vaex
Version linked to the paper
Vaex — это высокопроизводительная библиотека Python для ленивых внешних фреймов данных (аналог Pandas) для визуализации и исследования больших наборов табличных данных. Он вычисляет такие статистические данные , как среднее значение, сумма, количество, стандартное отклонение и т. д., в N-мерной сетке для более чем миллиарда ( 10^9 ) выборок/строк в секунду . Визуализация осуществляется с использованием гистограмм , графиков плотности и трехмерной объемной визуализации , что позволяет интерактивно исследовать большие данные. Vaex использует сопоставление памяти, политику копирования с нулевой памятью и ленивые вычисления для достижения наилучшей производительности (без потери памяти).
С пипом:
$ pip install vaex
Или Конда:
$ conda install -c conda-forge vaex
Более подробную информацию смотрите в документации
Поддерживаются HDF5 и Apache Arrow.

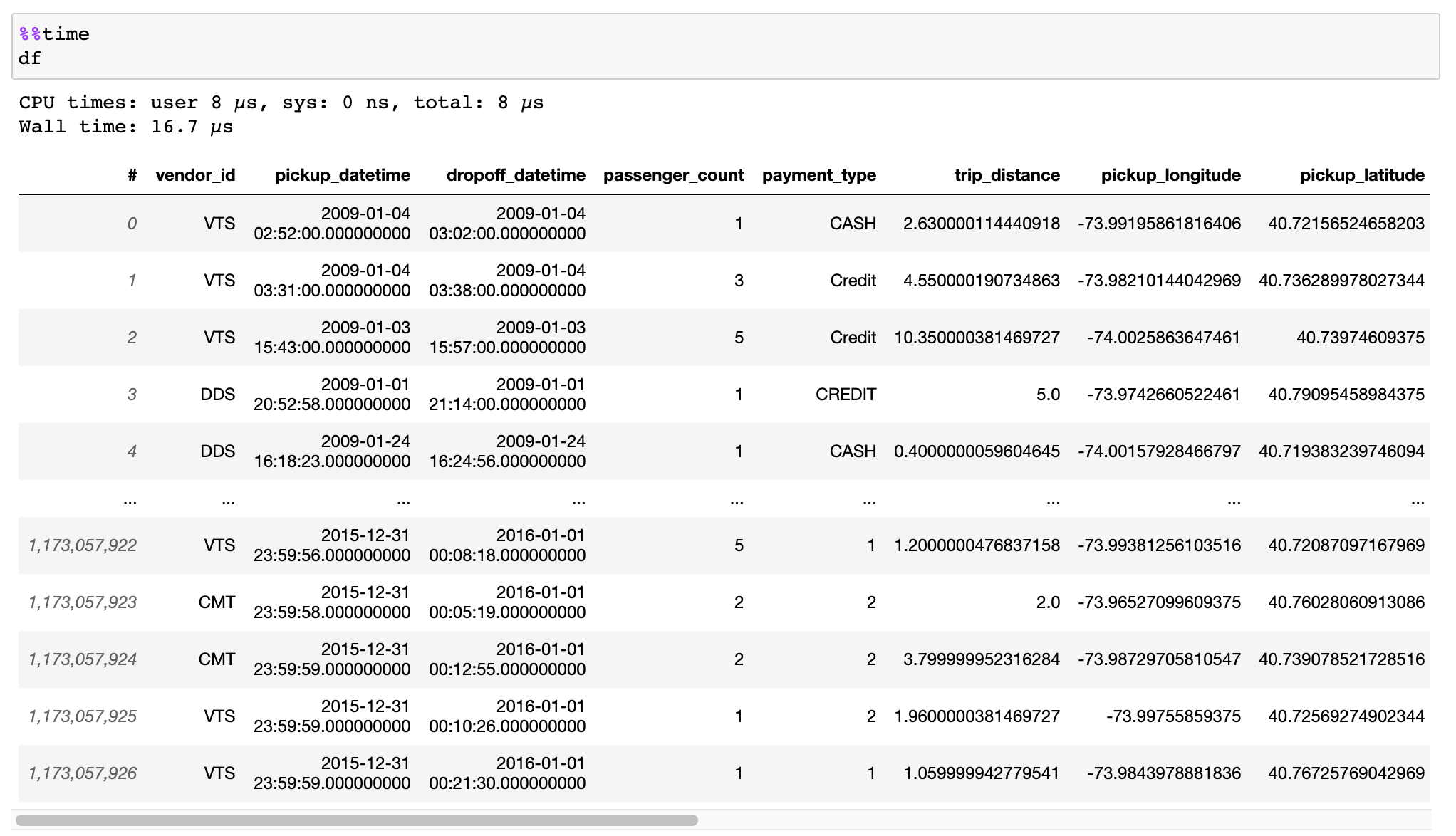
Прочтите документацию о том, как эффективно конвертировать данные из файлов CSV, фреймов данных Pandas или других источников.
