Interactive RAG
1.0.0
Агенты меняют способы использования языковых моделей для принятия решений и выполнения задач. Агенты — это системы, которые используют языковые модели для принятия решений и выполнения задач. Они предназначены для обработки сложных сценариев и обеспечивают большую гибкость по сравнению с традиционными подходами. Агентов можно рассматривать как механизмы рассуждения, которые используют языковые модели для обработки информации, извлечения соответствующих данных, приема (фрагментирования/встраивания) и генерации ответов.
В будущем агенты будут играть жизненно важную роль в обработке текста, автоматизации задач и улучшении взаимодействия человека с компьютером по мере развития языковых моделей.
В этом примере мы сосредоточимся на использовании агентов в динамическом поиске дополненной генерации (RAG). Используя ActionWeaver и MongoDB Atlas, вы сможете изменять свою стратегию RAG в режиме реального времени посредством диалогового взаимодействия. Независимо от того, выбираете ли вы больше фрагментов, увеличиваете размер фрагментов или настраиваете другие параметры, вы можете точно настроить свой подход RAG для достижения желаемого качества и точности ответа. Вы даже можете добавлять/удалять источники в свою векторную базу данных, используя естественный язык!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
Разбивать текст на части — это здорово, но как его хранить?
Подведение итогов экономит место и ускоряет работу, но может привести к потере деталей.
Хранение необработанных данных является точным, но громоздким, медленным и «шумным».
Плюсы подведения итогов:
Минусы подведения итогов:
Что подходит именно вам? Это зависит от ваших потребностей! Учитывать:
ДЕМО 1
Создайте новую среду Python
python3 -m venv envАктивируйте новую среду Python
source env/bin/activateУстановите требования
pip3 install -r requirements.txtУстановите параметры в params.py:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
Создайте индекс поиска со следующим определением
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}Установите среду
export OPENAI_API_KEY=Запуск приложения RAG
env/bin/streamlit run rag/app.pyИнформация журнала, созданная приложением, будет добавлена в app.log.
Этот бот поддерживает следующие действия: отвечать на вопросы, выполнять поиск в Интернете, читать URL-адреса, удалять источники, перечислять все источники и сбрасывать сообщения. Он также поддерживает действие под названием iRAG, которое позволяет вам динамически управлять стратегией RAG вашего агента.
Пример: «установите конфигурацию RAG на 3 источника и размер блока 1250» => Новая конфигурация RAG: {'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
Если бот не может дать ответ на вопрос на основе данных, хранящихся в хранилище Atlas Vector, и вашей стратегии RAG (количество источников, размер фрагмента, min_rel_score и т. д.), он инициирует поиск в Интернете для поиска соответствующей информации. Затем вы можете поручить боту читать и учиться на этих результатах.
RAG — это круто и все такое, но придумать правильную «стратегию RAG» непросто. Размер блока и количество уникальных источников будут иметь прямое влияние на ответ, генерируемый LLM.
При разработке эффективной стратегии RAG решающую роль играют процесс приема веб-источников, разбиение на фрагменты, встраивание, размер фрагментов и количество используемых источников. Разбиение на части разбивает входной текст для лучшего понимания, встраивание отражает смысл, а количество источников влияет на разнообразие ответов. Нахождение правильного баланса между размером блока и количеством источников имеет важное значение для получения точных и релевантных ответов. Для определения оптимальных настроек необходимы эксперименты и точная настройка.
Прежде чем мы углубимся в «Извлечение», давайте сначала поговорим о «Процессе захвата».
Зачем нужен отдельный процесс для «вставки» вашего контента в векторную базу данных? Используя магию агентов, мы можем легко добавлять новый контент в векторную базу данных.
Существует множество типов баз данных, в которых могут храниться эти внедрения, каждая из которых имеет свое особое применение. Но для задач, связанных с приложениями GenAI, я рекомендую MongoDB.
