Multi Modality Arena
1.0.0
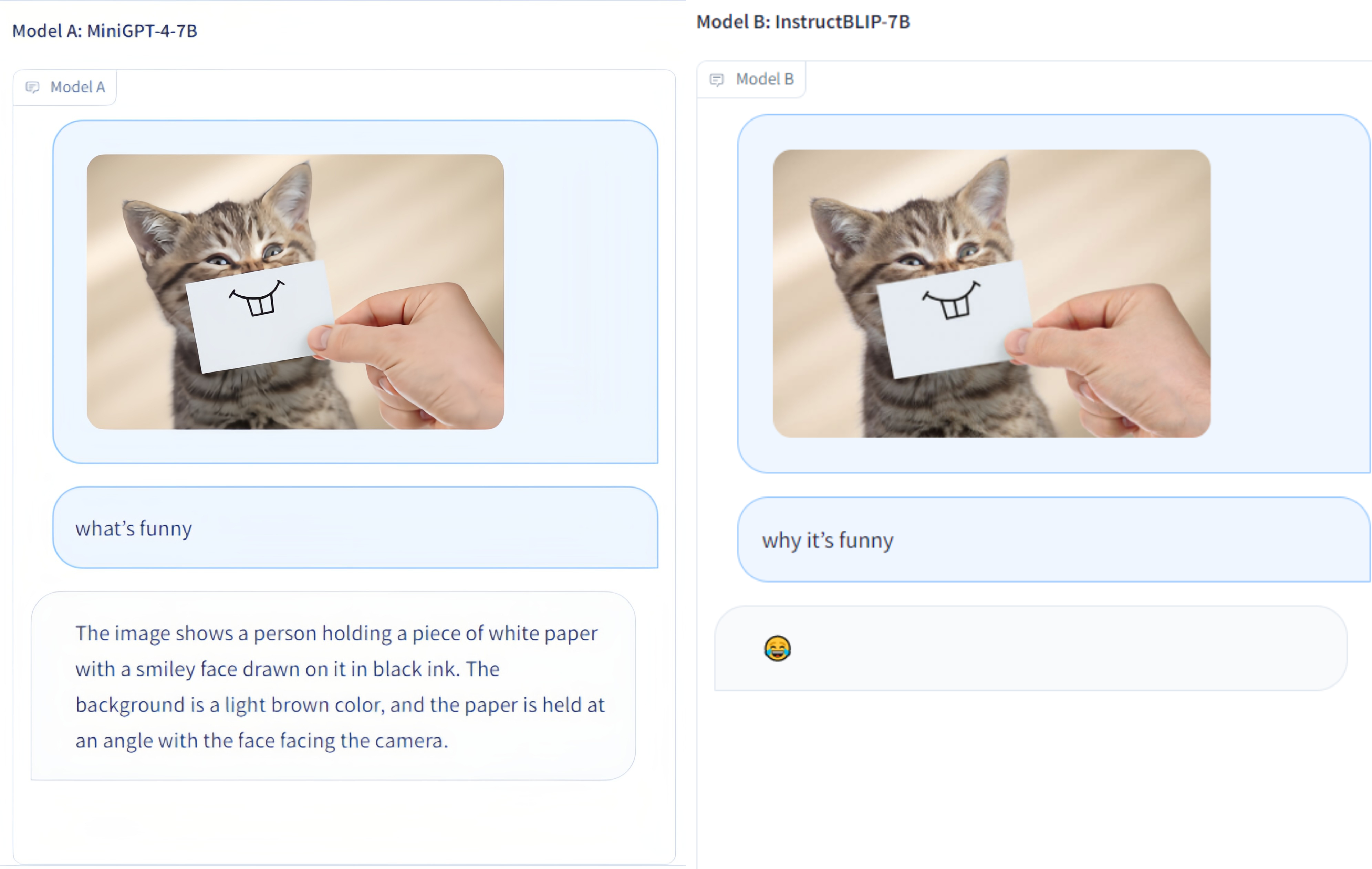
Multi-Modality Arena — это оценочная платформа для больших мультимодальных моделей. После Fastchat две анонимные модели сравниваются друг с другом, выполняя визуальную задачу ответа на вопросы. Мы выпускаем демо-версию и приветствуем участие всех в этой оценочной инициативе.
Набор данных OmniMedVQA: содержит 118 010 изображений с 127 995 элементами QA, охватывающими 12 различных модальностей и относящимися к более чем 20 анатомическим областям человека. Набор данных можно скачать здесь.
12 моделей: 8 LVLM общего назначения и 4 специализированных LVLM.
Крошечные наборы данных: всего 50 случайно выбранных образцов для каждого набора данных, т. е. 42 визуальных теста, связанных с текстом, и всего 2,1 тыс. образцов для простоты использования.
