
В этом репозитории содержатся вопросы и упражнения по различным техническим темам, иногда связанным с DevOps и SRE.
На данный момент 2624 упражнений и вопросов.
️ Вы можете использовать их для подготовки к собеседованию, но большинство вопросов и упражнений не представляют собой настоящее собеседование. Пожалуйста, прочитайте страницу часто задаваемых вопросов для более подробной информации.
? Если вы заинтересованы в карьере инженера DevOps, изучение некоторых концепций, упомянутых здесь, будет полезно, но вы должны знать, что речь идет не об изучении всех тем и технологий, упомянутых в этом репозитории.
Вы можете добавить больше упражнений, отправив запрос на включение :) О правилах участия читайте здесь.

DevOps | 
Гит | 
Сеть | 
Аппаратное обеспечение | 
Кубернетес |

Разработка программного обеспечения | 
Питон | 
Идти | 
Перл | 
регулярное выражение |

Облако | 
АВС | 
Лазурный | 
Облачная платформа Google | 
OpenStack |

Операционная система | 
Линукс | 
Виртуализация | 
DNS | 
Сценарии оболочки |

Базы данных | 
SQL | 
Монго | 
Тестирование | 
Большие данные |

CI/CD | 
Сертификаты | 
Контейнеры | 
Опеншифт | 
Хранилище |

Терраформировать | 
Кукольный | 
Распределенный | 
Вопросы, которые вы можете задать | 
Анзибль |

Наблюдаемость | 
Прометей | 
Круг CI | 
| 
Графана |

Арго | 
Мягкие навыки | 
Безопасность | 
Проектирование системы |

Хаос-Инжиниринг | 
Разное | 
Эластичный | 
Кафка | 
NodeJs |
Сеть
Вообще, что нужно для общения?
- Общий язык (для понимания обеих сторон).
- Способ обращения к тому, с кем вы хотите общаться, с помощью
- A Connection (чтобы содержимое сообщения могло дойти до получателей).
Что такое TCP/IP?
Набор протоколов, определяющих, как два или более устройств могут взаимодействовать друг с другом.
Чтобы узнать больше о TCP/IP, читайте здесь.
Что такое Ethernet?
Ethernet просто относится к наиболее распространенному типу локальной сети (LAN), используемому сегодня. LAN — в отличие от WAN (глобальной сети), которая охватывает большую географическую территорию, — это объединенная сеть компьютеров на небольшой территории, например, в вашем офисе, кампусе колледжа или даже дома.
Что такое MAC-адрес? Для чего он используется?
MAC-адрес — это уникальный идентификационный номер или код, используемый для идентификации отдельных устройств в сети.
Пакеты, отправляемые по Ethernet, всегда поступают с MAC-адреса и отправляются на MAC-адрес. Если сетевой адаптер получает пакет, он сравнивает MAC-адрес назначения пакета с собственным MAC-адресом адаптера.
Когда используется этот MAC-адрес?: ff:ff:ff:ff:ff:ff
Когда устройство отправляет пакет на широковещательный MAC-адрес (FF:FF:FF:FF:FF:FF), он доставляется всем станциям в локальной сети. Широковещательные передачи Ethernet используются для преобразования IP-адресов в MAC-адреса (по ARP) на уровне канала передачи данных.
Что такое IP-адрес?
Адрес интернет-протокола (IP-адрес) — это числовая метка, присваиваемая каждому устройству, подключенному к компьютерной сети, которая использует интернет-протокол для связи. IP-адрес выполняет две основные функции: идентификацию хоста или сетевого интерфейса и адресацию местоположения.
Объясните маску подсети и приведите пример.
Маска подсети — это 32-битное число, которое маскирует IP-адрес и делит IP-адреса на сетевые адреса и адреса хостов. Маска подсети создается путем установки всех битов сети на «1» и установки битов хоста на все «0». В данной сети из общего количества используемых адресов хостов два всегда зарезервированы для определенных целей и не могут быть выделены ни одному хосту. Это первый адрес, который зарезервирован как сетевой адрес (он же идентификатор сети), и последний адрес, используемый для сетевой трансляции.
Пример
Что такое частный IP-адрес? В каких сценариях/проектах систем его следует использовать?
Частные IP-адреса назначаются узлам в одной сети для связи друг с другом. Как следует из названия «частное», устройства, которым назначены частные IP-адреса, не могут быть доступны устройствам из любой внешней сети. Например, если я живу в общежитии и хочу, чтобы мои товарищи по общежитию присоединились к игровому серверу, который я разместил, я попрошу их присоединиться через частный IP-адрес моего сервера, поскольку сеть является локальной для общежития. Что такое публичный IP-адрес? В каких сценариях/проектах систем его следует использовать?
Публичный IP-адрес — это общедоступный IP-адрес. Если вы размещали игровой сервер, к которому вы хотите, чтобы ваши друзья присоединились, вы предоставите своим друзьям свой общедоступный IP-адрес, чтобы их компьютеры могли идентифицировать и определить местонахождение вашей сети и сервера для установления соединения. Один раз, когда вам не понадобится использовать общедоступный IP-адрес, это если вы играете с друзьями, которые были подключены к той же сети, что и вы, в этом случае вы будете использовать частный IP-адрес. Чтобы кто-то мог подключиться к вашему внутреннему серверу, вам нужно будет настроить переадресацию порта, чтобы сообщить маршрутизатору, что он разрешает трафик из общедоступного домена в вашу сеть и наоборот. Объясните модель OSI. Какие слои существуют? За что отвечает каждый слой?
- Приложение: пользовательская сторона (HTTP находится здесь).
- Представление: устанавливает контекст между объектами уровня приложения (здесь находится шифрование).
- Сеанс: устанавливает, управляет и завершает соединения.
- Транспорт: передает последовательности данных переменной длины от источника к хосту назначения (TCP). & UDP находятся здесь)
- Сеть: передает дейтаграммы из одной сети в другую (здесь IP).
- Канал передачи данных: обеспечивает связь между двумя напрямую соединенными узлами (здесь MAC).
- Физический: электрические и физические характеристики соединения для передачи данных (биты здесь)
Подробнее о модели OSI можно прочитать на сайте penguintutor.com.
Для каждого из следующих параметров определяется, к какому уровню OSI оно принадлежит:- Исправление ошибок
- Маршрутизация пакетов
- Кабели и электрические сигналы
- MAC-адрес
- IP-адрес
- Завершить соединения
- трехстороннее рукопожатие
Исправление ошибок - Маршрутизация пакетов канала передачи данных - Сетевые кабели и электрические сигналы - Физический MAC-адрес - IP-адрес канала передачи данных - Сетевые оконечные соединения - Сеанс Трехстороннее рукопожатие - Транспорт Какие схемы доставки вам известны?
Одноадресная рассылка: индивидуальная связь, при которой есть один отправитель и один получатель.
Широковещательная рассылка: отправка сообщения всем в сети. Адрес ff:ff:ff:ff:ff:ff используется для трансляции. Двумя распространенными протоколами, использующими широковещательную рассылку, являются ARP и DHCP.
Многоадресная рассылка: отправка сообщения группе подписчиков. Это может быть «один ко многим» или «многие ко многим».
Что такое CSMA/CD? Используется ли он в современных сетях Ethernet?
CSMA/CD означает множественный доступ с контролем несущей/обнаружение конфликтов. Его основной целью является управление доступом к общей среде/шине, где только один хост может передавать данные в определенный момент времени.
Алгоритм CSMA/CD:
Перед отправкой кадра он проверяет, передает ли уже другой хост кадр.- Если никто не передает, начинается передача кадра.
- Если два хоста передают данные одновременно, возникает коллизия.
- Оба хоста прекращают отправку кадра и отправляют всем «сигнал застревания», уведомляющий всех о том, что произошел конфликт.
- Они ждут случайное время, прежде чем отправить его снова.
- Как только каждый хост ждет случайное время, он пытается отправить кадр еще раз, и цикл начинается снова.
Опишите следующие сетевые устройства и разницу между ними:- маршрутизатор
- выключатель
- центр
Маршрутизатор, коммутатор и концентратор — это сетевые устройства, используемые для подключения устройств в локальной сети (LAN). Однако каждое устройство работает по-разному и имеет свои конкретные варианты использования. Вот краткое описание каждого устройства и различия между ними:
Маршрутизатор: сетевое устройство, которое соединяет несколько сегментов сети вместе. Он работает на сетевом уровне (уровень 3) модели OSI и использует протоколы маршрутизации для направления данных между сетями. Маршрутизаторы используют IP-адреса для идентификации устройств и маршрутизации пакетов данных в правильный пункт назначения.- Коммутатор: сетевое устройство, которое соединяет несколько устройств в локальной сети. Он работает на уровне канала передачи данных (уровень 2) модели OSI и использует MAC-адреса для идентификации устройств и направления пакетов данных в правильный пункт назначения. Коммутаторы позволяют устройствам в одной сети более эффективно взаимодействовать друг с другом и предотвращают конфликты данных, которые могут возникнуть, когда несколько устройств отправляют данные одновременно.
