Sound Content Music Recommendation System
1.0.0

Если вы похожи на меня, вы любите музыку. Я люблю музыку и люблю находить новую музыку. Spotify — один из лучших сервисов потоковой передачи музыки в Интернете, который уже включает в себя замечательные инструменты, которые помогут вам находить новую музыку на основе того, что вы слушаете. Это достигается за счет комбинации различных алгоритмов, включая совместную фильтрацию, при которой одинаковое использование между пользователями отслеживается и используется для создания рекомендаций или рекомендаций на основе контента, которые рекомендуют новые песни на основе схожей информации в информации, связанной с песней. Как песня? На Spotify вы можете послушать «радио» этой песни, которое соберет группу песен, похожих на эту песню тем или иным образом или комбинацией способов. Что делать, если вам нравится песня, но вас не волнует никакая информация, кроме звука в ней? Иногда это все, что я хочу услышать.
Я создал этот проект, чтобы создать систему музыкальных рекомендаций, основанную только на информации, содержащейся в звуках музыки. Это поможет пользователю находить новую музыку среди похожих по звучанию песен. Для этого он также исследует сходства между всей музыкой и пытается математически уловить тембр, ритм и стиль песни.
Звук всегда вокруг нас. На протяжении всей нашей жизни мы учимся различать звуки, отличающиеся от других. Музыка ничем не отличается: существует множество типов музыки, и музыка часто представляет собой комбинацию множества различных звуков и ритмов, которые мы также можем различать отдельно от других. Но можем ли мы сами измерить эту информацию? Иногда музыку подразделяют на жанры, то есть жанр — это группа музыкантов со схожими качествами стиля, формы, ритма, тембра, инструментов или культуры. Но не каждый музыкальный исполнитель создает звук в одном и том же жанре, и не каждый жанр содержит одну и ту же музыку. Так что же такое звук и как мы различаем разные типы звука?
Звук — это вибрация акустических волн, которые мы воспринимаем через уши, когда эти волны вибрируют наши барабанные перепонки. Звуковая волна — это сигнал, и скорость, с которой этот сигнал вибрирует, называется частотой. Если частота звука выше, мы воспринимаем этот звук как более высокий. В музыке такие инструменты, как бас или большие барабаны, создают звуки, которые вибрируют на более низкой частоте, тогда как высокие частоты имеют более высокую частоту. Звуки, похожие на удар тарелки или хай-хэта, представляют собой комбинацию множества волн на разных частотах и представляют собой «шумную», почти беспорядочную волну.
Как выглядит звук? Один из способов визуализировать звук — построить график сигнала во времени:
Сокращая временной интервал на каждом подграфике, мы можем видеть звуковой сигнал гораздо ближе. Обратите внимание, что на самом увеличенном изображении сигнала волна представляет собой набор разных частот. Может существовать один низкочастотный сигнал, который сочетается с более мелкими высокочастотными сигналами.
Итак, мы можем визуализировать сигнал с течением времени, но уже сейчас можем сказать, что трудно многое понять об этой звуковой волне, просто взглянув на эту визуализацию. Какие частоты присутствуют в этом окне длительностью 0,01 секунды? Чтобы ответить на этот вопрос, мы воспользуемся преобразованием Фурье для расчета спектрограммы.
Преобразование Фурье — это метод расчета амплитуды частот, присутствующих в участке аудиосигнала. Как вы можете видеть на графике выше, волны могут быть сложными, и каждое изменение сигнала представляет собой разную частоту (скорость вибрации). Преобразование Фурье по существу извлекает частоты для каждого отрезка времени и создает двумерный массив частотных амплитуд в зависимости от времени. Результатом преобразования Фурье является спектрограмма. Из спектрограммы мы преобразуем полученные частоты в мел-шкалу, чтобы создать мел-спектрограмму. Мел-спектрограмма лучше отражает воспринимаемое расстояние между частотами, когда мы их слышим.