Еще модели: еще 4 модели, т.е. всего 12 моделей, включая Google Bard .
Оценка ансамбля ChatGPT : улучшенное согласие с оценкой человека по сравнению с предыдущим подходом сопоставления слов.
LVLM-eHub — это комплексный тест для оценки общедоступных крупных мультимодальных моделей (LVLM). Он широко оценивает
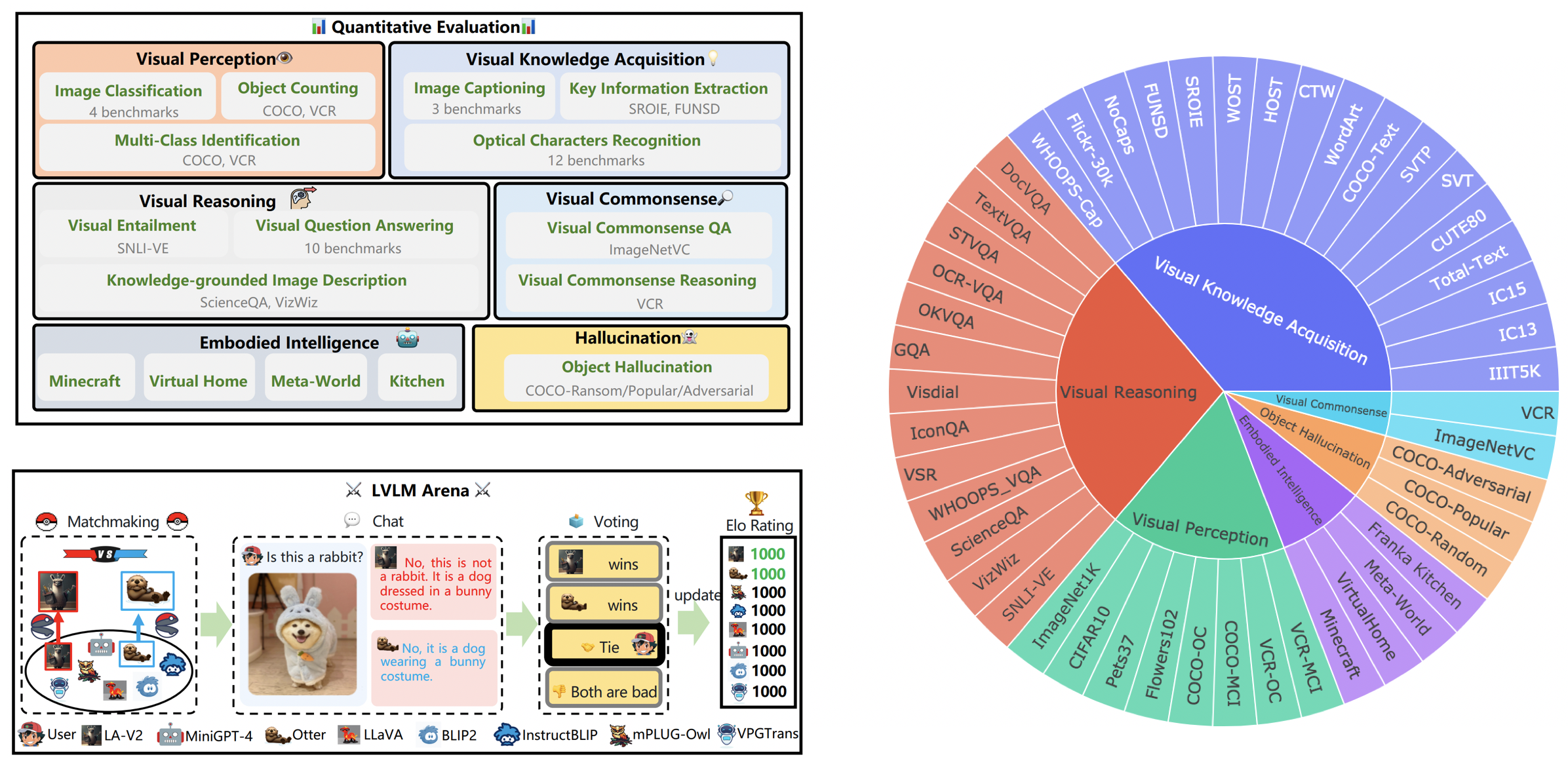
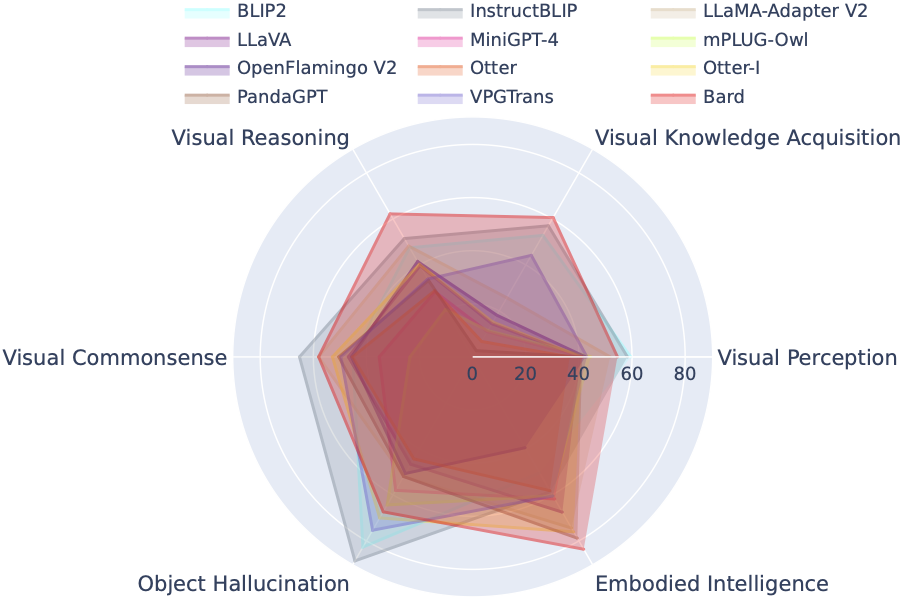
Таблица лидеров LVLM систематически классифицирует наборы данных, представленные в оценке Tiny LVLM, в соответствии с их конкретными целевыми способностями, включая зрительное восприятие, визуальное мышление, зрительный здравый смысл, приобретение визуальных знаний и объектные галлюцинации. В эту таблицу лидеров включены недавно выпущенные модели, что делает ее более полной.
Вы можете скачать тест здесь, а более подробную информацию можно найти здесь.
| Классифицировать | Модель | Версия | Счет |
|---|---|---|---|
| 1 | СтажерВЛ | СтажерVL-Чат | 327,61 |
| 2 | СтажерLM-XComposer-VL | СтажерLM-XComposer-VL-7B | 322,51 |
| 3 | Бард | Бард | 319,59 |
| 4 | Qwen-VL-Чат | Qwen-VL-Чат | 316,81 |
| 5 | ЛЛаВА-1,5 | Викунья-7Б | 307,17 |
| 6 | ИнструктироватьBLIP | Викунья-7Б | 300,64 |
| 7 | СтажерLM-XComposer | СтажерLM-XComposer-7B | 288,89 |
| 8 | БЛИП2 | ФланТ5xl | 284,72 |
| 9 | БЛИВА | Викунья-7Б | 284,17 |
| 10 | Рысь | Викунья-7Б | 279,24 |
| 11 | Гепард | Викунья-7Б | 258,91 |