- Концентратор: сетевое устройство, которое соединяет несколько устройств с помощью одного кабеля и используется для подключения нескольких устройств без сегментирования сети. Однако, в отличие от коммутатора, он работает на физическом уровне (уровень 1) модели OSI и просто передает пакеты данных всем подключенным к нему устройствам, независимо от того, является ли устройство предполагаемым получателем или нет. Это означает, что могут возникнуть конфликты данных, и в результате может пострадать эффективность сети. Концентраторы обычно не используются в современных сетевых конфигурациях, поскольку коммутаторы более эффективны и обеспечивают лучшую производительность сети.
Что такое «домен коллизий»?
Домен коллизий — это сегмент сети, в котором устройства потенциально могут мешать друг другу, пытаясь одновременно передавать данные. Когда два устройства передают данные одновременно, это может вызвать конфликт, приводящий к потере или повреждению данных. В домене коллизий все устройства используют одну и ту же полосу пропускания, и любое устройство потенциально может мешать передаче данных другими устройствами. Что такое «широковещательный домен»?
Широковещательный домен — это сегмент сети, в котором все устройства могут взаимодействовать друг с другом посредством отправки широковещательных сообщений. Широковещательное сообщение — это сообщение, которое отправляется всем устройствам в сети, а не конкретному устройству. В широковещательном домене все устройства могут получать и обрабатывать широковещательные сообщения независимо от того, предназначалось ли им это сообщение или нет. три компьютера, подключенные к коммутатору. Сколько существует доменов коллизий? Сколько широковещательных доменов?
Три домена коллизий и один широковещательный домен
Как работает роутер?
Маршрутизатор — это физическое или виртуальное устройство, которое передает информацию между двумя или более компьютерными сетями с коммутацией пакетов. Маршрутизатор проверяет адрес Интернет-протокола назначения данного пакета данных (IP-адрес), вычисляет лучший способ достижения пункта назначения, а затем соответствующим образом пересылает его.
Что такое НАТ?
Трансляция сетевых адресов (NAT) — это процесс, в котором один или несколько локальных IP-адресов преобразуются в один или несколько глобальных IP-адресов и наоборот, чтобы обеспечить доступ в Интернет локальным хостам.
Что такое прокси? Как это работает? Для чего нам это нужно?
Прокси-сервер действует как шлюз между вами и Интернетом. Это промежуточный сервер, отделяющий конечных пользователей от веб-сайтов, которые они просматривают.
Если вы используете прокси-сервер, интернет-трафик проходит через прокси-сервер на пути к запрошенному вами адресу. Затем запрос возвращается через тот же прокси-сервер (из этого правила есть исключения), а затем прокси-сервер пересылает вам данные, полученные с сайта.
Прокси-серверы обеспечивают различные уровни функциональности, безопасности и конфиденциальности в зависимости от вашего варианта использования, потребностей или политики компании.
Что такое TCP? Как это работает? Что такое трехстороннее рукопожатие?
Трехстороннее рукопожатие TCP или трехстороннее рукопожатие — это процесс, который используется в сети TCP/IP для установления соединения между сервером и клиентом.
Трехстороннее рукопожатие в основном используется для создания соединения через сокет TCP. Это работает, когда:
Клиентский узел отправляет пакет данных SYN по IP-сети на сервер в той же или внешней сети. Цель этого пакета — узнать/сделать вывод, открыт ли сервер для новых подключений.- Целевой сервер должен иметь открытые порты, которые могут принимать и инициировать новые соединения. Когда сервер получает пакет SYN от клиентского узла, он отвечает и возвращает подтверждение — пакет ACK или пакет SYN/ACK.
- Клиентский узел получает SYN/ACK от сервера и отвечает пакетом ACK.
Что такое задержка туда и обратно или время туда и обратно?
Из Википедии: «время, необходимое для отправки сигнала, плюс время, необходимое для получения подтверждения этого сигнала»
Бонусный вопрос: что такое RTT локальной сети?
Как работает SSL-квитирование?
SSL-квитирование — это процесс, который устанавливает безопасное соединение между клиентом и сервером. Клиент отправляет на сервер сообщение Client Hello, которое включает клиентскую версию протокола SSL/TLS, список криптографических алгоритмов, поддерживаемых клиентом, и случайное значение.- Сервер отвечает сообщением Server Hello, которое включает версию протокола SSL/TLS сервера, случайное значение и идентификатор сеанса.
- Сервер отправляет сообщение сертификата, которое содержит сертификат сервера.
- Сервер отправляет сообщение Server Hello Done, которое указывает, что сервер завершил отправку сообщений для фазы Server Hello.
- Клиент отправляет сообщение Client Key Exchange, которое содержит открытый ключ клиента.
- Клиент отправляет сообщение «Изменить спецификацию шифрования», которое уведомляет сервер о том, что клиент собирается отправить сообщение, зашифрованное с помощью новой спецификации шифрования.
- Клиент отправляет зашифрованное сообщение рукопожатия, которое содержит секрет предварительного мастера, зашифрованный открытым ключом сервера.
- Сервер отправляет сообщение «Изменить спецификацию шифрования», которое уведомляет клиента о том, что сервер собирается отправить сообщение, зашифрованное с помощью новой спецификации шифрования.
- Сервер отправляет зашифрованное сообщение рукопожатия, которое содержит предварительный секрет, зашифрованный открытым ключом клиента.
- Клиент и сервер теперь могут обмениваться данными приложения.
В чем разница между TCP и UDP?
TCP устанавливает соединение между клиентом и сервером, чтобы гарантировать порядок пакетов, с другой стороны, UDP не устанавливает соединение между клиентом и сервером и не обрабатывает заказы пакетов. Это делает UDP более легким, чем TCP, и идеальным кандидатом для таких сервисов, как потоковая передача.
Penguintutor.com дает хорошее объяснение.
Какие протоколы TCP/IP вы знаете?
Объясните «шлюз по умолчанию»
Шлюз по умолчанию служит точкой доступа или IP-маршрутизатором, который сетевой компьютер использует для отправки информации на компьютер в другой сети или в Интернете.
Что такое АРП? Как это работает?
ARP означает протокол разрешения адресов. Когда вы пытаетесь проверить IP-адрес в локальной сети, скажем, 192.168.1.1, ваша система должна преобразовать IP-адрес 192.168.1.1 в MAC-адрес. Это предполагает использование ARP для разрешения адреса, отсюда и его название.
Системы хранят справочную таблицу ARP, в которой хранится информация о том, какие IP-адреса с какими MAC-адресами связаны. При попытке отправить пакет на IP-адрес система сначала сверится с этой таблицей, чтобы узнать, известен ли ей MAC-адрес. Если значение кэшировано, ARP не используется.
Что такое ТТЛ? Что это помогает предотвратить?
TTL (время жизни) — это значение в пакете IP (интернет-протокола), которое определяет, сколько переходов или маршрутизаторов может пройти пакет, прежде чем он будет отброшен. Каждый раз, когда пакет пересылается маршрутизатором, значение TTL уменьшается на единицу. Когда значение TTL достигает нуля, пакет отбрасывается, и отправителю отправляется сообщение ICMP (протокол управляющих сообщений Интернета), указывающее, что срок действия пакета истек.- TTL используется для предотвращения бесконечного обращения пакетов в сети, что может вызвать перегрузку и снизить производительность сети.
- Это также помогает предотвратить попадание пакетов в петли маршрутизации, где пакеты постоянно перемещаются между одним и тем же набором маршрутизаторов, так и не достигнув пункта назначения.
- Кроме того, TTL может использоваться для обнаружения и предотвращения атак с подменой IP-адреса, когда злоумышленник пытается выдать себя за другое устройство в сети, используя ложный или поддельный IP-адрес. Ограничивая количество переходов, которые может пройти пакет, TTL может помочь предотвратить маршрутизацию пакетов в незаконные пункты назначения.
Что такое DHCP? Как это работает?
Он означает протокол динамической конфигурации хоста и назначает хостам IP-адреса, маски подсети и шлюзы. Вот как это работает:
- Хост при входе в сеть транслирует сообщение в поисках DHCP-сервера (DHCP DISCOVER).
- Сообщение с предложением отправляется обратно DHCP-сервером в виде пакета, содержащего время аренды, маску подсети, IP-адреса и т. д. (DHCP OFFER).
- В зависимости от того, какое предложение принято, клиент отправляет ответное широковещательное сообщение, сообщающее об этом всем DHCP-серверам (запрос DHCP).
- Сервер отправляет подтверждение (DHCP ACK).