Думайте о MongoDB как о торте, который можно и съесть, и съесть. Он дает вам возможности своего языка для создания запросов — Mongo Query Language. Он также включает в себя все замечательные функции MongoDB. Кроме того, он позволяет хранить эти стандартные блоки (вложения векторов) и выполнять над ними математические операции — и все это в одном месте. Это делает MongoDB Atlas универсальным решением для всех ваших потребностей в векторном встраивании!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
Используя ActionWeaver, легкую оболочку для API вызова функций, мы можем создать пользовательский прокси-агент, который эффективно извлекает и принимает соответствующую информацию с помощью MongoDB Atlas.
Прокси-агент — это посредник, отправляющий клиентские запросы на другие серверы или ресурсы, а затем возвращающий ответы.
Этот агент представляет данные пользователю в интерактивном и настраиваемом виде, улучшая общее удобство работы пользователя.
UserProxyAgent имеет несколько параметров RAG, которые можно настроить, например, chunk_size (например, 1000), num_sources (например, 2), unique (например, True) и min_rel_score (например, 0,00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
Вот некоторые ключевые преимущества, которые повлияли на наше решение выбрать ActionWeaver:
Агент — это, по сути, просто компьютерная программа или система, предназначенная для восприятия окружающей среды, принятия решений и достижения конкретных целей.
Думайте об агенте как о программном объекте, который демонстрирует некоторую степень автономии и выполняет действия в своей среде от имени своего пользователя или владельца, но относительно независимым образом. Он берет на себя инициативу по выполнению действий самостоятельно, обдумывая варианты достижения своих целей. Основная идея агентов заключается в использовании языковой модели для выбора последовательности действий. В отличие от цепочек, где последовательность действий жестко запрограммирована в коде, агенты используют языковую модель в качестве механизма рассуждения, чтобы определить, какие действия следует предпринять и в каком порядке.
Действия — это функции, которые может вызывать агент. При разработке действий необходимо учитывать два важных соображения:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
Не продумав и то, и другое, вы не сможете создать работающего агента. Если вы не предоставите агенту доступ к правильному набору действий, он никогда не сможет достичь поставленных вами целей. Если вы плохо опишете действия, агент не будет знать, как их правильно использовать.
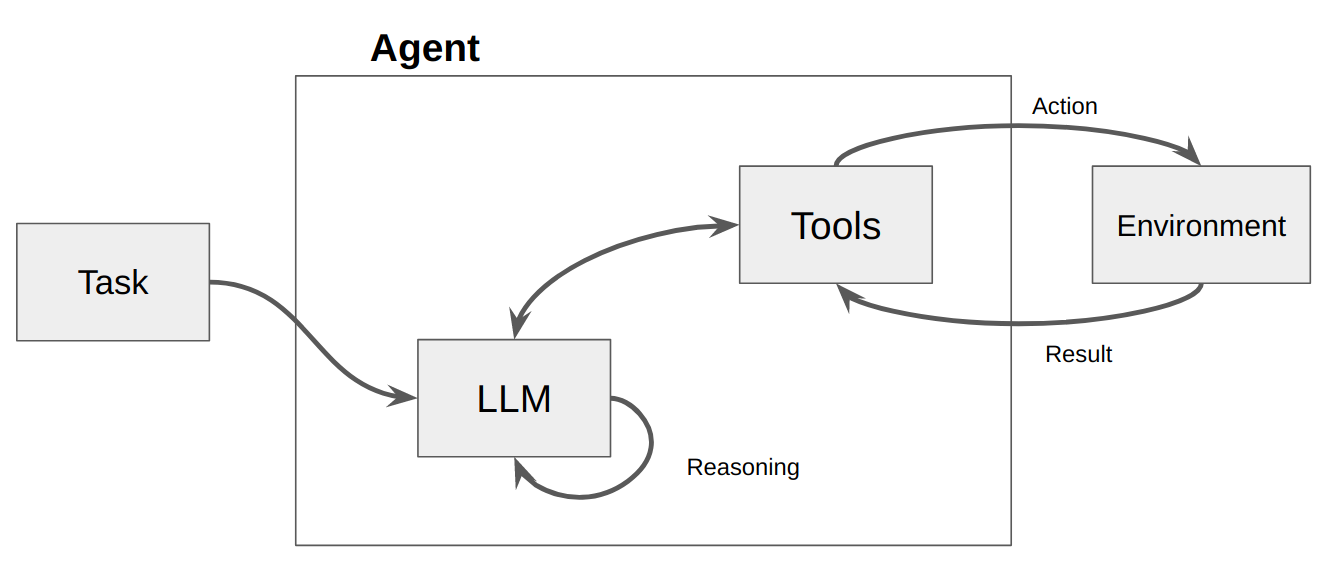
Затем вызывается LLM, результатом которого является либо ответ пользователю, либо действия, которые необходимо предпринять. Если определено, что требуется ответ, он передается пользователю, и этот цикл завершается. Если определено, что требуется действие, то это действие предпринимается и производится наблюдение (результат действия). Это действие и соответствующее наблюдение добавляются обратно в приглашение (мы называем это «блокнотом агента»), и цикл сбрасывается, т.е. LLM вызывается снова (с обновленным блокнотом агента).
