textgenrnn
T
Легко обучите свою собственную нейронную сеть, генерирующую текст, любого размера и сложности на любом наборе текстовых данных с помощью нескольких строк кода или быстро обучите текст, используя предварительно обученную модель.
textgenrnn — это модуль Python 3 поверх Keras/TensorFlow для создания char-rnn со множеством интересных функций:
Вы можете поиграть с textgenrnn и бесплатно обучить любой текстовый файл с помощью графического процессора в этом блокноте для совместной работы! Прочтите эту публикацию в блоге или посмотрите это видео, чтобы получить дополнительную информацию!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
Включенную модель можно легко обучить на новых текстах и генерировать соответствующий текст даже после одного прохода входных данных .
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
Вес модели относительно невелик (2 МБ на диске), и его можно легко сохранить и загрузить в новый экземпляр textgenrnn. В результате вы можете играть с моделями, которые были обучены на сотнях проходов по данным. (на самом деле textgenrnn учится настолько хорошо , что для творческого результата приходится значительно повышать температуру!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
Вы также можете обучить новую модель с поддержкой встраивания на уровне слов и двунаправленных слоев RNN, добавив new_model=True к любой функции обучения.
Также можно шаг за шагом участвовать в том, как будет развиваться результат. Интерактивный режим предложит вам N лучших вариантов для следующего символа/слова и позволит вам выбрать один.
При запуске textgenrnn в терминале передайте interactive=True и top=N для generate . N по умолчанию равно 3.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
Это может добавить человечности результату; такое ощущение, что ты писатель! (ссылка)
textgenrnn можно установить из pypi через pip :
pip3 install textgenrnnДля последней версии textgenrnn у вас должна быть минимальная версия TensorFlow 2.1.0 .
Вы можете просмотреть демонстрацию общих функций и вариантов конфигурации модели в этом блокноте Jupyter.