Подробнее здесь
Можете ли вы иметь два DHCP-сервера в одной сети? Как это работает?
В одной сети можно иметь два DHCP-сервера, однако это не рекомендуется, и важно тщательно их настраивать, чтобы предотвратить конфликты и проблемы с настройкой.
Когда два DHCP-сервера настроены в одной сети, существует риск того, что оба сервера назначат IP-адреса и другие параметры конфигурации сети одному и тому же устройству, что может вызвать конфликты и проблемы с подключением. Кроме того, если DHCP-серверы настроены с разными сетевыми параметрами или параметрами, устройства в сети могут получать конфликтующие или несогласованные параметры конфигурации.- Однако в некоторых случаях может потребоваться наличие двух DHCP-серверов в одной сети, например, в больших сетях, где один DHCP-сервер может быть не в состоянии обрабатывать все запросы. В таких случаях DHCP-серверы можно настроить для обслуживания разных диапазонов IP-адресов или разных подсетей, чтобы они не мешали друг другу.
Что такое SSL-туннелирование? Как это работает?
- Туннелирование SSL (Secure Sockets Layer) — это метод, используемый для установления безопасного зашифрованного соединения между двумя конечными точками через незащищенную сеть, например Интернет. Туннель SSL создается путем инкапсуляции трафика внутри соединения SSL, что обеспечивает конфиденциальность, целостность и аутентификацию.
Вот как работает туннелирование SSL:
Клиент инициирует SSL-соединение с сервером, которое включает процесс установления связи для установления SSL-сеанса.- После установления сеанса SSL клиент и сервер согласовывают параметры шифрования, такие как алгоритм шифрования и длину ключа, а затем обмениваются цифровыми сертификатами для аутентификации друг друга.
- Затем клиент отправляет трафик через туннель SSL на сервер, который расшифровывает трафик и перенаправляет его по назначению.
- Сервер отправляет трафик обратно через туннель SSL клиенту, который расшифровывает трафик и пересылает его приложению.
Что такое розетка? Где можно увидеть список сокетов в вашей системе?
Сокет — это программная конечная точка, обеспечивающая двустороннюю связь между процессами по сети. Сокеты предоставляют стандартизированный интерфейс для сетевого взаимодействия, позволяя приложениям отправлять и получать данные по сети. Чтобы просмотреть список открытых сокетов в системе Linux: netstat -an- Эта команда отображает список всех открытых сокетов, а также их протокол, локальный адрес, внешний адрес и состояние.
Что такое IPv6? Почему нам следует рассматривать возможность его использования, если у нас есть IPv4?
- IPv6 (Интернет-протокол версии 6) — это последняя версия Интернет-протокола (IP), которая используется для идентификации устройств в сети и связи с ними. Адреса IPv6 представляют собой 128-битные адреса и выражаются в шестнадцатеричном формате, например 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
Есть несколько причин, по которым нам следует рассмотреть возможность использования IPv6 вместо IPv4:
Адресное пространство. IPv4 имеет ограниченное адресное пространство, которое во многих частях мира исчерпано. IPv6 обеспечивает гораздо большее адресное пространство, позволяя использовать триллионы уникальных IP-адресов.- Безопасность. IPv6 включает встроенную поддержку IPsec, которая обеспечивает сквозное шифрование и аутентификацию сетевого трафика.
- Производительность. IPv6 включает функции, которые могут помочь улучшить производительность сети, например многоадресную маршрутизацию, которая позволяет отправлять один пакет нескольким адресатам одновременно.
- Упрощенная конфигурация сети. IPv6 включает функции, которые могут упростить настройку сети, например автоконфигурацию без отслеживания состояния, которая позволяет устройствам автоматически настраивать свои собственные адреса IPv6 без необходимости использования DHCP-сервера.
- Лучшая поддержка мобильности. IPv6 включает функции, которые могут улучшить поддержку мобильности, например Mobile IPv6, который позволяет устройствам сохранять свои адреса IPv6 при перемещении между различными сетями.
Что такое ВЛАН?
- VLAN (виртуальная локальная сеть) — это логическая сеть, которая группирует набор устройств в физической сети независимо от их физического местоположения. Сети VLAN создаются путем настройки сетевых коммутаторов для назначения определенного идентификатора VLAN кадрам, отправляемым устройствами, подключенными к определенному порту или группе портов коммутатора.
Что такое МТУ?
MTU означает максимальную единицу передачи. Это размер наибольшего PDU (блока данных протокола), который может быть отправлен за одну транзакцию.
Что произойдет, если вы отправите пакет, размер которого превышает MTU?
С помощью протокола IPv4 маршрутизатор может фрагментировать PDU, а затем отправить весь фрагментированный PDU посредством транзакции.
При использовании протокола IPv6 на компьютер пользователя выдается ошибка.
Правда или ложь? Ping использует UDP, потому что ему не важно надежное соединение.
ЛОЖЬ. Ping на самом деле использует ICMP (Протокол управляющих сообщений Интернета), который представляет собой сетевой протокол, используемый для отправки диагностических сообщений и управляющих сообщений, связанных с сетевой связью.
Что такое СДН?
SDN означает программно-определяемую сеть. Это подход к управлению сетью, который подчеркивает централизацию управления сетью, позволяя администраторам управлять поведением сети с помощью программной абстракции.- В традиционной сети сетевые устройства, такие как маршрутизаторы, коммутаторы и межсетевые экраны, настраиваются и управляются индивидуально с использованием специализированного программного обеспечения или интерфейсов командной строки. SDN, напротив, отделяет плоскость управления сетью от плоскости данных, позволяя администраторам управлять поведением сети через централизованный программный контроллер.
Что такое ICMP? Для чего он используется?
- ICMP означает протокол управляющих сообщений Интернета. Это протокол, используемый для целей диагностики и управления в IP-сетях. Это часть набора интернет-протоколов, работающая на сетевом уровне.
Сообщения ICMP используются для различных целей, в том числе:
Отчеты об ошибках: сообщения ICMP используются для сообщения об ошибках, возникающих в сети, например о пакете, который не удалось доставить по назначению.- Ping: ICMP используется для отправки ping-сообщений, которые используются для проверки доступности хоста или сети и для измерения времени прохождения пакетов туда и обратно.
- Обнаружение MTU пути: ICMP используется для обнаружения максимального блока передачи (MTU) пути, который представляет собой наибольший размер пакета, который может быть передан без фрагментации.
- Traceroute: ICMP используется утилитой трассировки для отслеживания пути, по которому пакеты проходят через сеть.
- Обнаружение маршрутизатора: ICMP используется для обнаружения маршрутизаторов в сети.
Что такое НАТ? Как это работает?
NAT означает трансляцию сетевых адресов. Это способ сопоставить несколько локальных частных адресов с общедоступным перед передачей информации. Организации, которые хотят, чтобы несколько устройств использовали один IP-адрес, используют NAT, как и большинство домашних маршрутизаторов. Например, частный IP-адрес вашего компьютера может быть 192.168.1.100, но ваш маршрутизатор сопоставляет трафик со своим общедоступным IP-адресом (например, 1.1.1.1). Любое устройство в Интернете будет видеть трафик, исходящий с вашего общедоступного IP-адреса (1.1.1.1), а не с вашего частного IP-адреса (192.168.1.100).
Какой номер порта используется в каждом из следующих протоколов?:- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- FTP
- SFTP
СШ-22- SMTP-25
- HTTP-80
- ДНС - 53
- HTTPS-443
- ФТП-21
- СФТП-22
Какие факторы влияют на производительность сети?
На производительность сети могут повлиять несколько факторов, в том числе:
Пропускная способность: доступная пропускная способность сетевого подключения может существенно повлиять на его производительность. Сети с ограниченной пропускной способностью могут иметь низкую скорость передачи данных, большие задержки и плохую скорость реагирования.- Задержка: Задержка относится к задержке, которая возникает при передаче данных из одной точки сети в другую. Высокая задержка может привести к снижению производительности сети, особенно для приложений реального времени, таких как видеоконференции и онлайн-игры.
- Перегрузка сети. Когда слишком много устройств одновременно используют сеть, может возникнуть перегрузка сети, что приводит к снижению скорости передачи данных и снижению производительности сети.
- Потеря пакетов. Потеря пакетов происходит, когда пакеты данных теряются во время передачи. Это может привести к снижению скорости сети и снижению общей производительности сети.
- Топология сети. Физическая схема сети, включая размещение коммутаторов, маршрутизаторов и других сетевых устройств, может влиять на производительность сети.
- Сетевой протокол. Различные сетевые протоколы имеют разные характеристики производительности, что может влиять на производительность сети. Например, TCP — это надежный протокол, который может гарантировать доставку данных, но он также может привести к снижению производительности из-за дополнительных затрат, необходимых для проверки ошибок и повторной передачи.