| 12 | LLaMA-Адаптер-v2 | ЛЛаМА-7Б | 229,16 |
| 13 | ВПГТранс | Викунья-7Б | 218,91 |
| 14 | Изображение Выдры | Выдра-9B-LA-InContext | 216,43 |
| 15 | VisualGLM-6B | VisualGLM-6B | 211,98 |
| 16 | mPLUG-Сова | ЛЛаМА-7Б | 209,40 |
| 17 | ЛЛаВА | Викунья-7Б | 200,93 |
| 18 | МиниGPT-4 | Викунья-7Б | 192,62 |
| 19 | Выдра | Выдра-9Б | 180,87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176,37 |
| 21 | ПандаGPT | Викунья-7Б | 174,25 |
| 22 | Лавин | ЛЛаМА-7Б | 97,51 |
| 23 | ВПК | ФланТ5xl | 94.09 |
31 марта 2024 г. Мы выпускаем OmniMedVQA, крупномасштабный комплексный тест для оценки медицинских LVLM. Между тем, у нас есть 8 LVLM общего назначения и 4 LVLM медицинского назначения. Для получения более подробной информации посетите сайт MedicalEval.
16 октября 2023 г. Мы представляем разделение набора данных по уровням способностей, полученное на основе LVLM-eHub, дополненное включением восьми недавно выпущенных моделей. Для доступа к разделениям набора данных, коду оценки, результатам вывода модели и подробным таблицам производительности посетите сайт tiny_lvlm_evaluation ✅.
8 августа 2023 г. Мы выпустили [Tiny LVLM-eHub] . Исходные коды оценок и результаты вывода моделей находятся в открытом доступе в разделе tiny_lvlm_evaluation.
15 июня 2023 г. Мы выпускаем [LVLM-eHub] — эталон оценки для больших моделей визуального языка. Код скоро появится.
