nlp lt
1.0.0
Основная цель этого исследования — изучить и изучить принципы обработки естественного языка (NLP) для литовского языка. Интересно проанализировать классические методы НЛП и посмотреть, как они на этом работают, поэтому в этой работе я реализовал идеи классификации текста, извлечения тем, поисковых запросов и кластеризации. Детали реализации и дополнительная информация хранятся по адресу paper/paper.pdf.
Анализ данных невозможно провести без текстовых данных, поэтому моя работа началась с получения необработанных данных с самого популярного новостного сайта www.delfi.lt. Я решил просканировать статьи из 5 категорий (Преступники[227 статей], Музыка[120 статей], Кино[167 статей], Спорт[136 статей], Наука[204 статьи]).
Эффективность классификации измеряется с помощью матрицы путаницы, где строки представляют собой истинную категорию, а столбцы — прогнозируемую категорию. Кроме того, такой подход достигает более 90% точности и 90% точности. 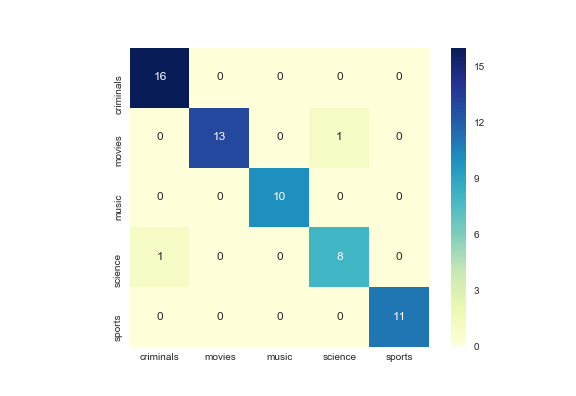
На рисунке показаны 6 компонентов с 10 токенами для каждого компонента. По этим результатам мы можем определить наиболее важные слова и интуитивно угадать тему для каждого основного компонента. Например, 4 основных компонента хранят информацию о спорте и музыке, тогда как 6 основных компонентов хранят информацию о преступниках.
Основные результаты представлены ниже: 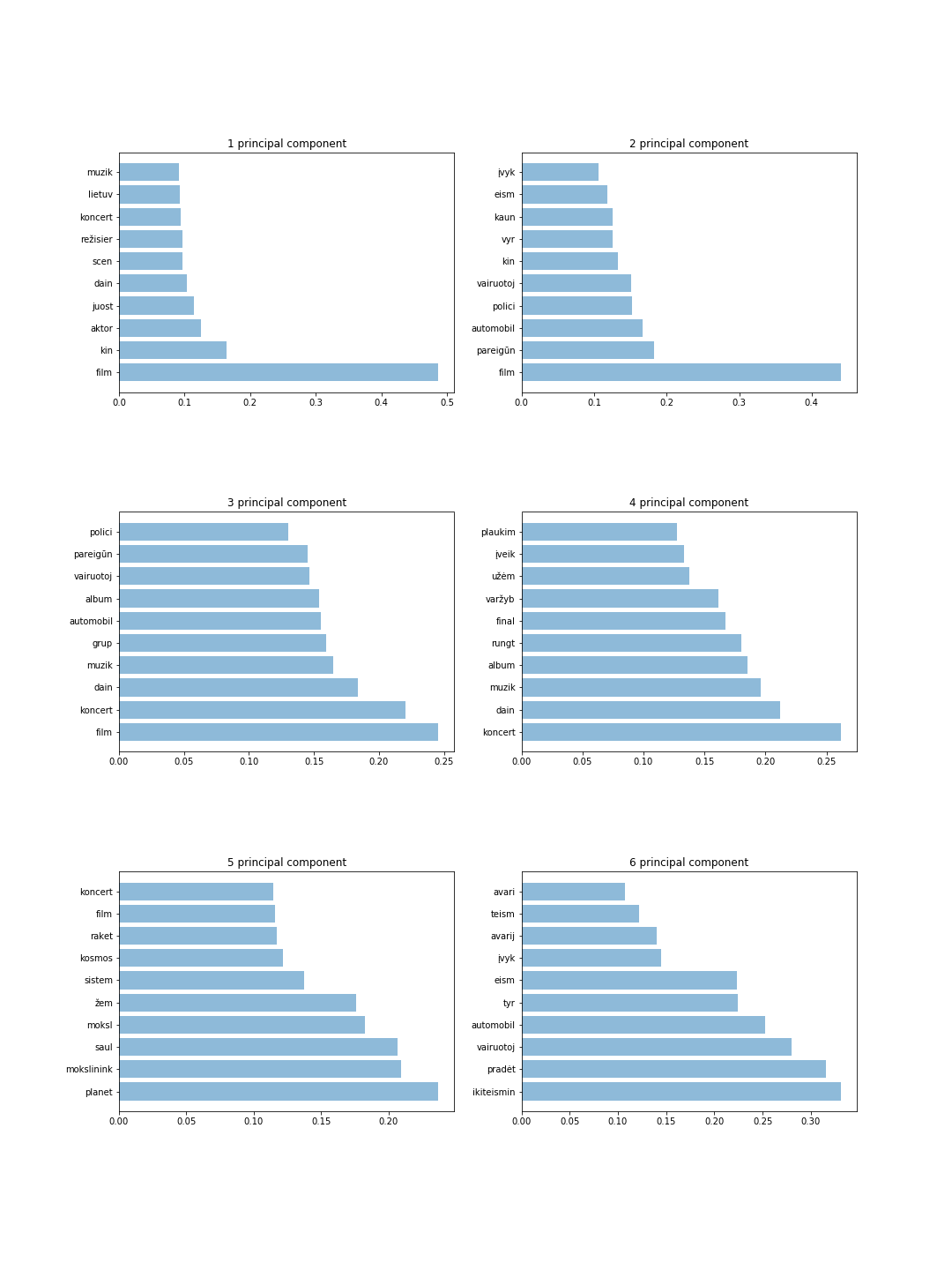
Поиск основан на статье http://webhome.cs.uvic.ca/~thomo/svd.pdf, где lsa применяется для поиска связанных документов, используя не только точное сходство запросов, но и более глубокие связи между документами. 
Запрос = "švietim apdovanojam"
Результат:
В процессе