- Сетевая безопасность. Меры безопасности, такие как брандмауэры и шифрование, могут повлиять на производительность сети, особенно если они требуют значительной вычислительной мощности или приводят к дополнительной задержке.
- Расстояние. Физическое расстояние между устройствами в сети может повлиять на производительность сети, особенно для беспроводных сетей, где уровень сигнала и помехи могут влиять на скорость подключения и передачи данных.
Что такое АПИПА?
APIPA — это набор IP-адресов, которые назначаются устройствам, когда основной DHCP-сервер недоступен.
Какой диапазон IP-адресов использует APIPA?
APIPA использует диапазон IP-адресов: 169.254.0.1 – 169.254.255.254.
Плоскость управления и плоскость данных
Что означает «плоскость управления»?
Плоскость управления — это часть сети, которая решает, как маршрутизировать и пересылать пакеты в другое место.
Что означает «плоскость данных»?
Плоскость данных — это часть сети, которая фактически пересылает данные/пакеты.
Что означает «плоскость управления»?
Это относится к функциям мониторинга и управления.
К какой плоскости (данные, управление,...) относится создание таблиц маршрутизации?
Плоскость управления.
Объясните протокол связующего дерева (STP).
Что такое агрегация ссылок? Почему он используется?
Что такое асимметричная маршрутизация? Как с этим справиться?
Какие оверлейные (туннельные) протоколы вам известны?
Что такое ГРЭ? Как это работает?
Что такое VXLAN? Как это работает?
Что такое СНАТ?
Объясните OSPF.
OSPF (сначала открывайте кратчайший путь) — это протокол маршрутизации, который может быть реализован на маршрутизаторах различных типов. В целом OSPF поддерживается большинством современных маршрутизаторов, в том числе таких производителей, как Cisco, Juniper и Huawei. Протокол предназначен для работы с сетями на базе IP, включая IPv4 и IPv6. Кроме того, он использует иерархическую структуру сети, в которой маршрутизаторы сгруппированы в области, причем каждая область имеет свою собственную карту топологии и таблицу маршрутизации. Такая конструкция помогает уменьшить объем маршрутной информации, которой необходимо обмениваться между маршрутизаторами, и улучшить масштабируемость сети.
Типы маршрутизаторов OSPF 4:
- Внутренний маршрутизатор
- Граничные маршрутизаторы области
- Автономные системы Граничные маршрутизаторы
- Магистральные маршрутизаторы
Узнайте больше о типах маршрутизаторов OSPF: https://www.educba.com/ospf-router-types/.
Что такое задержка?
Задержка — это время, необходимое для того, чтобы информация достигла места назначения от источника.
Что такое пропускная способность?
Пропускная способность — это способность канала связи измерять, какой объем данных он может обработать за определенный период времени. Большая пропускная способность будет означать большую обработку трафика и, следовательно, большую передачу данных.
Что такое пропускная способность?
Пропускная способность относится к измерению реального объема данных, передаваемых за определенный период времени по любому каналу передачи.
Что важнее при выполнении поискового запроса: задержка или пропускная способность? И как обеспечить, чтобы мы управляли глобальной инфраструктурой?
Задержка. Чтобы обеспечить хорошую задержку, поисковый запрос должен быть перенаправлен в ближайший центр обработки данных.
Что важнее при загрузке видео: задержка или пропускная способность? И как это гарантировать?
Пропускная способность. Чтобы обеспечить хорошую пропускную способность, поток загрузки должен быть направлен на малоиспользуемый канал.
Какие еще соображения (кроме задержки и пропускной способности) необходимо учитывать при пересылке запросов?
- Постоянно обновляйте кеши (это значит, что запрос может быть перенаправлен не в ближайший дата-центр)
Объясните Spine & Leaf
«Spine & Leaf» — это сетевая топология, обычно используемая в средах центров обработки данных для подключения нескольких коммутаторов и эффективного управления сетевым трафиком. Она также известна как архитектура «хребет-лист» или топология «лист-хребет». Такая конструкция обеспечивает высокую пропускную способность, низкую задержку и масштабируемость, что делает ее идеальной для современных центров обработки данных, обрабатывающих большие объемы данных и трафика. В сети Spine & Leaf существует две основные типологии коммутаторов:
- Коммутаторы Spine. Коммутаторы Spine — это высокопроизводительные коммутаторы, расположенные на уровне позвоночника. Эти коммутаторы действуют как ядро сети и обычно связаны с каждым конечным коммутатором. Каждый магистральный коммутатор подключен ко всем листовым коммутаторам в центре обработки данных.
- Листовые коммутаторы. Листовые коммутаторы подключаются к конечным устройствам, таким как серверы, массивы хранения и другое сетевое оборудование. Каждый листовой коммутатор подключен к каждому коммутатору позвоночника в центре обработки данных. Это создает неблокируемую полносвязную связь между листовыми и магистральными коммутаторами, гарантируя, что любой листовой коммутатор может взаимодействовать с любым другим листовым коммутатором с максимальной пропускной способностью.
Архитектура Spine & Leaf становится все более популярной в центрах обработки данных благодаря ее способности отвечать требованиям современных облачных вычислений, виртуализации и приложений для обработки больших данных, обеспечивая масштабируемую, высокопроизводительную и надежную сетевую инфраструктуру.
Что такое перегрузка сети? Что может вызвать это?
Перегрузка сети возникает, когда в сети слишком много данных для передачи, и у нее недостаточно возможностей для обработки спроса.
Это может привести к увеличению задержки и потере пакетов. Причин может быть несколько, например, высокая загрузка сети, передача больших файлов, вредоносное ПО, проблемы с оборудованием или проблемы с проектированием сети.
Чтобы предотвратить перегрузку сети, важно отслеживать использование сети и реализовывать стратегии по ограничению или управлению спросом.
Что вы можете рассказать мне о формате пакетов UDP? А как насчет формата TCP-пакета? Чем это отличается?
Что такое алгоритм экспоненциальной отсрочки? Где он используется?
Используя код Хэмминга, каким будет кодовое слово для следующего слова данных 100111010001101?
00110011110100011101
Приведите примеры протоколов, встречающихся на прикладном уровне.
Протокол передачи гипертекста (HTTP) — используется для веб-страниц в Интернете.- Простой протокол передачи почты (SMTP) — передача электронной почты
- Телекоммуникационная сеть — (TELNET) — эмуляция терминала, позволяющая клиенту получить доступ к серверу telnet.
- Протокол передачи файлов (FTP) — облегчает передачу файлов между любыми двумя компьютерами.
- Система доменных имен (DNS) — перевод доменных имен
- Протокол динамической конфигурации хоста (DHCP) — распределяет хостам IP-адреса, маски подсети и шлюзы.
- Простой протокол управления сетью (SNMP) — собирает данные об устройствах в сети.
Приведите примеры протоколов сетевого уровня.
Интернет-протокол (IP) — помогает маршрутизировать пакеты с одного компьютера на другой.- Протокол управляющих сообщений Интернета (ICMP) — позволяет узнать, что происходит, например, сообщения об ошибках и отладочная информация.
Что такое ХСТС?
HTTP Strict Transport Security — это директива веб-сервера, которая сообщает пользовательским агентам и веб-браузерам, как обрабатывать его соединение, через заголовок ответа, отправленный в самом начале и обратно в браузер. Это приводит к принудительному подключению через шифрование HTTPS, игнорируя любой вызов сценария для загрузки любого ресурса в этом домене через HTTP. Подробнее читайте [здесь](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS и%20обратно%20к%20%20браузеру.)
Сеть – разное
Что такое Интернет? Это то же самое, что Всемирная паутина?
Интернет — это сеть сетей, передающая огромные объемы данных по всему миру.
Всемирная паутина — это приложение, работающее на миллионах серверов поверх Интернета, доступ к которому осуществляется через так называемый веб-браузер.
Что такое интернет-провайдер?
ISP (Интернет-провайдер) — местная интернет-компания-провайдер.
Операционная система
Упражнения по операционной системе
| Имя | Тема | Цель и инструкции | Решение | Комментарии |
|---|
| Вилка 101 | Вилка | Связь | Связь | |
| Вилка 102 | Вилка | Связь | Связь | |
Операционная система - самооценка
Что такое операционная система?
Из книги «Операционные системы: три простых произведения»:
«Отвечает за то, чтобы упростить запуск программ (даже позволяя вам, по -видимому, запускать многие одновременно), позволяя программам делиться памятью, позволяя программам взаимодействовать с устройствами и другими забавными вещами».
Операционная система - процесс
Вы можете объяснить, что такое процесс?
Процесс - это работающая программа. Программа представляет собой одну или несколько инструкций, а программа (или процесс) выполняется операционной системой.
Если бы вам пришлось разработать API для процессов в операционной системе, как бы выглядел этот API?
