qwen2 in a lambda
1.0.0
Обновлено 09.11.2024
(Отмечаем дату из-за того, насколько быстро развиваются API-интерфейсы LLM в Python и могут внести критические изменения к тому времени, когда кто-нибудь еще это прочитает!)
Это небольшое исследование того, как мы можем поместить файлы модели Qwen GGUF в AWS Lambda с помощью Docker и SAM CLI.
Адаптировано из https://makit.net/blog/llm-in-a-lambda-function/.
Я хотел выяснить, смогу ли я сократить свои расходы на AWS, используя только возможности Lambda, а не Lambda + Bedrock, поскольку в долгосрочной перспективе оба сервиса повлекут за собой больше затрат.
Идея заключалась в том, чтобы подогнать небольшую языковую модель, которая не была бы такой ресурсоемкой относительно, и, как мы надеемся, получить задержку от доли секунды до секунды в конфигурации памяти 128–256 МБ.
Я хотел также использовать модели GGUF, чтобы использовать разные уровни квантования, чтобы выяснить, какая производительность/размер файла является наилучшей для загрузки в память.
qwen2-1_5b-instruct-q5_k_m.gguf в qwen_fuction/function/app.y / LOCAL_PATH qwen_function/function/requirements.txt (желательно в среде venv/conda)sam build / sam validatesam local start-api для локального тестирования.curl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate , чтобы запросить LLM.sam deploy --guided по развертыванию на AWS.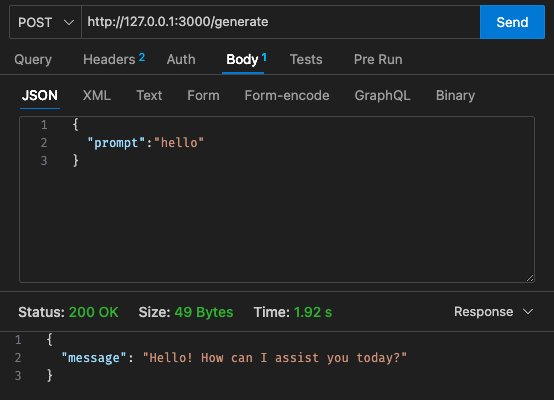
АВС
Начальная конфигурация - 128 МБ, таймаут 30 с.
Скорректированная конфигурация №1 — 512 МБ, таймаут 30 секунд.
Скорректированная конфигурация №2 - 512 МБ, таймаут 30 с.
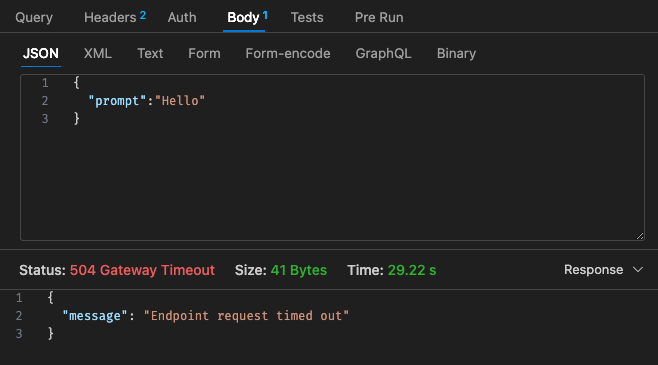
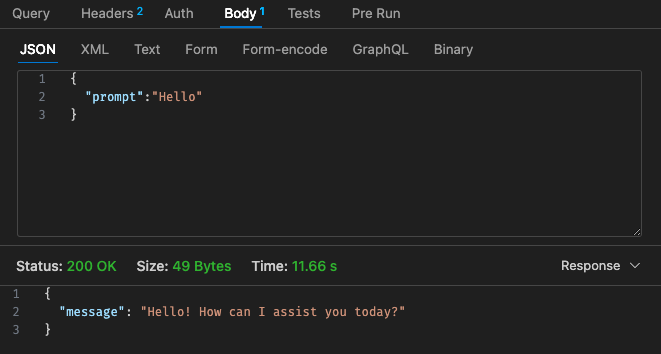
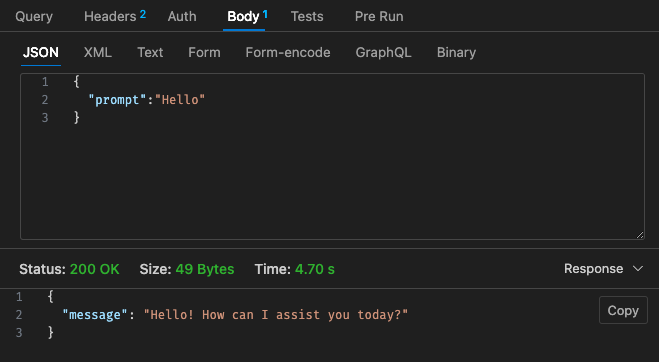
Возвращаясь к структуре ценообразования Lambda,
Возможно, дешевле будет просто использовать размещенный LLM с использованием AWS Bedrock и т. д. в облаке, поскольку структура цен на Lambda с Qwen не выглядит более конкурентоспособной по сравнению с Claude 3 Haiku.
Кроме того, тайм-аут шлюза API нелегко настроить за пределами тайм-аута 30 с, в зависимости от вашего варианта использования это может быть не очень идеально.
Результаты через локальную систему зависят от характеристик вашей машины! и может сильно исказить ваше восприятие, ожидание и реальность
В зависимости от вашего варианта использования задержка на вызов лямбда-выражения и ответы могут привести к ухудшению пользовательского опыта.
В целом, я думаю, что это был забавный небольшой эксперимент, хотя он не совсем соответствовал требованиям по бюджету и задержке Qwen 1.5b для моего побочного проекта. Еще раз спасибо @makit за руководство!