Отложенная потоковая передача из S3 поддерживается в сочетании с сопоставлением памяти.

Не тратьте зря память и время на разработку функций: мы (лениво) преобразуем ваши данные, когда это необходимо.
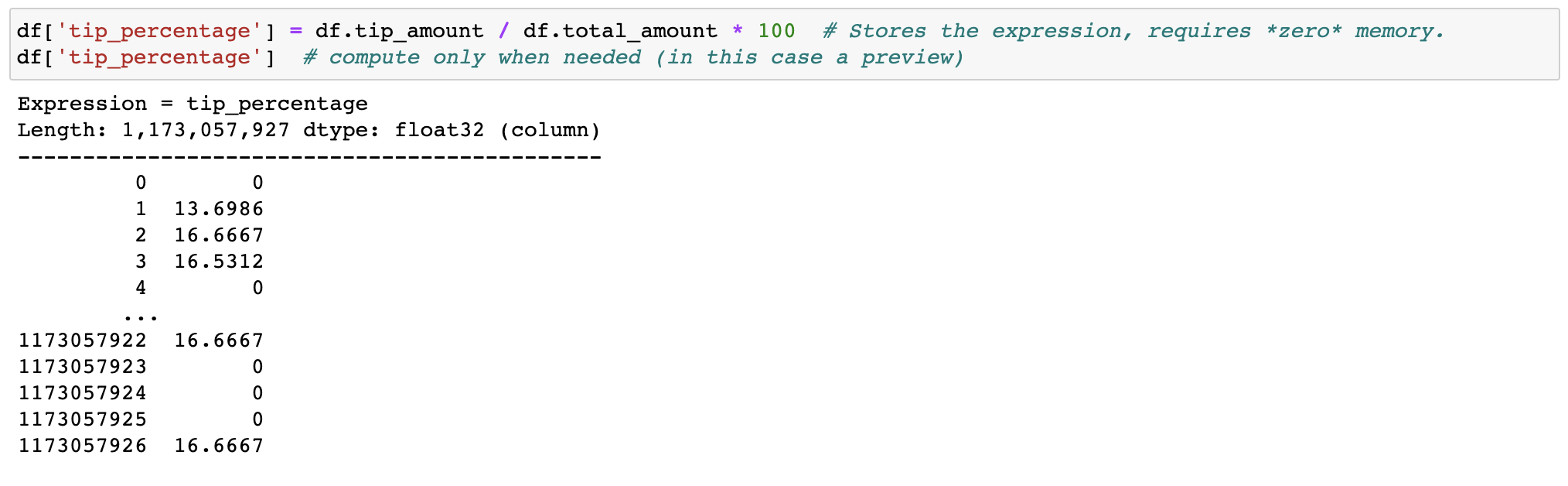
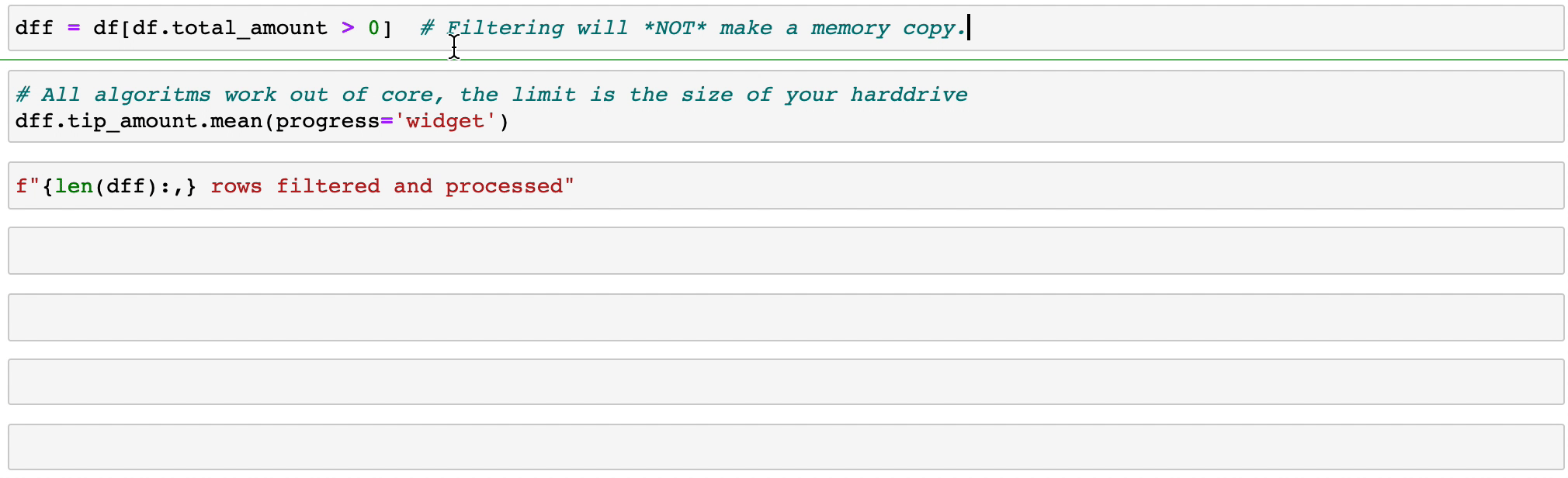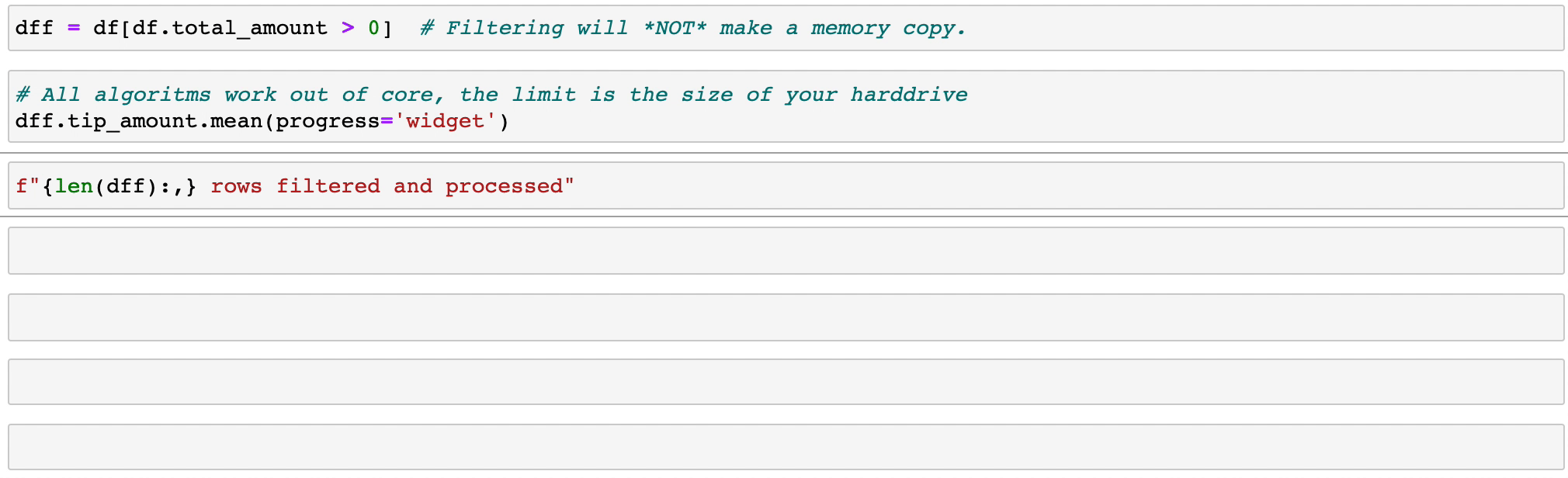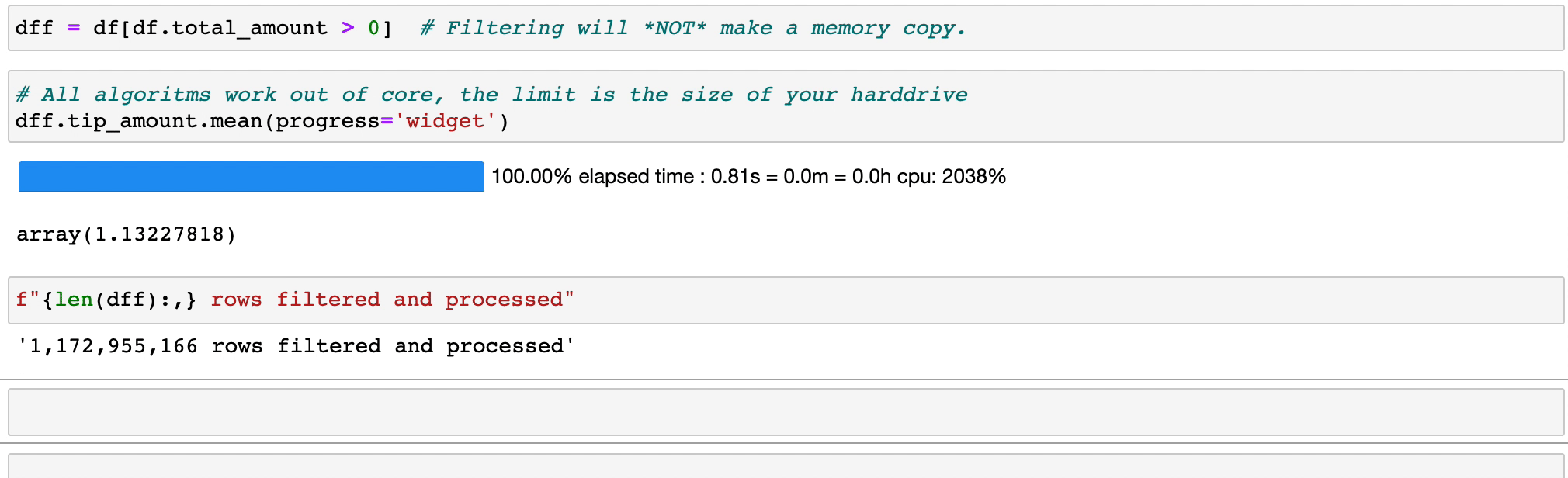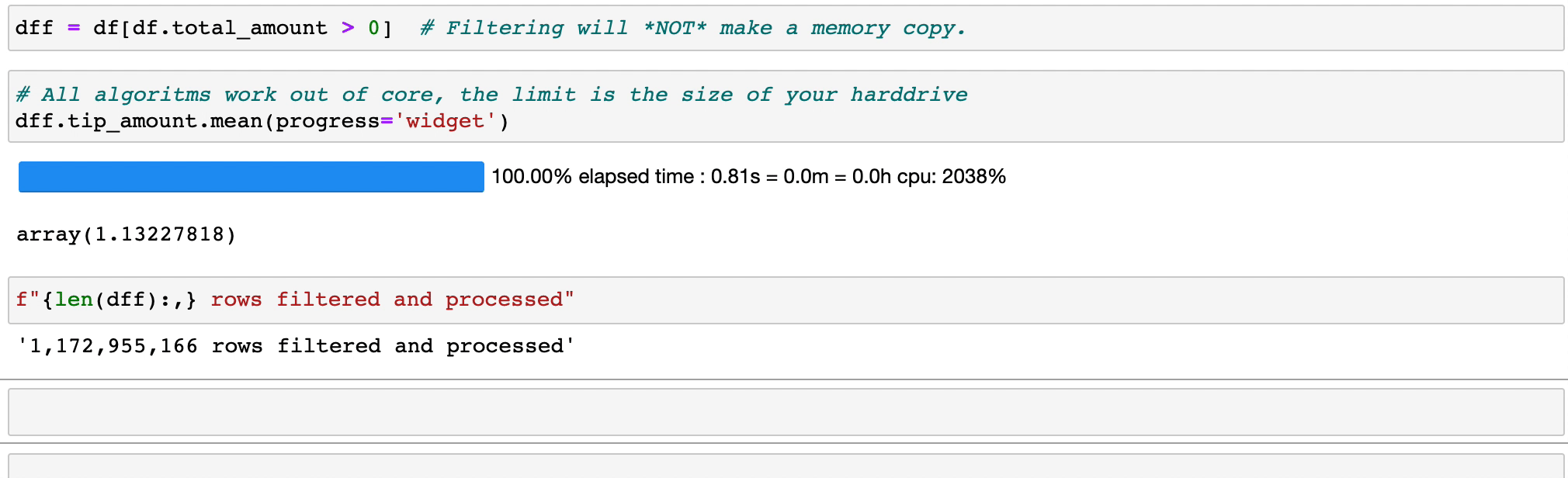
Фильтрация и оценка выражений не будут тратить память на копирование; данные сохраняются на диске в нетронутом виде и будут передаваться только при необходимости. Отложите время, прежде чем вам понадобится кластер.