Это поддержало бы следующее:
Создать - разрешить создавать новые процессы- Удалить - позвольте удалить/уничтожить процессы
- Состояние - разрешить проверить состояние процесса, будь то работает, останавливается, ожидание и т. Д.
- Остановите - позвольте остановить процесс работы
Как создан процесс?
ОС проходит код программы и любые дополнительные соответствующие данные- Код программы загружается в память или более конкретно, в адресное пространство процесса.
- Память выделена на стек программы (он же стек времени выполнения). Стек также инициализированной ОС с такими данными, как ARGV, ARGC и параметры To Main ()
- Память выделена для кучи программы, которая требуется для динамически выделенных данных, таких как Связанные списки структуры данных и хэш -таблицы
- Задачи инициализации ввода/вывода выполняются, как в системах на основе Unix/Linux, где каждый процесс имеет 3 файловых дескриптора (вход, вывод и ошибка)
- ОС запускает программу, начиная с Main ()
Правда или ложь? Загрузка программы в память выполняется с нетерпением (все сразу)
ЛОЖЬ. Это было верно в прошлом, но сегодняшние операционные системы выполняют ленивую загрузку, что означает, что сначала загружаются только соответствующие части, необходимые для запуска процесса.
Каковы разные состояния процесса?
Запуск - это выполняет инструкции- Готов - он готов к бегу, но по разным причинам это приостановлено
- Заблокировано - он ждет выполнения какой -то операции, например, запрос на диск ввода/вывода
Каковы некоторые причины для заблокированного процесса?
Операции ввода/вывода (например, чтение с диска)- В ожидании пакета из сети
Что такое коммуникация между процессами (IPC)?
Межпроцессная связь (IPC) относится к механизмам, предоставленным операционной системой, которые позволяют процессам управлять общими данными.
Что такое «разделение времени»?
Даже при использовании системы с одним физическим процессором можно позволить нескольким пользователям работать над ней и запускать программы. Это возможно при обмене временем, где вычислительные ресурсы используются таким образом, как это кажется пользователю, система имеет несколько процессоров, но на самом деле это просто один процессор, используемый путем применения многопрограммирования и многозадачности.
Что такое «совместное использование пространства»?
В некоторой степени противоположность времени делясь. В то время как время, разделение ресурса, некоторое время используется одним объектом, а затем один и тот же ресурс может использоваться другим ресурсом, в пространстве, разделение пространства, разделяется несколькими объектами, но таким образом, когда он не передается между ними.
Он используется одной сущностью, пока эта сущность не решит избавиться от нее. Взять, к примеру, хранилище. В хранилище файл ваш, пока вы не решите удалить его.
Какой компонент определяет, какой процесс работает в определенный момент времени?
Планировщик процессора
Операционная система - память
Что такое «виртуальная память» и какую цель служит?
Виртуальная память объединяет оперативную память вашего компьютера с временным пространством на вашем жестком диске. Когда оперативная память работает низко, виртуальная память помогает перемещать данные из ОЗУ в пространство, называемое файлом пейджинг. Перемещение данных в Paging File может освободить оперативную память, поэтому ваш компьютер может завершить свою работу. В целом, чем больше оперативной памяти у вашего компьютера, тем быстрее работают программы. https://www.minitool.com/lib/virtual-memory.html
Что такое подтяжка спроса?
Перепуск спроса - это метод управления памятью, где страницы загружаются в физическую память только при обращении к процессу. Он оптимизирует использование памяти, загружая страницы по требованию, уменьшая задержку запуска и накладные расходы на пространство. Тем не менее, он вводит некоторую задержку при первом доступе к страницам. В целом, это экономически эффективный подход для управления ресурсами памяти в операционных системах.
Что такое копия на записи?
Copy-on Write (корова)-это концепция управления ресурсами, с целью уменьшить ненужное копирование информации. Это концепция, которая реализована, например, в Sopix Fork Syscall, которая создает дублированный процесс процесса вызова. Идея:
Если ресурсы разделяются между 2 или более организациями (например, общие сегменты памяти между 2 процессами), ресурсы не должны копировать для каждого объекта, а скорее у каждого объекта есть разрешение на операцию на чтении по общему ресурсу. (Общие сегменты отмечены как только для чтения) (подумайте о каждой организации, имеющей указатель на местоположение общего ресурса, который можно было бы бездействовать, чтобы прочитать ее стоимость)- Если одна организация выполнит операцию записи на общем ресурсе, возникнет проблема, поскольку ресурс также будет постоянно изменен для всех других организаций, которые разделяют его. (Подумайте о процессе, изменяющем некоторые переменные в стеке, или динамически распределить некоторые данные на кучу, эти изменения в общем ресурсе также будут применяться для всех других процессов, это определенно нежелательное поведение)
- Только в качестве решения, если операция записи будет выполнена на общем ресурсе, сначала этот ресурс скопируется, а затем применяются изменения.
Что такое ядро и что он делает?
Ядро является частью операционной системы и отвечает за такие задачи, как:
Распределяя память- Расписание процессов
- Управлять процессором
Правда или ложь? Некоторые части кода в ядре загружаются в охраняемые области памяти, поэтому приложения не могут их перезаписать.
Истинный
Что такое POSIX?
POSIX (портативная операционная система)-это набор стандартов, которые определяют интерфейс между UNIX-подобной операционной системой и прикладными программами.
Объясните, что такое семафор и какова его роль в операционных системах.
Семфор - это примитив синхронизации, используемый в операционных системах, и одновременное программирование для контроля доступа к общим ресурсам. Это переменная или абстрактный тип данных, который действует как счетчик или механизм сигнализации для управления доступом к ресурсам с помощью нескольких процессов или потоков.
Что такое кеш? Что такое буфер?
Кэш: кэш обычно используется, когда процессы читают и записывают на диск, чтобы сделать процесс быстрее, делая аналогичные данные, используемые различными программами, легко доступными. Буфер: зарезервированное место в оперативной памяти, которая используется для хранения данных для временных целей.
Виртуализация
Что такое виртуализация?
Виртуализация использует программное обеспечение для создания уровня абстракции по сравнению с компьютерным оборудованием, которое позволяет аппаратным элементам одного компьютера - процессоров, памяти, хранения и многого другого - быть разделенным на несколько виртуальных компьютеров, обычно называемых виртуальными машинами (VMS).
Что такое гипервизор?
Red Hat: «Гипервизор - это программное обеспечение, которое создает и запускает виртуальные машины (виртуальные машины). Гипервизор, иногда называемый монитором виртуальной машины (VMM), изолирует операционную систему и ресурсы гипервизора от виртуальных машин и обеспечивает создание и управление этим Виртуальные машины. "
Прочитайте больше здесь
Какие виды гипервизоров есть?
Размещенные гипервизоры и гипервизоры с голой металлом.
Каковы преимущества и недостатки гипервизора с обнаженным металлом по сравнению с проведенным гипервизором?
Из -за наличия своих собственных драйверов и прямого доступа к аппаратным компонентам, у гипервизора Baremetal часто будут лучшие результаты, наряду со стабильностью и масштабируемостью.
С другой стороны, вероятно, будет некоторое ограничение в отношении погрузки (любого) драйверов, так что разнимавшийся гипервизор обычно выиграл от лучшей совместимости аппаратного обеспечения.
Какие виды виртуализации существуют?
Виртуализация операционной системы Виртуализация Виртуализация виртуализация настольной настольной работы
Контейнеризация является типом виртуализации?
Да, это виртуализация на уровне операционной системы, где общее ядро и позволяет использовать несколько изолированных экземпляров пользовательских пространств.
Как внедрение виртуальных машин изменило отрасль и то, как были развернуты приложения?
Внедрение виртуальных машин позволило компаниям развернуть несколько бизнес -приложений на одном и том же аппаратном обеспечении, в то время как каждое приложение отделено друг от друга защищенным образом, где каждый работает в своей отдельной операционной системе.
Виртуальные машины
Нужны ли нам виртуальные машины в эпоху контейнеров? Они все еще актуальны?
Да, виртуальные машины все еще актуальны даже в эпоху контейнеров. В то время как контейнеры обеспечивают легкую и портативную альтернативу виртуальным машинам, они имеют определенные ограничения. Виртуальные машины по -прежнему имеют значение, потому что они предлагают изоляцию и безопасность, могут запускать различные операционные системы и полезны для устаревших приложений. Например, ограничения контейнеров - это разделение ядра хоста.
Прометей
Что такое Prometheus? Каковы некоторые из основных особенностей Прометея?
Prometheus-это популярный мониторинг систем с открытым исходным кодом и оповещение, изначально разработанный в SoundCloud. Он предназначен для сбора и хранения данных временных рядов, а также для проведения запросов и анализа этих данных с использованием мощного языка запросов под названием PROMQL. Прометей часто используется для мониторинга облачных приложений, микросервисов и другой современной инфраструктуры.
