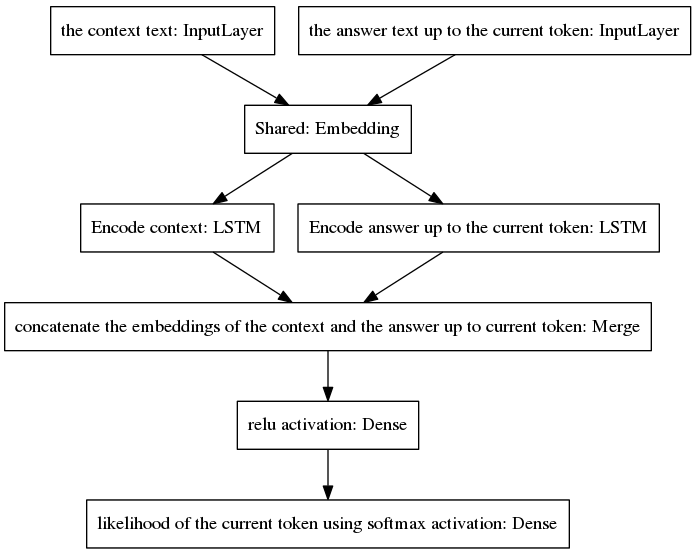
Как видно на рисунке выше, два LSTM расположены параллельно, в то время как канонический seq2seq имеет рекуррентные уровни кодера и декодера, расположенные последовательно. Рекуррентные слои разворачиваются при обратном распространении ошибки во времени, что приводит к большому количеству вложенных функций и, следовательно, к более высокому риску исчезновения градиента, который усугубляется каскадом рекуррентных слоев канонической модели seq2seq, даже в случае закрытых архитектур. такие как LSTM. Я считаю, что это одна из причин, почему моя модель ведет себя во время обучения лучше, чем каноническая seq2seq.
Следующий псевдокод объясняет алгоритм.

Обучение этой новой модели занимает несколько эпох. Используя наш набор данных обучающих примеров 8K, потребовалось всего 100 эпох, чтобы достичь категориальной потери перекрестной энтропии 0,0318, за счет 139 с/эпоху работы на графическом процессоре GTX980. Производительность этой обученной модели (представленной в этом репозитории) кажется столь же убедительной, как и производительность стандартной модели seq2seq, обученной на ~300 тыс. обучающих примерах Корнельского корпуса диалогов фильмов, но для обучения требуется гораздо меньше вычислительных усилий.
Чтобы пообщаться с предварительно обученной моделью:
Загрузите файл Python «conversation.py», файл словаря «vocabulary_movie» и чистые веса «my_model_weights20», которые можно найти здесь;
Запустите разговор.py.
Чтобы пообщаться с новой моделью, обученной с помощью нашего нового алгоритма обучения на основе GAN:
Загрузите файл Python «conversation_discriminator.py», файл словаря «vocabulary_movie» и чистые веса «my_model_weights20.h5», «my_model_weights.h5» и «my_model_weights_discriminator.h5», которые можно найти здесь;
Запустите разговор_дискриминатор.py.
Эта модель имеет лучшую производительность при использовании тех же обучающих данных. Дискриминатор модели на основе GAN используется для выбора лучшего ответа между двумя моделями: одна обучена учителем, а другая обучена с помощью нашего нового метода обучения, подобного GAN, подробности которого можно найти в этой статье.
Чтобы обучить новую модель или выполнить точную настройку собственных данных:
Если вы хотите тренироваться с нуля, удалите файл my_model_weights20.h5. Для точной настройки ваших данных сохраните этот файл;
Загрузите папку Glove «glove.6B» и включите эту папку в каталог чат-бота (эту папку можно найти здесь). Этот алгоритм применяет трансферное обучение, используя предварительно обученное встраивание слов, которое точно настраивается во время обучения;
Запустите файл Split_qa.py, чтобы разделить содержимое ваших обучающих данных на два файла: «контекст» и «ответы» и get_train_data.py, чтобы сохранить дополненные предложения в файлах «Дополненный_контекст» и «Дополненные_ответы»;
Запустите train_bot.py для обучения чат-бота (рекомендуется использовать графический процессор, для этого введите: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,Exception_verbosity=high python train_bot.py);
Назовите данные обучения как «data.txt». Этот файл должен содержать одно высказывание диалога в каждой строке. Если ваш набор данных большой, установите для переменной num_subsets (в строке 29 файла train_bot.py) большее число.
Weights_file = 'my_model_weights20.h5' Weights_file_GAN = 'my_model_weights.h5' Weights_file_discrim = 'my_model_weights_discriminator.h5'
Хороший обзор текущих реализаций нейронных диалоговых моделей для различных фреймворков (а также некоторые результаты) можно найти здесь.
Наша модель может быть применена к другим задачам НЛП, таким как обобщение текста, см., например, Альтернативный вариант 2: Рекурсивная модель А. Мы поощряем применение нашей модели в других задачах, в этом случае мы просим вас цитировать нашу работу, если это возможно. можно увидеть в этом документе, зарегистрированном в июле 2017 года.
Эти коды могут работать в Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 и Keras 2.0.4. Использование другой конфигурации может потребовать некоторых незначительных изменений.