В ActionWeaver мы можем влиять на цикл, добавляя к действию stop=True|False . Если stop=True , LLM немедленно вернет выходные данные функции. Это также ограничит LLM от выполнения нескольких вызовов функций. В этой демонстрации мы будем использовать только stop=True
ActionWeaver также поддерживает более сложное управление циклом с помощью orch_expr(SelectOne[actions]) и orch_expr(RequireNext[actions]) , но я оставлю это для ЧАСТИ II.
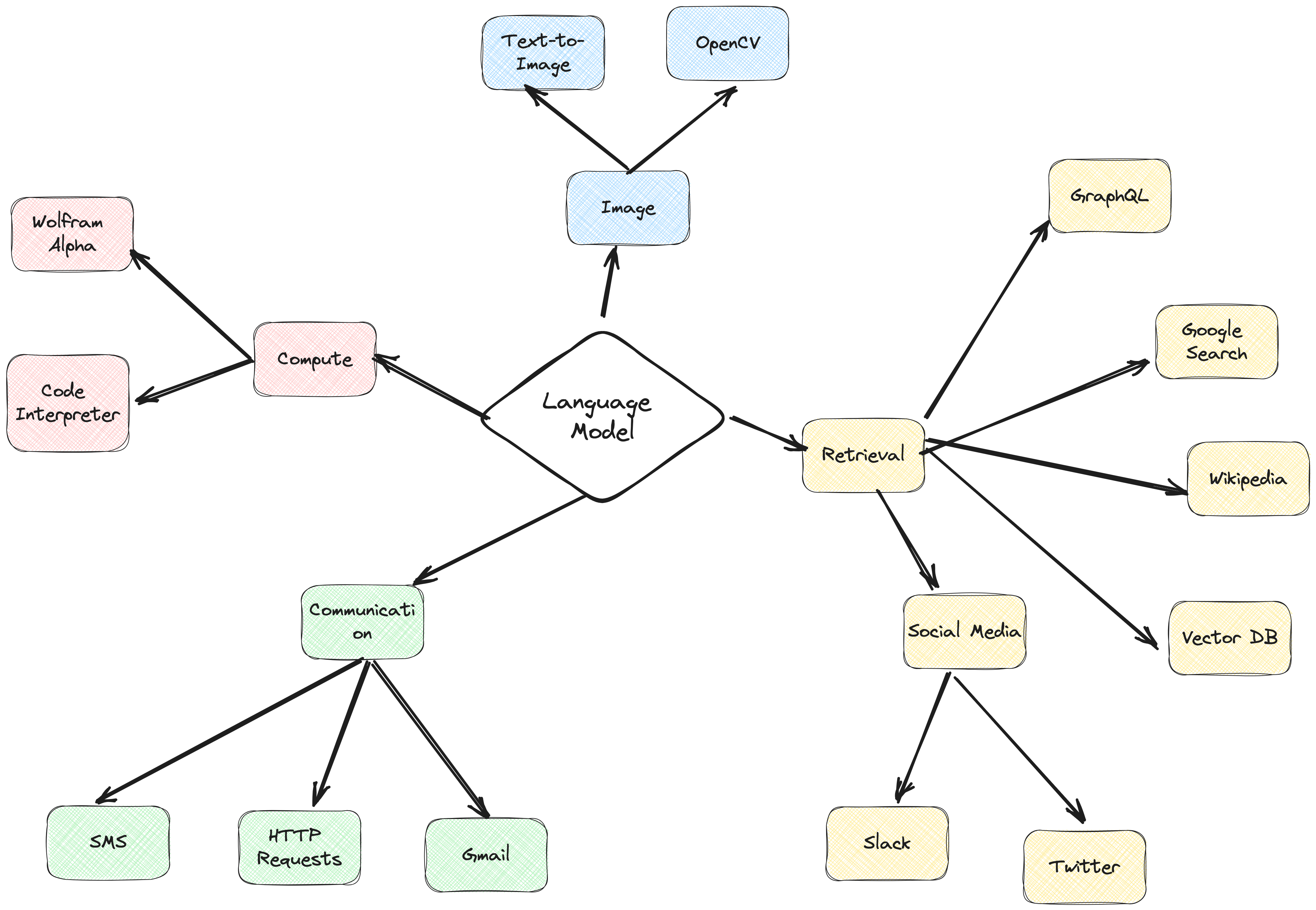
Платформа агента ActionWeaver — это платформа приложений искусственного интеллекта, в основе которой лежит вызов функций. Он предназначен для обеспечения плавного объединения традиционных вычислительных систем с мощными логическими возможностями моделей языковых моделей. ActionWeaver построен на концепции вызова функций LLM, тогда как популярные платформы, такие как Langchain и Haystack, построены на концепции конвейеров.

Подробнее читайте на странице: https://thinhdanggroup.github.io/function-calling-openai/.
Разработчики могут прикрепить ЛЮБУЮ функцию Python в качестве инструмента с помощью простого декоратора. В следующем примере мы представляем действие get_sources_list, которое будет вызываться API OpenAI.
ActionWeaver использует сигнатуру и строку документации декорированного метода в качестве описания, передавая их в API функций OpenAI.
ActionWeaver предоставляет легкую оболочку, которая преобразует информацию строки документации/декоратора в правильный формат для API OpenAI.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True при добавлении к действию означает, что LLM немедленно вернет выходные данные функции, но это также ограничивает LLM от выполнения нескольких вызовов функций. Например, если спросить о погоде в Нью-Йорке и Сан-Франциско, модель последовательно вызовет две отдельные функции для каждого города. Однако при использовании stop=True этот процесс прерывается, как только первая функция возвращает информацию о погоде для Нью-Йорка или Сан-Франциско, в зависимости от того, какой город она запрашивает первым.