Некоторые из основных особенностей Прометея включают:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
В целом, Prometheus является мощным и гибким инструментом для мониторинга и анализа систем и приложений, и широко используется в отрасли для мониторинга и наблюдаемости облачного костюма.
В каких сценариях может быть лучше не использовать Prometheus?
От документации Prometheus: «Если вам нужна 100% точность, например, для выставления счетов за просмотр».
Опишите архитектуру и компоненты Prometheus
Архитектура Прометея состоит из четырех основных компонентов:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
В целом, архитектура Prometheus предназначена для того, чтобы быть очень масштабируемым и устойчивым. Сервер и клиентские библиотеки могут быть развернуты распределенным образом для поддержки мониторинга в крупномасштабных, высоко динамических средах
Можете ли вы сравнить Prometheus с другими решениями, например, PlupuxDB?
По сравнению с другими решениями по мониторингу, таким как InfluxDB, Prometheus известен своей высокой производительностью и масштабируемостью. Он может обрабатывать большие объемы данных и может быть легко интегрирован с другими инструментами в экосистеме мониторинга. Influxdb, с другой стороны, известен своей простотой использования и простотой. Он имеет удобный интерфейс и предоставляет простые в использовании API для сбора и запроса данных.
Другое популярное решение, Nagios, представляет собой более традиционную систему мониторинга, которая опирается на модель на основе Push для сбора данных. Нагиос существует уже давно и известен своей стабильностью и надежностью. Однако, по сравнению с Прометеем, у Нагиоса не хватает некоторых из наиболее продвинутых функций, таких как многомерная модель данных и мощный язык запросов.
В целом, выбор решения для мониторинга зависит от конкретных потребностей и требований организации. В то время как Prometheus является отличным выбором для крупномасштабного мониторинга и оповещения, InfluxDB может лучше подходить для меньших сред, которые требуют простоты использования и простоты. Нагиос остается надежным выбором для организаций, которые определяют приоритеты стабильности и надежности по сравнению с расширенными функциями.
Что такое предупреждение?
В Prometheus предупреждение - это уведомление, запускаемое при выполнении конкретного условия или порога. Оповещения могут быть настроены на триггер, когда определенные метрики пересекают определенный порог или когда происходят конкретные события. После того, как предупреждение запускается, его можно направить на различные каналы, такие как электронная почта, пейджер или чат, чтобы уведомить соответствующие команды или отдельных лиц о том, чтобы они предприняли соответствующие действия. Оповещения являются критически важным компонентом любой системы мониторинга, поскольку они позволяют командам активно обнаруживать и реагировать на проблемы, прежде чем они повлияют на пользователей или вызывают время простоя системы. Что такое экземпляр? Что такое работа?
В Prometheus экземпляр относится к единственной цели, которая контролируется. Например, один сервер или служба. Задание - это набор экземпляров, которые выполняют ту же функцию, такие как набор веб -серверов, обслуживающих одно и то же приложение. Работа позволяет вам определить и управлять группой целей вместе.
По сути, экземпляр - это индивидуальная цель, из которой Прометей собирает метрики, в то время как работа - это набор аналогичных случаев, которыми можно управлять как группа.
Какие основные типы метрик поддерживают Prometheus?
Прометей поддерживает несколько типов метрик, в том числе: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Прометей также поддерживает различные функции и операторы для агрегирования и манипулирования метрик, таких как сумма, максимум, мин и скорость. Эти функции делают его мощным инструментом для мониторинга и оповещения о метрик системы.
Что такое экспортер? Для чего он используется?
Экспортер служит мостом между сторонней системой или приложением и Prometheus, что позволяет Прометеусу контролировать и собирать данные из этой системы или приложения. Экспортер выступает в качестве сервера, прослушивая конкретный сетевой порт для запросов от Прометея до метриков скрещивания. Он собирает метрики из сторонней системы или приложения и превращает их в формат, который может быть понят Prometheus. Затем экспортер обнажает эти метрики для Прометея через конечную точку HTTP, что делает их доступными для сбора и анализа.
Экспортеры обычно используются для мониторинга различных типов компонентов инфраструктуры, таких как базы данных, веб -серверы и системы хранения. Например, есть экспортеры, доступные для мониторинга популярных баз данных, таких как MySQL и PostgreSQL, а также веб -серверы, такие как Apache и Nginx.
В целом, экспортеры являются критически важным компонентом экосистемы Prometheus, что позволяет контролировать широкий спектр систем и приложений, а также обеспечивает высокую степень гибкости и расширяемости для платформы.
Какие лучшие практики Прометея?
Вот три из них: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
Как получить общие запросы в определенный период времени?
Чтобы получить общие запросы в определенный период времени, используя Prometheus, вы можете использовать функцию * sum * вместе с функцией * скорости *. Вот пример запроса, который даст вам общее количество запросов за последний час: sum(rate(http_requests_total[1h]))
В этом запросе http_requests_total -это имя метрики, которая отслеживает общее количество HTTP-запросов, а функция скорости рассчитывает скорость запросов за второй. Затем функция SUM добавляет все запросы, чтобы дать вам общее количество запросов за последний час.
Вы можете настроить диапазон времени, изменив продолжительность функции скорости . Например, если вы хотите получить общее количество запросов в последний день, вы можете изменить функцию на скорость (http_requests_total [1d]) .
Что значит HA в Прометею?
HA означает высокую доступность. Это означает, что система предназначена для того, чтобы быть очень надежным и всегда доступным, даже перед лицом сбоев или других проблем. На практике это обычно включает в себя настройку нескольких экземпляров Prometheus и обеспечение того, чтобы все они были синхронизированы и способны беспрепятственно работать вместе. Это может быть достигнуто с помощью различных методов, таких как балансировка нагрузки, репликация и механизмы аварийного переключения. Внедряя HA в Prometheus, пользователи могут гарантировать, что их данные мониторинга всегда доступны и актуальны, даже под лицом аппаратных или программных сбоев, проблем с сетью или других проблем, которые в противном случае могли бы вызвать время простоя или потери данных.
Как вы присоединяетесь к двум показателям?
В Prometheus присоединение двух метрик может быть достигнуто с помощью функции * join () *. Функция * join () * объединяет два или более временных рядов на основе значений их метки. Требуется два обязательных аргумента: *на *и *таблица *. Аргумент, указывающий этикетки, чтобы присоединиться * на *, а аргумент * Таблица * указывает время для присоединения. Вот пример того, как присоединиться к двум показателям, используя функцию join () :
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
В этом примере функция join () объединяет временные ряды request_count_total и error_count_total на основе их значений метки службы и экземпляра . Функция sum_series () затем вычисляет сумму результирующего временного ряда
Как написать запрос, который возвращает значение метки?
Чтобы написать запрос, который возвращает значение метки в Prometheus, вы можете использовать функцию * label_values *. Функция * label_values * принимает два аргумента: имя метки и имя метрики. Например, если у вас есть метрика, называемая http_requests_total с меткой, называемой методом , и вы хотите вернуть все значения метки метода , вы можете использовать следующий запрос:
label_values(http_requests_total, method)
Это вернет список всех значений для метки метода в метрике http_requests_total . Затем вы можете использовать этот список в дальнейших запросах или для фильтрации ваших данных.
Как конвертировать CPU_USER_SECONDS в использование ЦП в процентах?
Чтобы преобразовать * cpu_user_seconds * в использование процессора в процентах, вам необходимо разделить его на общее время истешенного времени и количество ядер ЦП, а затем умножить на 100. Формула следующая: 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
Здесь, это название работы, которую вы хотите запросить, это диапазон, который вы хотите запросить (например, 5M , 1H ) и Количество ядер ЦП на машине, которую вы запрашиваете.
Например, чтобы получить использование процессора в процентах за последние 5 минут для работы с названием My-Job, работающей на машине с 4 ядрами процессора, вы можете использовать следующий запрос:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
Идти
Каковы некоторые характеристики языка программирования GO?
Сильная и статическая набор - тип переменных не может быть изменен со временем - ,
и - их
- необходимо определить при компиляции
- простота
быстрота, - встроенное
- время компиляции
- .
- будет составлен в один бинар. Очень полезно для управления версиями во время выполнения.
У Go также есть хорошее сообщество.
В чем разница между var x int = 2 и x := 2 ?
Результат такой же, переменная со значением 2.
С помощью var x int = 2 мы устанавливаем тип переменной на целое число, в то время как с x := 2 мы само по себе выясняем тип.
Правда или ложь? В ходе мы можем переоборудовать переменные и после объявления мы должны использовать их.
ЛОЖЬ. Мы не можем восстановить переменные, но да, мы должны использовать объявленные переменные.
Какие библиотеки Go вы использовали?