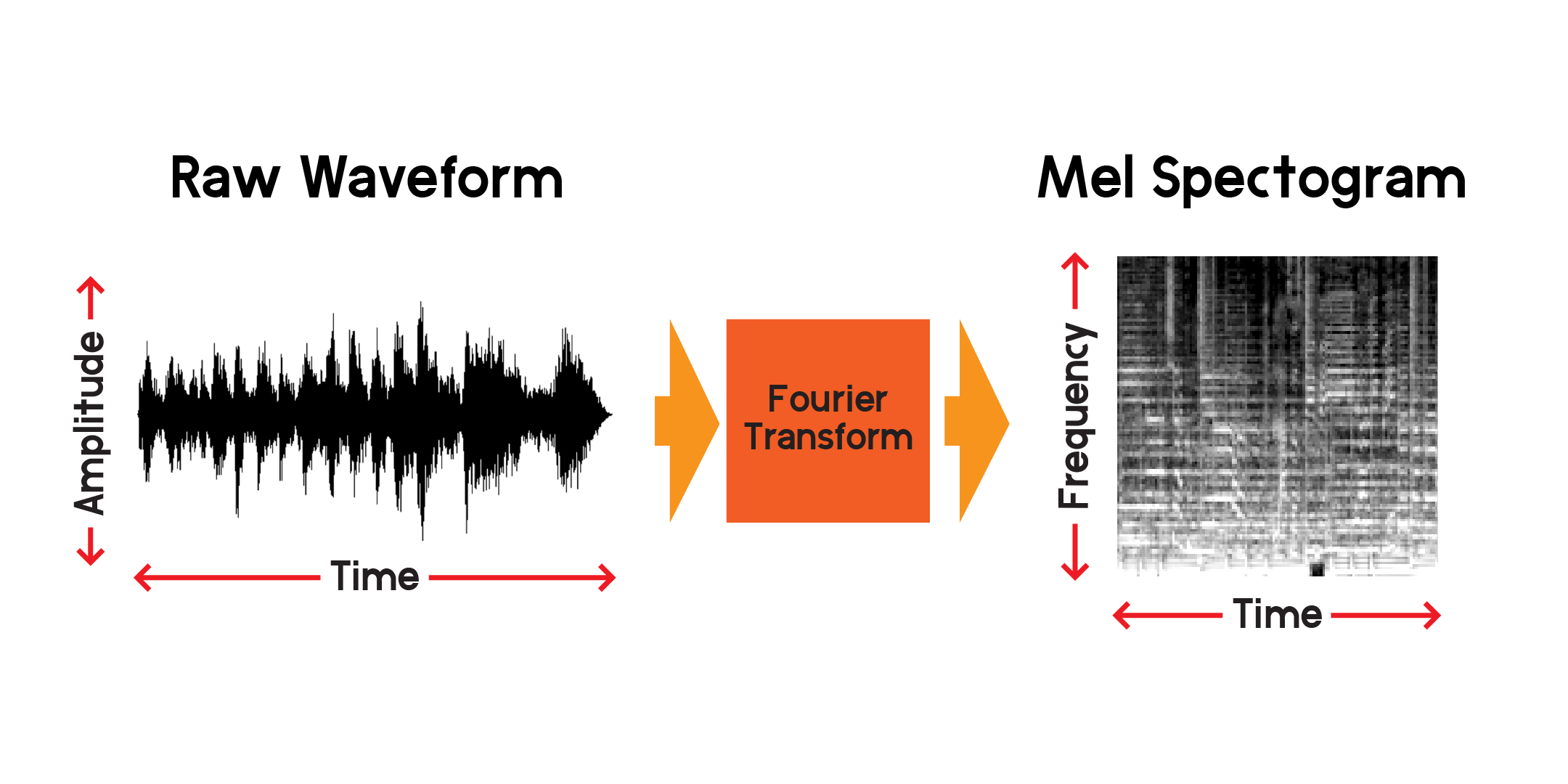
Давайте построим пример мел-спектрограммы из того же аудиосэмпла, который мы построили выше:
Используя Public API Spotify, я извлек информацию о песнях из предыдущего блокнота. Оттуда я могу загрузить 30-секундный предварительный просмотр каждой песни в формате mp3 и преобразовать его в мел-спектрограмму для использования в нейронной сети, которая обучается на изображениях. Во-первых, давайте посмотрим на фрейм данных, который мы будем использовать для сбора превью mp3.
