SmartFilteringRAG
1.0.0
Вы когда-нибудь искали «старые черно-белые комедии» только для того, чтобы получить смесь современных боевиков? Разочаровывает, правда? В этом проблема традиционных поисковых систем: им часто сложно понять нюансы наших запросов, в результате чего мы просматриваем нерелевантные результаты.
Именно здесь на помощь приходит интеллектуальная фильтрация. Это меняет правила игры, которая использует метаданные и векторный поиск для получения результатов поиска, которые действительно соответствуют вашим намерениям. Представьте себе, что вы без проблем находите именно те классические комедии, которые вам так нужны.
Мы углубимся в то, что такое интеллектуальная фильтрация, как она работает и почему она важна для улучшения качества поиска. Давайте раскроем волшебство этой технологии и выясним, как она может революционизировать способ поиска.
Векторный поиск — мощный инструмент, который помогает компьютерам понять значение данных, а не только самих слов. Вместо сопоставления ключевых слов он фокусируется на основных концепциях и отношениях. Представьте себе, что вы ищете «собаку» и получаете результаты, включающие «щенок», «собака» и даже изображения собак. Это магия векторного поиска!
Как это работает? Ну, он преобразует данные в математические представления, называемые векторами. Эти векторы подобны координатам на карте, и похожие точки данных расположены ближе друг к другу в этом векторном пространстве. Когда вы что-то ищете, система находит векторы, наиболее близкие к вашему запросу, и дает результаты, семантически схожие.
Хотя векторный поиск отлично подходит для понимания контекста, он иногда не справляется с простыми задачами фильтрации. Например, поиск всех фильмов, выпущенных до 2000 года, требует точной фильтрации, а не только семантического понимания. Именно здесь на помощь приходит интеллектуальная фильтрация, дополняющая векторный поиск.
Хотя вектор приближает нас к пониманию истинного смысла запросов, все еще существует разрыв между тем, чего хотят пользователи, и тем, что предоставляют поисковые системы. Сложные поисковые запросы, такие как «самые ранние комедийные фильмы до 2000 года», по-прежнему могут быть проблемой. Семантический поиск может понять понятия «комедия» и «кино», но может возникнуть проблема со спецификой «ранние» и «до 2000 года».
Здесь результаты начинают становиться запутанными. Мы можем получить смесь старых и новых комедий или даже драм, которые были включены по ошибке. Чтобы по-настоящему удовлетворить пользователей, нам нужен способ уточнить результаты поиска и сделать их более точными. Вот тут-то и вступают в игру предварительные фильтры.
Умная фильтрация — решение этой проблемы. Это метод, который использует метаданные набора данных для создания конкретных фильтров, уточняя результаты поиска и делая их более точными и эффективными. Анализируя информацию о ваших данных, такую как их структура, содержание и атрибуты, интеллектуальная фильтрация может определить соответствующие критерии для фильтрации вашего поиска.
Представьте, что вы ищете «комедийные фильмы, выпущенные до 2000 года». Интеллектуальная фильтрация будет использовать метаданные, такие как жанр, дата выпуска и, возможно, даже ключевые слова сюжета, чтобы создать фильтр, который включает только фильмы, соответствующие этим критериям. Таким образом, вы получите список именно того, что вам нужно, без лишнего шума.
Давайте углубимся в то, как работает интеллектуальная фильтрация, в следующем разделе.
Интеллектуальная фильтрация — это многоэтапный процесс, который включает в себя извлечение информации из ваших данных, ее анализ и создание специальных фильтров в соответствии с вашими потребностями. Давайте разберем это:
Извлечение метаданных. Первым шагом является сбор соответствующей информации о ваших данных. Сюда входят такие детали, как:
Генерация предварительных фильтров: получив метаданные, вы можете приступить к созданию предварительных фильтров. Это особые условия, которым должны соответствовать данные, чтобы они были включены в результаты поиска. Например, если вы ищете комедии, выпущенные до 2000 года, вы можете создать предварительные фильтры для:
Интеграция с векторным поиском. Последний шаг — объединить эти предварительные фильтры с векторным поиском. Это гарантирует, что векторный поиск будет учитывать только те точки данных, которые соответствуют заранее заданным критериям.
Следуя этим шагам, интеллектуальная фильтрация значительно повышает точность и эффективность результатов поиска.