На это следует ответить на основе вашего использования, но некоторые примеры:
- FMT - форматированный ввод/вывод
В чем проблема со следующим блоком кода? Как это исправить? func main() {
var x float32 = 13.5
var y int
y = x
}
Следующий блок кода пытается преобразовать целое число 101 в строку, но вместо этого мы получаем «E». Почему это? Как это исправить? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
Он смотрит, что значение Unicode установлено на 101, и использует его для преобразования целого числа в строку. Если вы хотите получить «101», вы должны использовать пакет «strconv» и заменить y = string(x) на y = strconv.Itoa(x)
Что не так со следующим кодом?: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
Константы в GO могут быть объявлены только с использованием постоянных выражений. Но x , y и их сумма является переменной.
const initializer x + y is not a constant
Каким будет выход следующего блока кода?: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
Идентификатор IOTA Go используется в объявлениях Const для упрощения определений увеличения чисел. Поскольку его можно использовать в выражениях, он обеспечивает общность за пределами простого перечисления.
x и y в первой группе йота, z во втором.
Iota Page в Go Wiki
Для чего _ используется в Go?
Это избегает объявления всех переменных для значений возврата. Это называется пустым идентификатором.
ответьте так
Каким будет выход следующего блока кода?: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
Поскольку первая йота объявлена со значением 3 ( + 3 ), следующее имеет значение 4
Каким будет выход следующего блока кода?: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
Вывод: 2 1 3
Aritcle о синхронизации/WaitGroup
Golang Package Sync
Каким будет выход следующего блока кода?: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
Выход:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
В mod1 A - это ссылка, и когда мы используем a[i] , мы меняем значение s1 . Но в mod2 append создает новый кусочек, и мы меняем только a , а не s2 .
Aritcle о массивах, в блоге о append
Каким будет выход следующего блока кода?: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
Выход: 3
Golang Container/Heap Package
Монго
Каковы преимущества MongoDB? Или, другими словами, зачем выбрать MongoDB, а не другую реализацию NoSQL?
Преимущества MongoDB связаны с следующими:
- Схема
- Легко масштабировать
- Нет сложных соединений
- Структура одного объекта ясна
В чем разница между SQL и NOSQL?
Основное отличие состоит в том, что базы данных SQL структурированы (данные хранятся в виде таблиц с строками и столбцами - например, таблица электронных таблиц Excel), в то время как NOSQL неразрушен, а хранилище данных может варьироваться в зависимости от того, как настроена DB NOSQL, такие как пара ключей, ориентированная на документ и т. Д.
В каких сценариях вы бы предпочли использовать NOSQL/Mongo над SQL?
Гетерогенные данные, которые часто меняются- Согласованность данных и целостность не являются главным приоритетом
- Лучше всего, если база данных необходимо быстро масштабироваться
Что такое документ? Что такое коллекция?
Документ - это запись в MongoDB, которая хранится в формате BSON (бинарный JSON) и является основной единицей данных в MongoDB.- Коллекция представляет собой группу связанных документов, хранящихся в одной базе данных в MongoDB.
Что такое агрегатор?
- Агрегатор - это структура в MongoDB, которая выполняет операции на наборе данных для возврата одного вычисленного результата.
Что лучше? Встроенные документы или ссылки?
- Нет окончательного ответа, на который лучше, это зависит от конкретного варианта использования и требований. Некоторые объяснения: встраиваемые документы предоставляют атомные обновления, в то время как ссылочные документы допускают лучшую нормализацию.
Вы выполняли оптимизацию поиска данных в Mongo? Если нет, то можете ли вы подумать о способах оптимизации медленного поиска данных?
- Некоторые способы оптимизации поиска данных в MongoDB: индексация, правильная конструкция схемы, оптимизация запросов и баланс нагрузки базы данных.
Запросы
Объясните этот запрос: db.books.find({"name": /abc/})
Объясните этот запрос: db.books.find().sort({x:1})
В чем разница между find () и find_one ()?
find() возвращает все документы, которые соответствуют условиям запроса.- find_one () возвращает только один документ, который соответствует условиям запроса (или нулевым, если совпадение не найдено).
Как вы можете экспортировать данные из Mongo DB?
монгоэкспорт- языки программирования
SQL
Упражнения SQL
| Имя | Тема | Цель и инструкции | Решение | Комментарии |
|---|
| Функции против сравнений | Улучшения запросов | Упражнение | Решение | |
SQL Self Assage
Что такое SQL?
SQL (структурированный язык запросов) - это стандартный язык для реляционных баз данных (например, MySQL, MariaDB, ...).
Он используется для чтения, обновления, удаления и создания данных в реляционной базе данных.
Чем SQL отличается от nosql
Основное отличие состоит в том, что базы данных SQL структурированы (данные хранятся в виде таблиц с строками и столбцами - например, таблица электронных таблиц Excel), в то время как NOSQL неразрушен, а хранилище данных может варьироваться в зависимости от того, как настроена DB NOSQL, такие как пара ключей, ориентированная на документ и т. Д.
Когда лучше использовать SQL? Nosql?
SQL - лучше всего используется, когда целостность данных имеет решающее значение. SQL обычно реализуется со многими предприятиями и областями в области финансов из -за его соблюдения кислоты.
Nosql - Отлично, если вам нужно быстро масштабировать вещи. NOSQL был разработан с учетом веб -приложений, поэтому он отлично работает, если вам нужно быстро распространять одну и ту же информацию на несколько серверов
Кроме того, поскольку NOSQL не придерживается строгой таблицы с столбцами и строками, которые требуются реляционные базы данных, вы можете хранить различные типы данных вместе.
Практический SQL - Основы
Для этих вопросов мы будем использовать таблицы клиентов и заказов, показанные ниже:
Клиенты
| Customer_id | Customer_name | Items_in_cart | Cash_spent_to_date |
|---|
| 100204 | Джон Смит | 0 | 20.00 |
| 100205 | Джейн Смит | 3 | 40.00 |
| 100206 | Бобби Фрэнк | 1 | 100.20 |
ЗАКАЗЫ
| Customer_id | Order_id | Элемент | Цена | Date_sold |
|---|
| 100206 | А123 | Резиновый уток | 2.20 | 2019-09-18 |
| 100206 | А123 | Жемчужная ванна | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80-пак tp | 90.00 | 2019-09-20 |
| 100205 | Z001 | Кошачья корма - рыба из тунца | 10.00 | 2019-08-05 |
| 100205 | Z001 | Кошачья еда - курица | 10.00 | 2019-08-05 |
| 100205 | Z001 | Еда кошек - говядина | 10.00 | 2019-08-05 |
| 100205 | Z001 | Кошка еда - Китти Кесадилья | 10.00 | 2019-08-05 |
| 100204 | X202 | Кофе | 20.00 | 2019-04-29 |
Как я бы выбрал все поля из этой таблицы?
Выбирать *
От клиентов;
Сколько предметов в телеге Джона?
Выберите item_in_cart
От клиентов
Где customer_name = "Джон Смит";
Какова сумма всех денег, потраченных на всех клиентов?
Выберите sum (cash_spent_to_date) как sum_cash
От клиентов;
Сколько людей в своей корзине?
Выберите счет (1) как number_of_people_w_items
От клиентов
где items_in_cart> 0;
Как бы вы присоединились к таблице клиентов в таблицу заказа?
Вы бы присоединились к ним на уникальном ключе. В этом случае уникальный ключ - Customer_id как в таблице клиентов, так и в таблице заказов
Как бы вы показали, какой клиент заказал какие предметы?
Выберите C.Customer_Name, O.Item
От клиентов c
Левые приказы об объединении o
На c.customer_id = o.customer_id;
Используя заявление с With, как бы вы показали, кто заказал кошку и общую сумму потраченных денег?
с cat_food как (
Выберите customer_id, sum (цена) как total_price
Из заказов
Где такая такая такая такая такая такая такая такая такая тарелка%»%»
Группа от customer_id
)
Выберите customer_name, total_price
От клиентов c
Внутренний присоединяйся cat_food f
На c.customer_id = f.customer_id
где c.customer_id in (выберите customer_id из cat_food);
Хотя это было простое утверждение, пункт «с» действительно сияет, когда сложный запрос должен запускать на таблице, прежде чем присоединиться к другому. С операторами хороши, потому что вы создаете псевдо -температуру при выполнении вашего запроса, вместо того, чтобы создавать целую новую таблицу.
Сумма всех закупок Cat Food не была легко доступна, поэтому мы использовали заявление с выбором для создания псевдо -таблицы, чтобы получить сумму цен, потраченных каждым клиентом, затем обычно присоединились к таблице.
Какие из следующих запросов вы бы использовали? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
Когда вы используете функцию ( YEAR(purchased_at) ), она должна сканировать всю базу данных, а не использование индексов, и в основном столбец, как есть, в его естественном состоянии.
OpenStack
С какими компонентами/проектами OpenStack вы знакомы?