В другом блокноте я взял ссылки для предварительного просмотра из Spotify API, загрузил mp3-файлы и преобразовал звуковые файлы в составное изображение, содержащее мел-спектрограмму, мел-частотный кепстральный коэффициент и хромаграмму. Я создал это составное изображение с намерением использовать и другие преобразования, но в этом проекте я буду обучать нейронную сеть только на мел-спектрограммах.
Чтобы давать рекомендации по похожим песням, основываясь только на звуковом содержании, мне нужно будет создать функции, которые каким-то образом объяснят содержание песен. Кроме того, чтобы сделать это быстро, мне нужно будет сжать информацию каждой песни в меньший набор чисел, чем входные данные мел-спектрограмм.
В каждом файле предварительного просмотра песни содержится более 600 000 сэмплов. В каждой мел-спектрограмме имеется 512 x 128 пикселей, всего 65 536 пикселей. Даже изображение размером 128x128 содержит 16 384 пикселя. Эта модель автокодировщика сжимает содержимое песни всего до 256 чисел. Как только автоэнкодер будет достаточно обучен, сеть сможет восстановить песню из этого вектора длиной 256 с минимальными потерями.
Автоэнкодер — это тип нейронной сети, состоящей из кодера и декодера . Во-первых, кодер сжимает входную информацию в гораздо меньший объем данных, а декодер реконструирует данные так, чтобы они были как можно ближе к исходному выводу.
Автоэнкодер также является особым типом нейронной сети, поскольку он не контролируется, хотя и не совсем неконтролируемый. Он является самоконтролируемым, поскольку использует свои входные данные для обучения выходных данных модели.
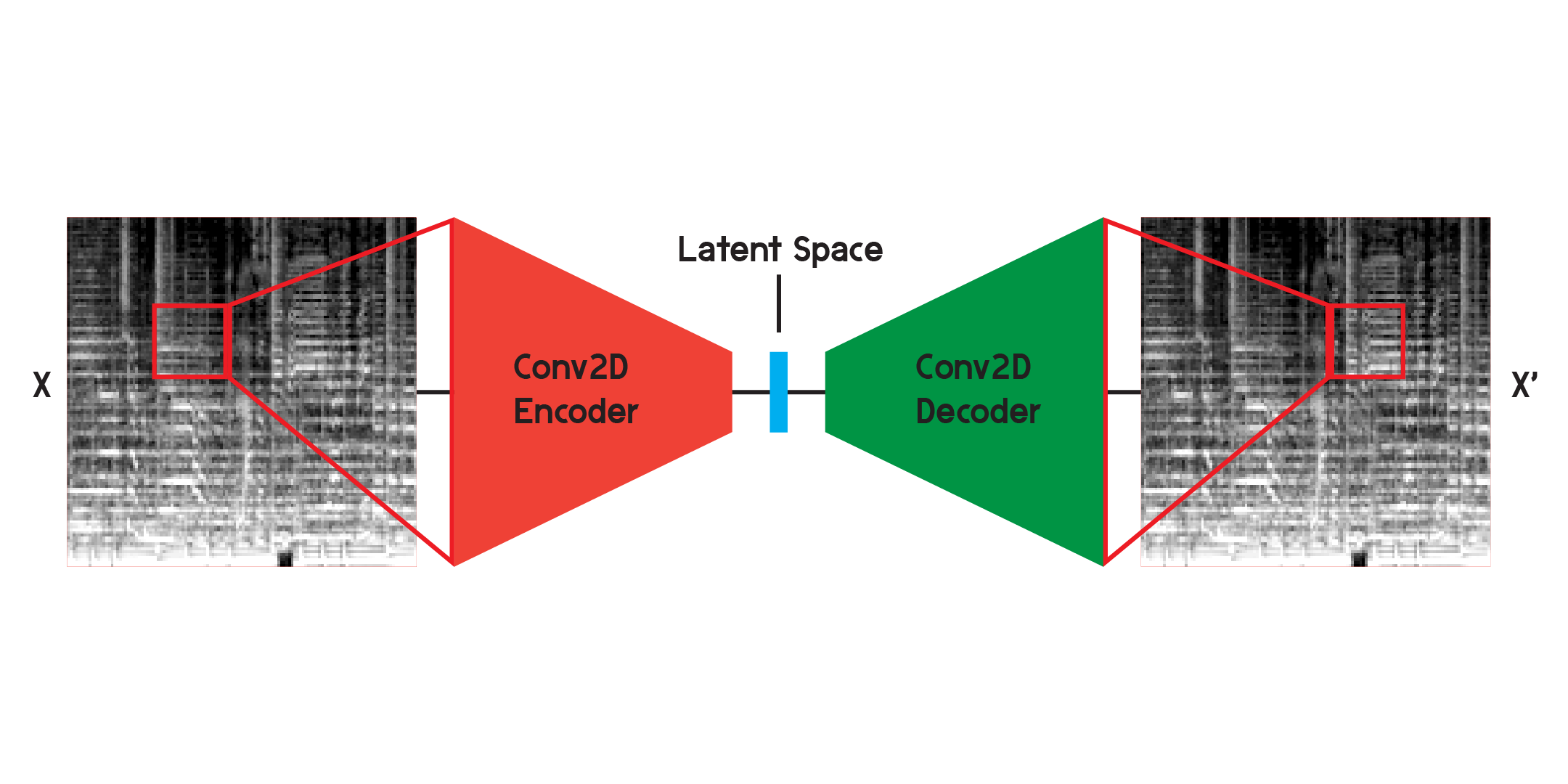