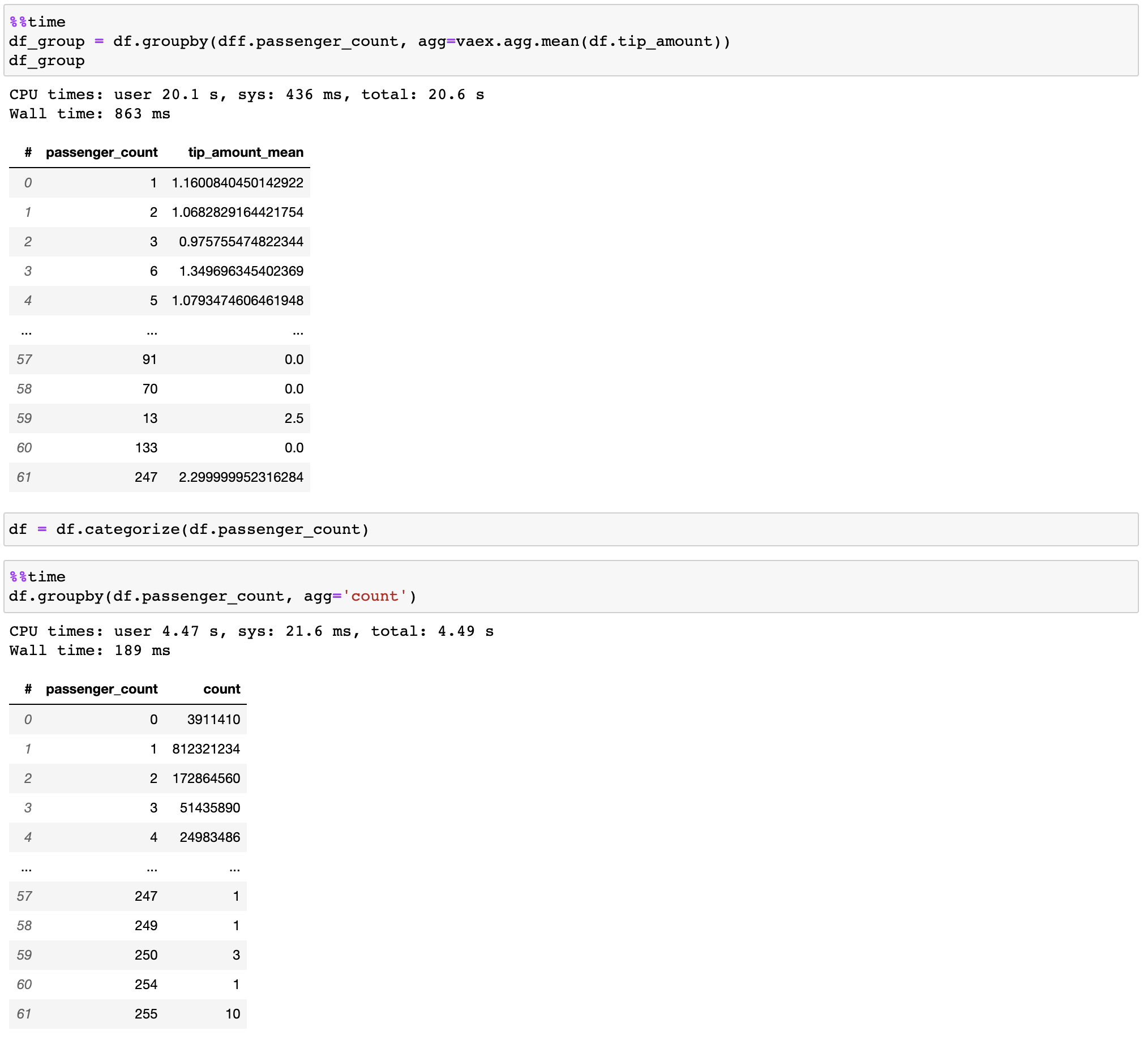
Vaex реализует параллельные, высокопроизводительные операции groupby , особенно при использовании категорий (> 1 миллиарда в секунду).