/datasets содержит примеры наборов данных с использованием данных Hacker News/Reddit для обучения textgenrnn.
/weights содержит предварительно обученные модели на основе вышеупомянутых наборов данных, которые можно загрузить в textgenrnn.
/outputs содержит примеры текста, сгенерированного на основе предварительно обученных моделей, описанных выше.
textgenrnn основан на проекте char-rnn Андрея Карпати с некоторыми современными оптимизациями, такими как возможность работать с очень небольшими текстовыми последовательностями.
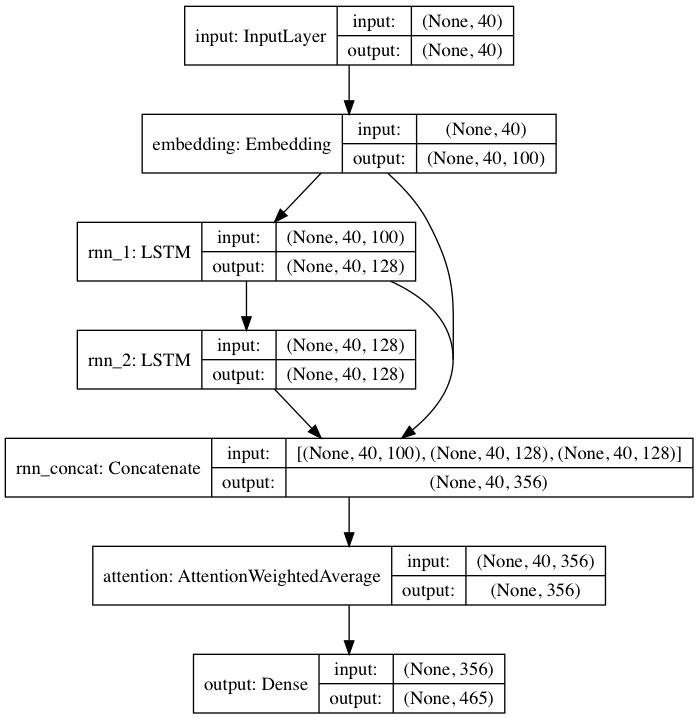
Включенная предварительно обученная модель соответствует архитектуре нейронной сети, вдохновленной DeepMoji. Для модели по умолчанию textgenrnn принимает входные данные длиной до 40 символов, преобразует каждый символ в вектор внедрения символов размером 100 D и передает их в рекуррентный слой долговременной памяти (LSTM) из 128 ячеек. Эти выходные данные затем передаются в другой LSTM со 128 ячейками. Все три слоя затем передаются на уровень внимания, чтобы взвесить наиболее важные временные характеристики и усреднить их вместе (а поскольку вложения + 1-й LSTM пропускаются через слой внимания, обновления модели могут более легко распространяться на них и предотвращать исчезновение). градиенты). Этот вывод сопоставляется с вероятностью для 394 различных символов того, что они являются следующим символом в последовательности, включая символы верхнего и нижнего регистра, знаки препинания и эмодзи. (при обучении новой модели на новом наборе данных можно настроить все приведенные выше числовые параметры)
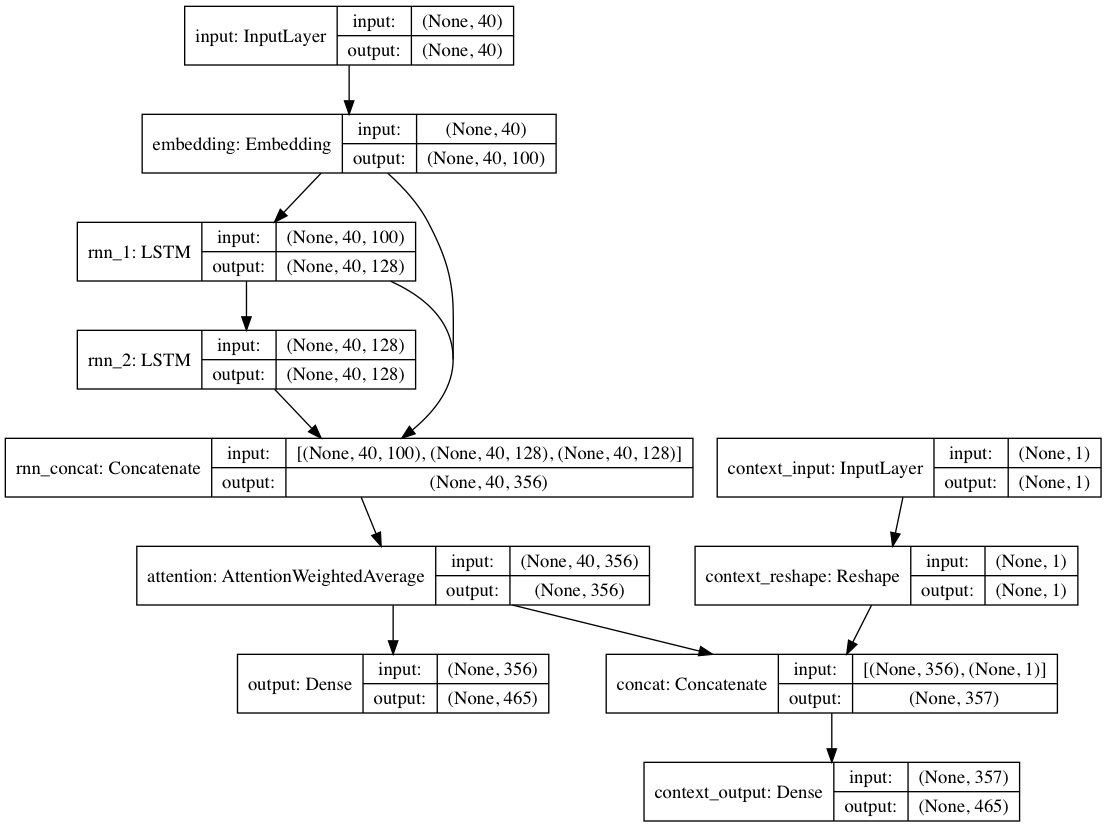
В качестве альтернативы, если контекстные метки предоставляются с каждым текстовым документом, модель можно обучать в контекстном режиме, где модель изучает текст с учетом контекста, поэтому повторяющиеся слои изучают деконтекстуализированный язык. Путь только для текста может сочетаться с деконтекстуализированными слоями; в целом это приводит к гораздо более быстрому обучению и улучшению количественной и качественной производительности модели, чем просто обучение модели на основе только текста.