При работе с изображениями кодер представляет собой последовательность двумерных сверточных слоев, которые создают взвешенные фильтры для извлечения шаблонов в изображении, а также сжимают изображение до все меньшей и меньшей формы. Декодер является зеркальным отражением процесса в кодере, преобразуя и расширяя небольшой объем данных в больший. Модель минимизирует среднеквадратическую ошибку между оригиналом и реконструкцией. После достаточного обучения среднеквадратическая ошибка между исходным и выходным данными модели будет очень маленькой. Хотя среднеквадратическая ошибка будет минимальной, визуальная разница между реконструкцией и исходным изображением все же существует, особенно в мельчайших деталях. Автоэнкодер — это подавитель шума. Мы хотим извлечь как можно больше деталей, но в конечном итоге автоэнкодер также смешает некоторые детали.
Сначала я обучил сеть, используя структуру, показанную выше, но обнаружил, что в реконструкциях отсутствуют многие детали. Сверточные слои ищут шаблоны, которые представляют собой лишь небольшой фрагмент всего изображения. Но после обучения и наблюдения за фильтрами трудно интуитивно понять извлекаемые закономерности.
Подобные автоэнкодеры можно использовать для решения нескольких различных задач, а благодаря сверточным слоям существует множество приложений для распознавания и генерации изображений. Но поскольку мел-спектрограмма представляет собой не только изображение, но и график частот звукового содержания с течением времени, я считаю, что можно реализовать немного другую структуру, чтобы минимизировать потери при реконструкции, а также минимизировать неопределенность, создаваемую двумерной сверточной моделью. слои.
В модели, используемой для получения окончательных результатов модели, я разделил кодировщик на два отдельных кодера. Каждый кодер использует одномерные сверточные слои для сжатия пространства изображения. Один кодер тренируется на X, а другой тренируется на транспонировании X или версии входных данных, повернутой на 90 градусов. Таким образом, один кодер изучает информацию по оси времени изображения, а другой — по оси частоты.