Можете ли вы сказать мне, за что отвечает каждая из следующих услуг/проектов?:- Новая звезда
- Нейтрон
- Зола
- Взглянуть мельком
- Ключевой камень
Nova - Управление виртуальными случаями- Neutron - Управление сетью, предоставляя сеть в качестве услуги (NAAS)
- Шлака - блочное хранение
- Взор - управление изображениями для виртуальных машин и контейнеров (поиск, получение и регистрация)
- Keystone - служба аутентификации в облаке
Определите сервис/проект, используемый для каждого из следующих:- Копировать или снимки экземпляров
- GUI для просмотра и изменения ресурсов
- Блокировать хранение
- Управление виртуальными случаями
Гриз - Служба изображений. Также используется для копирования или снимков экземпляров- Horizon - GUI для просмотра и модификации ресурсов
- Шлака - блочное хранение
- Nova - Управление виртуальными случаями
Что такое арендатор/проект?
Определить истину или ложь:- OpenStack бесплатно в использовании
- Сервис, ответственный за сетевые отношения, - это взгляд
- Целью арендатора/проекта является обмен ресурсами между различными проектами и пользователями OpenStack
Подробно опишите, как вы поднимаете экземпляр с плавающей IP
Вы получаете звонок от клиента, говорящего: «Я могу пинговать свой экземпляр, но не могу подключить (SSH) это». В чем может быть проблема?
Какие виды сети поддерживают OpenStack?
Как вы отлаживаете проблемы с хранением OpenStack? (Инструменты, журналы, ...)
Как вы отладки OpenStack вычислили проблемы? (Инструменты, журналы, ...)
OpenStack развертывание и Tripleo
Вы развернули OpenStack в прошлом? Если да, вы можете описать, как вы это сделали?
Вы знакомы с Tripleo? Чем он отличается от Devstack или Packstack?
Вы можете прочитать о Tripleo прямо здесь
OpenStack вычислить
Можете ли вы подробно описать Nova?
Используется для обеспечения и управления виртуальными случаями- Он поддерживает многоцелевое место в разных уровнях-ведение журнала, управление конечным пользователем, аудит и т. Д.
- Высокая масштабируемость
- Аутентификация может быть выполнена с помощью внутренней системы или LDAP
- Поддерживает несколько типов блочного хранилища
- Попытка быть аппаратным и гипервизором Agnostice
Что вы знаете об архитектуре и компонентах Nova?
nova -api - сервер, который обслуживает метаданные и вычисляет API- Различные компоненты Nova общаются, используя очередь (обычно Rabbitmq) и базу данных
- Запрос на создание экземпляра проверяется Nova-Scheduler, который определяет, где будет создан и работает экземпляр
- Nova-Compute-это компонент, ответственный за общение с гипервизором для создания экземпляра и управления его жизненным циклом
OpenStack Networking (Neutron)
Объясните нейтрон подробно
Один из основных компонентов OpenStack и автономного проекта- Нейтрон сосредоточен на предоставлении сети в качестве услуги
- С помощью Neutron пользователи могут настраивать сети в облаке и настраивать и управлять различными сетевыми службами
- Нейтрон взаимодействует с:
Keystone - авторизовать вызовы API
- Nova - Nova общается с Neutron для подключения NICS в сеть
- Horizon - поддерживает сетевые объекты на приборной панели, а также предоставляет топологию, который включает в себя сетевые детали
Объясните каждый из следующих компонентов:- Нейтрон-DHCP-агент
- Neutron-L3-Agent
- Нейтрон-Меторинг-Агент
- Neutron-*-Agtent
- нейтронный сервер
Neutron-L3-Agent-L3/NAT- Neutron-DHCP-Agent-DHCP Services
- Нейтронный метеоринг-агент-L3.
- Neutron-*-Agtent-управляет локальной конфигурацией Vswitch на каждом вычислении (на основе выбранного плагина)
- Neutron -Server - разоблачает сетевые API и передает запросы другим плагинам, если это необходимо.
Объясните эти типы сети:- Управление сетью
- Гостевая сеть
- Сеть API
- Внешняя сеть
Сеть управления - используется для внутренней связи между компонентами OpenStack. Любой IP -адрес в этой сети доступен только в DataCetner- Гостевая сеть - используется для связи между экземплярами/виртуальными машинами
- API Network - используется для Services API Communication. Любой IP -адрес в этой сети общедоступен
- Внешняя сеть - используется для общественного общения. Любой IP -адрес в этой сети доступен всеми в Интернете
В каком порядке вы должны удалить следующие объекты:- Сеть
- Порт
- Маршрутизатор
- Подсеть
- Резучаная
- сеть
- порта
- подсети
Есть много причин для этого. Один, например: вы не можете удалить маршрутизатор, если есть активные порты, назначенные ему.
Что такое сеть поставщиков?
Какие компоненты и услуги существуют для L2 и L3?
Что такое плагин ML2? Объясните его архитектуру
Что такое агент L2? Как это работает и за что это отвечает?
Что такое агент L3? Как это работает и за что это отвечает?
Объясните, за что отвечает агент метаданных
Какие сетевые объекты поддерживают нейтрон?
Как вы отлаживаете проблемы с сетью OpenStack? (Инструменты, журналы, ...)
OpenStack - взгляд
Объясните подробно
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
Правда или ложь? there can be two objects with the same name in the same container but not in two different containers
ЛОЖЬ. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- Роль
- Tenant/Project
- Услуга
- Конечная точка
- Token
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
С использованием:
Имя- ID number
- Тип
- Описание
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- Быстрый
- Сахара
- Иронично
- Находка
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- ПАМ
- Мемкеш
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
Кукольный
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
Эластичный
What is the Elastic Stack?
The Elastic Stack consists of:
- Эластичный поиск
- Кибана
- Logstash
- бьется
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Эластичный поиск
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. Что это значит? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
Правда или ложь? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
ЛОЖЬ. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
_index- _идентификатор
- _тип
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". Что это значит?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? What would you use it for?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
Logstash
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
Кибана
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". Что это значит?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Читать здесь
Правда или ложь? a single harvester harvest multiple files, according to the limits set in filebeat.yml
ЛОЖЬ. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Elastic Stack
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Распределенный
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Сеть- Процессор
- Память
- Disk
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
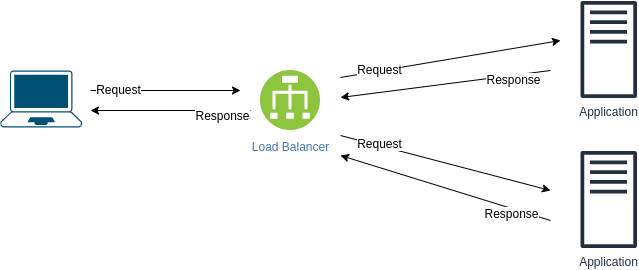
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage, memory, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
Разное
| Имя | Тема | Objective & Instructions | Решение | Комментарии |
|---|
| Highly Available "Hello World" | Упражнение | Решение | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
API
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
Правда или ложь? API Definition is the same as API Specification
ЛОЖЬ. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
Преимущества:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
Авторизация- Ведение журнала
- Аутентификация
- Заказ
- Внешний интерфейс
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Какой из них вы бы использовали? Почему?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
Правда или ложь? Any valid JSON file is also a valid YAML file
Истинный. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
Прошивка
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
Кассандра
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
Что такое http?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP-ответ
Правда или ложь? HTTP is stateful
ЛОЖЬ. It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
ПОЛУЧАТЬ- ПОЧТА
- ГОЛОВА
- ПОМЕЩАТЬ
- УДАЛИТЬ
- СОЕДИНЯТЬ
- ПАРАМЕТРЫ
- СЛЕД
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
Что такое HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. Что это значит?
The server didn't receive a response from another server it communicates with in a timely manner.
Что такое прокси?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Круговая система- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
Минусы:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
Печенье. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Круговая система
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
Лицензии
Are you familiar with "Creative Commons"? Что вы об этом знаете?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
Случайный
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. Источник
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
Хранилище
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
Плюсы:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
Плюсы:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
Тестирование
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
Regex
Given a text file, perform the following exercises
Извлекать
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
Заменять
Replace tabs with four spaces
Replace 'red' with 'green'
Проектирование системы
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. Масштабируемость
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
What is the problem with the following architecture and how would you fix it?
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
Кэш
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
Посмотрите здесь
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrations
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

Аппаратное обеспечение
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
Внешний- Machine check
- ввод/вывод
- Программа
- Перезапуск
- Supervisor call (SVC)
Big Data
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. Правда или ложь? Ceph favor consistency and correctness over performances
Истинный Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
Монитор- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- Менеджер
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? Как это работает?
Packer
What is Packer? Для чего он используется?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
Выпускать
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
Сертификаты
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. Удачи :)
АВС
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
Лазурный
- AZ-900 (Latest update: 2021)
Кубернетес
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




Кредиты
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
Лицензия