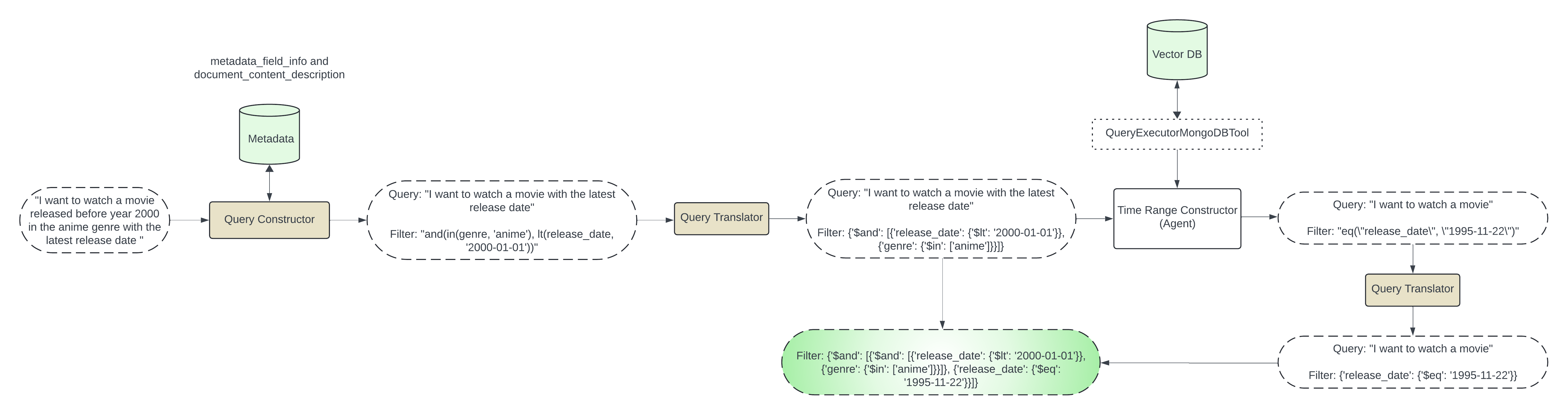
Извлечение метаданных. В целях упрощения мы будем использовать образцы данных и вручную определять метаданные. См.: get_docs_metadata в prepare_test_data.py .
Генерация предварительного фильтра: мы создадим предварительные фильтры в два этапа.
Шаг 1. Фильтр на основе метаданных
Этот шаг включает в себя создание фильтра на основе метаданных. Мы передадим пользовательский запрос и метаданные в LLM и сгенерируем фильтр метаданных.
Мы будем использовать query_constructor, который инициализируется с помощью DEFAULT_SCHEMA_PROMPT.
Примечание. Обновите подсказку и несколько примеров снимков в соответствии с вашим вариантом использования.
Например: если в метаданных есть genre и release_date , а пользователь запрашивает фильмы жанра action , выпущенные до 2020 года, мы можем использовать LLM для создания фильтра, как показано ниже:
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
Шаг 2. Фильтрация по времени
На этом этапе мы будем обрабатывать случаи, когда пользователь запрашивает latest , most recent и earliest тип информации. Нам придется запросить фактические данные, чтобы получить эту информацию. На этом этапе мы будем использовать агент LLM для запроса коллекции mongodb с помощью инструмента-исполнителя: QueryExecutorMongoDBTool. Мы генерируем фильтр на основе времени в файлеgenerate_time_based_filter. Мы также будем использовать pre_filter, сгенерированный на первом этапе $match на этапе агрегации. Например: если пользователю нужен последний фильм, агент LLM запустит запрос агрегации с помощью инструмента-исполнителя:
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
Интеграция с векторным поиском: сгенерированный предварительный фильтр будет использоваться с ретривером MongoDBAtlasVectorSearch:
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)Создайте новую среду Python
python3 -m venv env
source env/bin/activateУстановите требования
pip3 install -r requirements.txtУстановите конфигурации в config.yaml.
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002Установите переменные среды
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "Инициализируйте коллекцию mongodb с помощью образца данных. Эта команда проиндексирует некоторые образцы данных, а также создаст индекс векторного поиска в коллекции.
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] 'Сгенерированные пре_фильтры:
Входной запрос: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
Выход: 
Входной запрос: "Recommend a thriller or action movie release after Feb, 2010"
Выход: 
Входной запрос: "Recommend an anime movie released before 2023 with the latest release date"
Выход: 
Интеллектуальная фильтрация дает таблице множество преимуществ, что делает ее ценным инструментом для улучшения качества поиска:
Повышенная точность поиска. Благодаря точному нацеливанию на данные, соответствующие вашему запросу, интеллектуальная фильтрация значительно повышает вероятность нахождения релевантных результатов. Больше не нужно копаться в ненужной информации.
Более быстрые результаты поиска. Поскольку интеллектуальная фильтрация сужает область поиска, система может обрабатывать информацию более эффективно, что приводит к более быстрому получению результатов.
Улучшенный пользовательский опыт. Когда пользователи быстро и легко находят то, что ищут, это приводит к повышению удовлетворенности и улучшению общего опыта.
Универсальность: интеллектуальную фильтрацию можно применять в различных областях: от поиска товаров в электронной коммерции до рекомендаций по контенту, что делает ее универсальным инструментом.
Используя метаданные и создавая целевые предварительные фильтры, интеллектуальная фильтрация позволяет вам предоставлять результаты поиска, которые действительно соответствуют ожиданиям пользователей.
Интеллектуальная фильтрация — это мощный инструмент, который меняет впечатления, устраняя разрыв между намерениями пользователя и результатами. Используя возможности метаданных и векторного поиска, он обеспечивает более точные, релевантные и эффективные результаты поиска.
Независимо от того, создаете ли вы платформу электронной коммерции, систему рекомендаций по контенту или любое другое приложение, основанное на эффективном поиске, включение интеллектуальной фильтрации может значительно повысить удовлетворенность пользователей и улучшить результаты.
Понимая основы интеллектуальной фильтрации, вы сможете изучить ее потенциал и реализовать в своих проектах. Так зачем ждать? Начните использовать возможности интеллектуальной фильтрации сегодня и произведите революцию в своей поисковой игре!
Вдохновлен системой Self Query Retriever от LangChain.