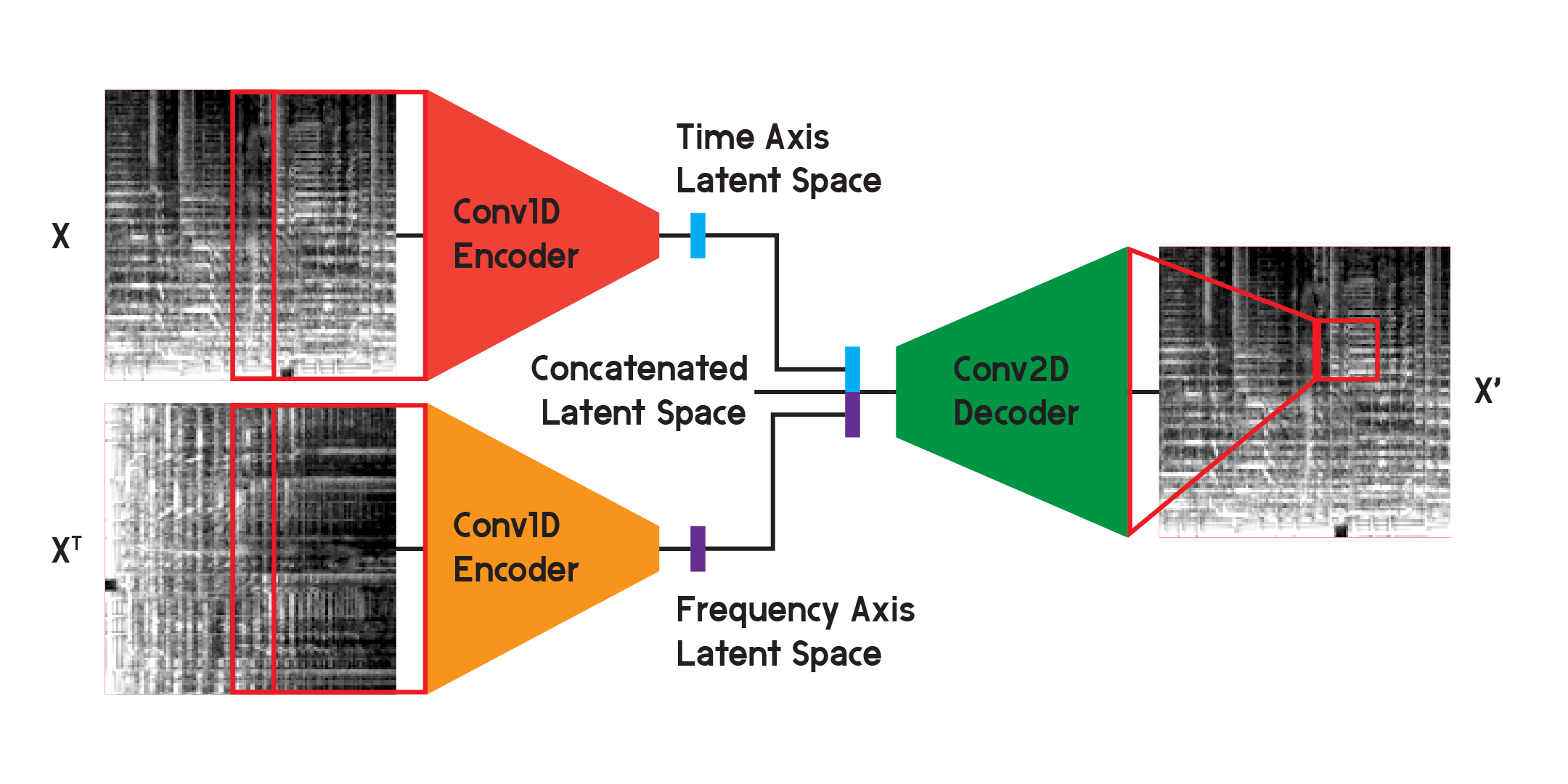
После того, как входные данные проходят через каждый кодер, результирующие закодированные векторы объединяются в один вектор и вводятся в двумерный сверточный декодер, как показано ранее. Выходы обучаются так, чтобы минимизировать потери между входами, как и раньше.