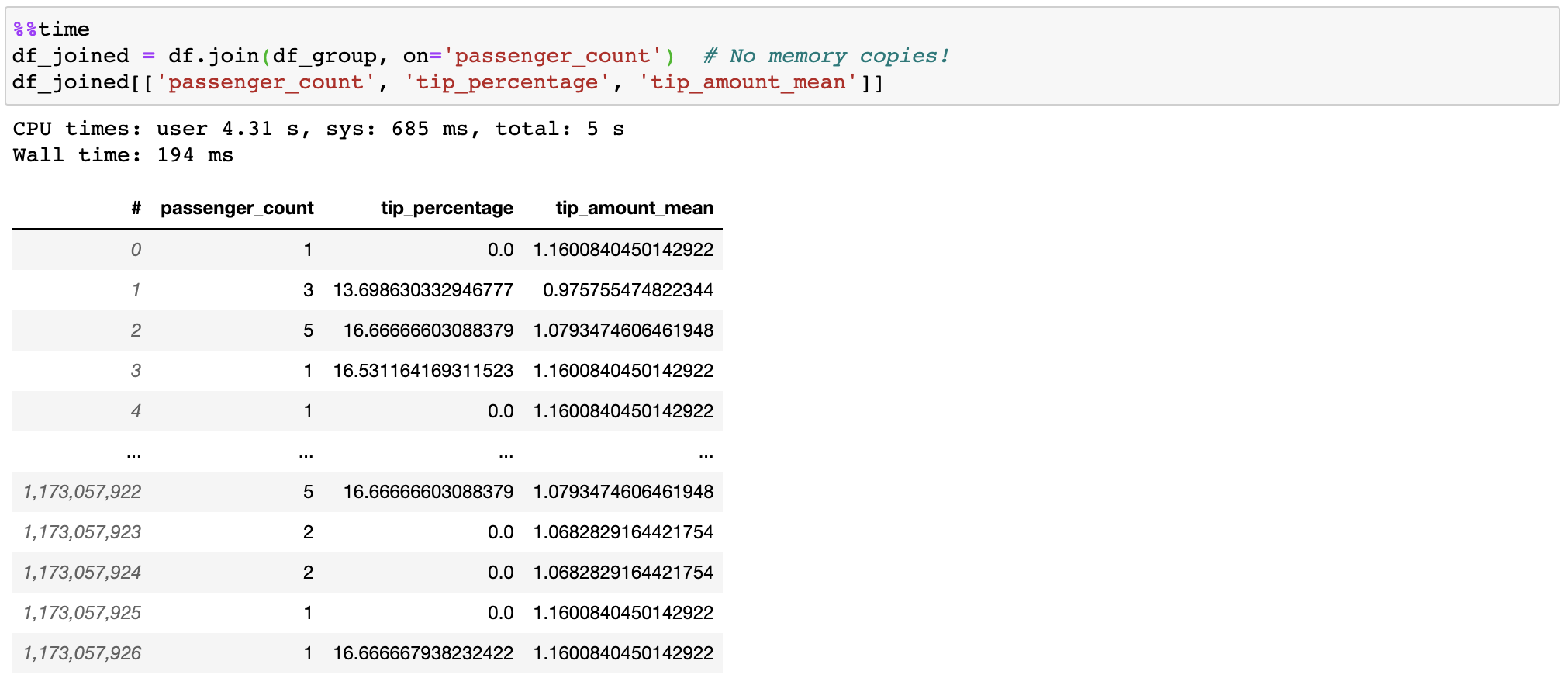
Vaex не копирует/материализует «правильную» таблицу при присоединении, экономя гигабайты памяти. С объединением миллиарда строк за доли секунды это довольно быстро!
См. страницу вклада.
Присоединяйтесь к обсуждению на нашем канале Slack!
Статьи
Следуйте нашим руководствам
Посмотрите наши недавние выступления:
Свяжитесь с нами для получения решений по обработке данных, обучения или корпоративной поддержки по адресу https://vaex.io/.