8 июня 2023 г. Спасибо доктору Чжану, автору VPGTrans, за исправления. Авторы VPGTrans в основном выходцы из НУК и Университета Цинхуа. Ранее у нас возникали небольшие проблемы при повторной реализации VPGTrans, но мы обнаружили, что его производительность на самом деле стала лучше. Если хотите узнать больше авторов моделей, свяжитесь со мной для обсуждения по электронной почте. Также, пожалуйста, следите за нашим рейтинговым списком моделей, где будут доступны более точные результаты.
Может. 22, 2023. Спасибо доктору Йе, автору mPLUG-Owl, за исправления. Мы исправляем некоторые незначительные проблемы в нашей реализации mPLIG-Owl.
В настоящее время в случайных боях участвуют следующие модели:
КАУСТ/МиниГПТ-4
Salesforce/BLIP2
Salesforce/InstructBLIP
Академия ДАМО/mPLUG-Сова
НТУ/Выдра
Университет Висконсина-Мэдисона/LLaVA
Шанхайская лаборатория искусственного интеллекта/llama_adapter_v2
НУС/ВПГТранс
Более подробную информацию об этих моделях можно найти по адресу ./model_detail/.model.jpg . Мы постараемся запланировать вычислительные ресурсы для размещения на арене большего количества мультимодальных моделей.
Если вас интересуют какие-либо части нашей платформы VLarena, присоединяйтесь к группе Wechat.

Создать среду Конды
conda create -n arena python=3.10 Конда активирует арену
Установите пакеты, необходимые для запуска контроллера и сервера.
pip install numpy gradio uvicorn fastapi
Затем для каждой модели могут потребоваться конфликтующие версии пакетов Python. Мы рекомендуем создать специальную среду для каждой модели на основе их репозитория GitHub.
Для обслуживания с использованием веб-интерфейса вам нужны три основных компонента: веб-серверы, которые взаимодействуют с пользователями, рабочие модели, на которых размещаются две или более модели, и контроллер для координации веб-сервера и рабочих моделей.
Вот команды, которым нужно следовать в вашем терминале:
контроллер Python.py
Этот контроллер управляет распределенными рабочими процессами.
python model_worker.py --имя-модели SELECTED_MODEL --device TARGET_DEVICE
Подождите, пока процесс загрузит модель и вы увидите «Uvicorn работает на…». Рабочий модели зарегистрируется на контроллере. Для каждой рабочей модели необходимо указать модель и устройство, которое вы хотите использовать.
python server_demo.py
Это пользовательский интерфейс, с которым будут взаимодействовать пользователи.
Выполнив эти шаги, вы сможете обслуживать свои модели с помощью веб-интерфейса. Вы можете открыть браузер и пообщаться с моделью прямо сейчас. Если модели не отображаются, попробуйте перезагрузить веб-сервер Gradio.
Мы глубоко ценим любой вклад, направленный на повышение качества наших оценок. Этот раздел состоит из двух ключевых сегментов: Contributions to LVLM Evaluation и Contributions to LVLM Arena .
Вы можете получить доступ к самой последней версии нашего оценочного кода в папке LVLM_evaluation. Этот каталог содержит полный набор оценочного кода, сопровождаемый необходимыми наборами данных. Если вы с энтузиазмом относитесь к участию в процессе оценки, не стесняйтесь поделиться с нами результатами оценки или API вывода модели по электронной почте [email protected].
Мы выражаем нашу благодарность за ваш интерес к интеграции вашей модели в нашу LVLM Arena! Если вы хотите включить свою модель в нашу Арену, подготовьте тестер моделей, структурированный следующим образом:
class ModelTester:def __init__(self, device=None) -> None:# TODO: инициализация модели и требуемых предварительных процессоровdef move_to_device(self, device) -> None:# TODO: эта функция используется для передачи модели между ЦП и GPU (необязательно)defgenerate(self, image,question) -> str: # TODO: код вывода модели
Кроме того, мы открыты для онлайн-ссылок для вывода моделей, например, предоставляемых такими платформами, как Gradio. Ваш вклад искренне оценен.
Мы выражаем благодарность уважаемой команде ChatBot Arena и их статье Judgeging LLM-as-a-Judge за их влиятельную работу, которая послужила вдохновением для наших усилий по оценке LVLM. Мы также хотели бы выразить нашу искреннюю признательность поставщикам LVLM, чей ценный вклад внес значительный вклад в прогресс и продвижение больших моделей языка видения. Наконец, мы благодарим поставщиков наборов данных, используемых в нашем LVLM-eHub.
Проект представляет собой экспериментальный исследовательский инструмент, предназначенный исключительно для некоммерческих целей. Он имеет ограниченные меры безопасности и может создавать неприемлемый контент. Его нельзя использовать для чего-либо незаконного, вредного, насильственного, расистского или сексуального.