В конце концов, потери в окончательной модели оказались намного ниже, чем в базовой структуре, достигнув среднеквадратической ошибки 0,0037 (обучение) и 0,0037 (проверка) после 20 эпох, при 125 440 изображениях в обучающем наборе и 2560 в обучающем наборе. набор проверки.
Мы будем строить модель здесь только в демонстрационных целях, поскольку я обучал ее в другом блокноте, а веса из обученной модели загрузим после ее построения.
Используя специальный класс для выполнения вывода через сеть и сохранения результатов, мы можем создать скрытое пространство для каждой имеющейся у нас mel-спектрограммы. Мы можем сделать это, пропустив данные только через кодировщик и получив вектор того размера, который мы инициализировали модель, в данном случае с 256 измерениями.
Чтобы исследовать абстрактный ландшафт, созданный скрытым пространством данных через модель, мы можем использовать уменьшение размерности. UMAP, как и T-SNE, может уменьшать многомерное пространство до двух измерений для визуализации на графике.
Пользовательский класс LatentSpace будет искать рекомендации, используя косинусное сходство для каждого вектора.
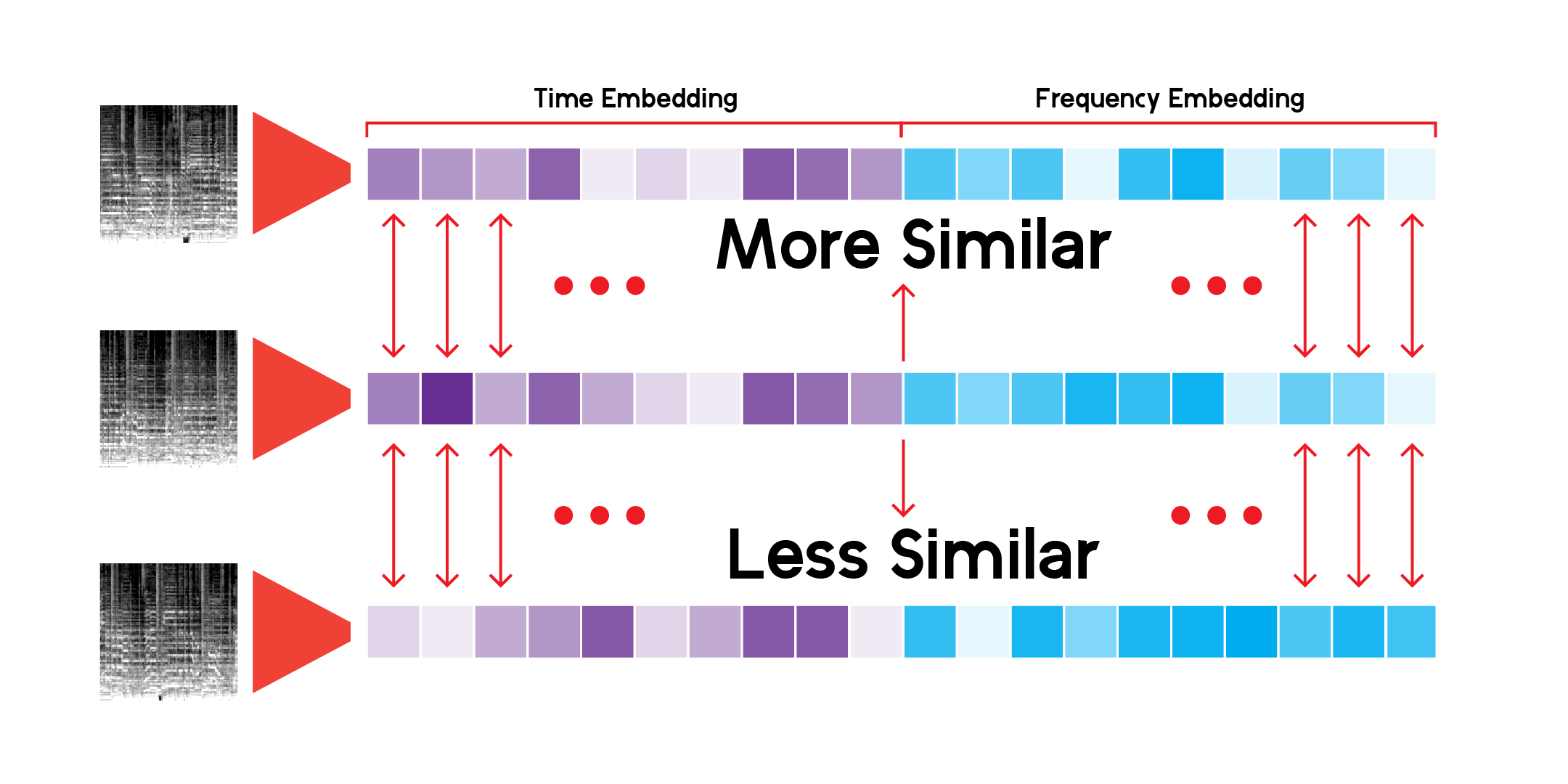
Я бесконечно просматривал эту систему рекомендаций и доволен, что модель умеет находить очень интересные связи между разными, но в то же время похожими музыкальными звуками. Вот некоторые из моих выводов:
Я имею в виду, что модель дает рекомендации на основе звукового содержания каждой песни, но не слушает песню. Он создает мел-спектрограмму и выполняет математическое сравнение.
Иногда система рекомендует песню на основе ее возраста. Если песня была записана давно, модель уловит именно эти частоты записывающего материала или оборудования и отобразит результаты.
Также модель очень хорошо улавливает голос или отдельные инструменты. По этой причине, если в песне много разговоров или разговоров-пения, в ней могут быть рекомендованы только треки с устными словами. Кроме того, если в песне много искажений, можно рекомендовать звуки дождя или пение птиц.