Веса моделей, включенные в пакет, обучаются на сотнях тысяч текстовых документов из материалов Reddit (через BigQuery) из самых разных субреддитов. Сеть также была обучена с использованием описанного выше деконтекстуального подхода, чтобы улучшить эффективность обучения и смягчить предвзятость авторов.
При точной настройке модели на новом наборе текстовых данных с помощью textgenrnn все слои переобучаются. Однако, поскольку исходная предварительно обученная сеть изначально имеет гораздо более надежные «знания», новый текстовый генератор в конечном итоге обучается быстрее и точнее и потенциально может изучить новые отношения, отсутствующие в исходном наборе данных (например, предварительно обученные встраивания символов включают контекст для символа для всех возможных типов современной интернет-грамматики).
Кроме того, переобучение выполняется с помощью оптимизатора, основанного на импульсе, и линейно затухающей скорости обучения, которые предотвращают взрывной градиент и значительно снижают вероятность отклонения модели после длительного обучения.
Вы не получите качественно сгенерированный текст в 100% случаев , даже с хорошо обученной нейронной сетью. Это основная причина, по которой вирусные посты в блогах/твиттеры в Твиттере, использующие генерацию текста NN, часто генерируют множество текстов и впоследствии отбирают/редактируют лучшие из них.
Результаты будут сильно различаться в зависимости от набора данных . Поскольку предварительно обученная нейронная сеть относительно невелика, она не может хранить столько данных, сколько RNN обычно щеголяют в сообщениях в блогах. Для достижения наилучших результатов используйте набор данных, содержащий не менее 2000–5000 документов. Если набор данных меньше, вам придется обучать его дольше, задав большее значение num_epochs при вызове метода обучения и/или обучении новой модели с нуля. Даже в этом случае в настоящее время не существует хорошей эвристики для определения «хорошей» модели.
Графический процессор не требуется для повторного обучения textgenrnn, но обучение на ЦП займет гораздо больше времени. Если вы используете графический процессор, я рекомендую увеличить параметр batch_size для лучшего использования оборудования.
Более официальная документация
Веб-реализация с использованием tensorflow.js (работает особенно хорошо из-за небольшого размера сети)
Способ визуализации результатов уровня внимания, чтобы увидеть, как сеть «обучается».
Режим, позволяющий использовать архитектуру модели для разговоров с чат-ботами (может быть выпущен как отдельный проект).
Больше глубины контекста (позиционный контекст + возможность использования нескольких контекстных меток)
Более крупная предварительно обученная сеть, которая может обрабатывать более длинные последовательности символов и более глубокое понимание языка, создавая более качественные предложения.
Иерархическая активация softmax для моделей уровня слов (как только у Keras появится хорошая поддержка этого).
FP16 для сверхбыстрого обучения на Volta/TPU (как только у Keras появится хорошая поддержка).
Макс Вульф (@minimaxir)
Проекты Макса с открытым исходным кодом поддерживаются его Patreon. Если этот проект оказался для вас полезным, любые денежные взносы в Patreon будут оценены по достоинству и будут использованы с пользой для творческих целей.
Андрею Карпати за оригинальное предложение char-rnn в блоге «Необоснованная эффективность рекуррентных нейронных сетей».
Даниэлю Грихальве за создание интерактивного режима.
Массачусетский технологический институт
Код уровня внимания, используемый от DeepMoji (лицензия MIT)