Для более глубокого понимания того, как работает этот бот, обратитесь к файлу bot.py. Кроме того, вы можете изучить репозиторий ActionWeaver для получения более подробной информации.
Генерация трассировок рассуждений позволяет модели вызывать, отслеживать и обновлять планы действий и даже обрабатывать исключения. В этом примере используется ReAct в сочетании с цепочкой мыслей (CoT).
Цепочка мыслей
Рассуждение + действие
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
В этих примерах используются как цепочка мыслей (CoT), так и методы подсказок ReAct. Вот как:
Цепочка мыслей (CoT)
Подсказка ReAct:
Подводя итог, можно сказать, что и CoT, и ReAct играют решающую роль в этих примерах. CoT позволяет модели шаг за шагом рассуждать и выбирать подходящие действия, а ReAct расширяет эту функциональность, позволяя модели взаимодействовать со своей средой и соответствующим образом обновлять свои планы. Такое сочетание рассуждений и действий делает большие языковые модели более гибкими и универсальными, позволяя им справляться с более широким спектром задач и ситуаций.
Давайте начнем с того, что зададим вопрос нашему агенту. В данном случае «Что такое манго?» . Первое, что произойдет, это попытка «вспомнить» любую соответствующую информацию, используя сходство встраивания векторов. Затем он сформулирует ответ с содержанием, которое он «вспомнил», или выполнит поиск в Интернете. Поскольку наша база знаний в настоящее время пуста, нам необходимо добавить несколько источников, прежде чем она сможет сформулировать ответ.
