gutenberg dialog
1.0.0
Код для загрузки и создания собственной версии набора данных диалога Гутенберга. Легко расширяется за счет новых языков. Попробуйте обученных чат-ботов на разных языках здесь: https://ricsinaruto.github.io/chatbot.html.
| Ссылка для скачивания | Количество высказываний | Средняя длина высказывания | Количество диалогов | Средняя длина диалога |
|---|---|---|---|---|
| Английский | 14 773 741 | 22.17 | 2 526 877 | 5,85 |
| немецкий | 226 015 | 24.44 | 43 440 | 5.20 |
| Голландский | 129 471 | 24.26 | 23 541 | 5.50 |
| испанский | 58 174 | 18.62 | 6 912 | 8.42 |
| итальянский | 41 388 | 19.47 | 6 664 | 6.21 |
| венгерский | 18 816 | 14,68 | 2 826 | 6,66 |
| португальский | 16 228 | 21.40 | 2 233 | 7.27 |
? Создайте свой собственный набор данных, настроив параметры, влияющие на соотношение размера и качества набора данных.
Модульный интерфейс позволяет легко расширить набор данных на другие языки.
? Вы можете легко исключить книги вручную при построении набора данных.
Запустите setup.py, который установит необходимые пакеты.
python setup.py
Основной файл следует вызывать из корня репо. Приведенная ниже команда запускает конвейер построения набора данных для языков, разделенных запятыми, указанных в качестве аргумента. В настоящее время поддерживаются английский, немецкий, голландский, испанский, португальский, итальянский и венгерский языки.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
Все устанавливаемые аргументы можно увидеть ниже: 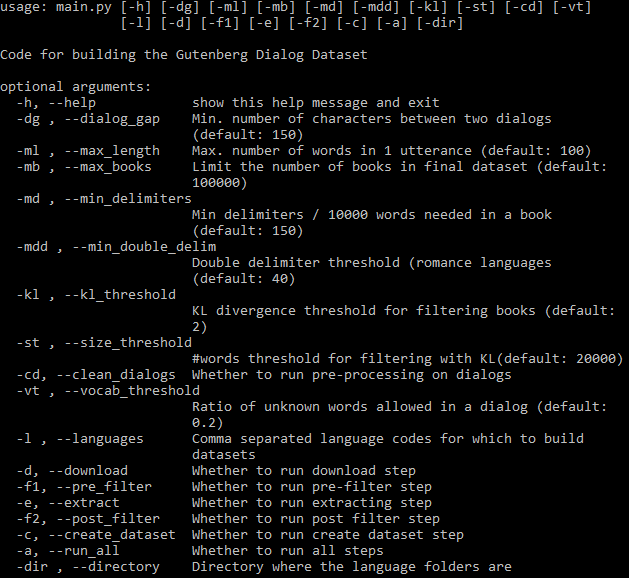
Флаг -a определяет, запускать ли весь конвейер автоматически. Если параметр -a опущен, подмножество шагов необходимо указать с помощью флагов (см. справку выше). После завершения шага его выходные данные можно использовать в последующих шагах, и он запускается снова только в том случае, если параметры или код, относящиеся к этому шагу, изменяются. Все шаги выполняются отдельно для каждого языка.
Загрузите книги для заданных языков.
Примечание. Если все книги не загружаются с ошибкой «Не удалось загрузить книгу», вероятно, причина в том, что зеркало по умолчанию, используемое пакетом Gutenberg , стало недоступно. В этом случае можно использовать любое из альтернативных зеркал, перечисленных на https://www.gutenberg.org/MIRRORS.ALL, через переменную среды GUTENBERG_MIRROR . Например:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
Предварительная фильтрация удаляет некоторые старые книги и шум.
Диалоги взяты из книг. При расширении набора данных на новые языки (см. раздел ниже) этот шаг можно изменить, поэтому предыдущие шаги можно пропустить после завершения.
Второй этап фильтрации: удаление некоторых диалогов на основе словарного запаса.
Собираем окончательный набор данных и разделяем его на данные обучения/разработки/тестирования. На последнем этапе в выходном каталоге создается файлauthor_and_title.txt , содержащий все книги (а также названия и авторов), использованные для извлечения окончательного набора данных. Пользователи могут вручную копировать строки из этого файла в Banned_books.txt , соответствующие книгам, которые не должны быть разрешены в наборе данных. При последующих выполнениях любых шагов книги в этом файле учитываться не будут.
Код можно легко расширить для обработки других языков. В папке языков необходимо создать файл с именем <код языка>.py. Здесь должен быть определен класс, названный кодом языка в верхнем регистре (например, En для английского языка), с LANG или любым другим подклассом в качестве родительского. Доступ к параметрам конфигурации self.cfg можно получить. Внутри этого класса должны быть определены три функции, указанные ниже. Пожалуйста, посмотрите it.py для примера.
Статистика языков
Эта функция должна возвращать словарь, где ключи являются потенциальными разделителями. Для каждого разделителя должна быть определена функция (значения в словаре), которая принимает на вход строку и возвращает число. Это число может быть, например, количеством разделителей, флагом наличия разделителя в строке и т. д. Обычно рекомендуется использовать взвешенный подсчет, в зависимости от важности различных разделителей. Значения будут использоваться для определения разделителя, который следует использовать в соответствующей книге (передается в функцию ниже), а также для фильтрации книг, содержащих небольшое количество разделителей. en.py содержит примеры нескольких разделителей.
Эта функция должна извлекать диалоги из книги и добавлять их в self.dialogs , который представляет собой список диалогов, а каждый диалог представляет собой список последовательных высказываний. Параграф_list содержит книгу в виде списка последовательных абзацев. разделитель — наиболее распространенный разделитель в этом файле, который следует использовать для извлечения диалогов.
Эта функция используется для постобработки диалогов (например, удаления определенных символов). В качестве входных данных принимается высказывание. Обратите внимание, что токенизация слов nltk выполняется автоматически.
Этот проект лицензируется по лицензии MIT — подробности см. в файле LICENSE.
Пожалуйста, включите ссылку на этот репозиторий, если вы используете какой-либо набор данных или код в своей работе и рассмотрите возможность цитирования следующей статьи:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