Как указано в моем первоначальном EDA, предварительный просмотр некоторых треков недоступен в Spotify API. Следовательно, их вклад в модель также отсутствует и не может быть рекомендацией, хотя они могут идеально подходить для нее. Например, здесь нет песен Джеймса Брауна, Битлз или Принса. Нужно больше данных.
Система использует более 278 000 превью для выдачи рекомендаций, и этого все еще недостаточно. Если посмотреть на проекцию UMAP для всех треков, то можно увидеть, что в данных наблюдается значительная непрерывность, но есть и некоторые дыры. В идеале система могла бы использовать гораздо больше данных для обработки.
Что делает систему/сервисы рекомендаций, такие как Spotify, такими хорошими в выдаче рекомендаций, так это то, что они сочетают в себе множество различных типов рекомендательных систем и функций, подобных этой, для предоставления рекомендаций. От отслеживания того, что вы регулярно слушаете, до использования совместной фильтрации для поиска рекомендаций, основанных на аналогичном использовании пользователей, Spotify может делать гораздо более сбалансированные прогнозы о том, что кому-то понравится и что будет слушать. Я считаю эту модель интересной для прогнозирования, но ее можно улучшить, добавив больше функций, таких как схожие жанры, годы выпуска и аналогичные пользовательские данные, чтобы сделать более качественные прогнозы.
В целом, помимо предсказаний и рекомендаций, я считаю, что истинная важность этой модели заключается в объяснении непрерывности и спектра музыкального языка и звука. Жанры — это ярлыки, которые люди навешивают на исполнителя или звук, но жанры смешиваются, и каждый звук существует в этом непрерывном пространстве, по крайней мере математически.
Кроме того, у музыки нет преград. В большинстве случаев при запросе песни в системе рекомендаций результаты приходят из разных эпох и разных мест. Поскольку никакие метаданные песни не являются входными данными для автокодировщика, результаты основаны на их звуковом сходстве и не более того.