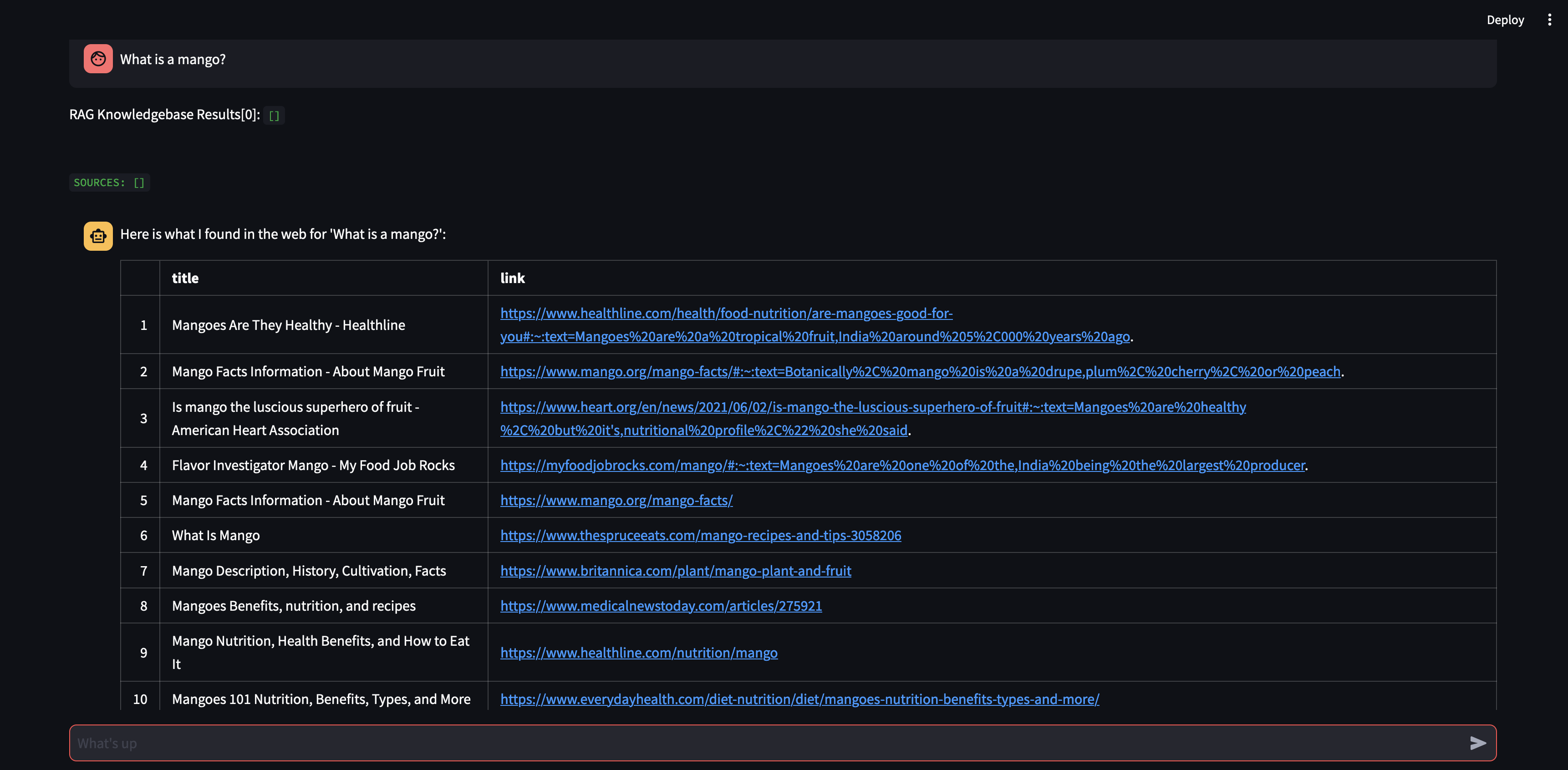
Поскольку бот не может дать ответ, используя контент в базе данных векторов, он инициировал поиск в Google, чтобы найти соответствующую информацию. Теперь мы можем сказать ему, какие источники ему следует «изучить». В этом случае мы сообщим ему изучить первые два источника из результатов поиска.
Далее давайте изменим стратегию RAG! Давайте сделаем так, чтобы он использовал только один источник и небольшой фрагмент размером в 500 символов.
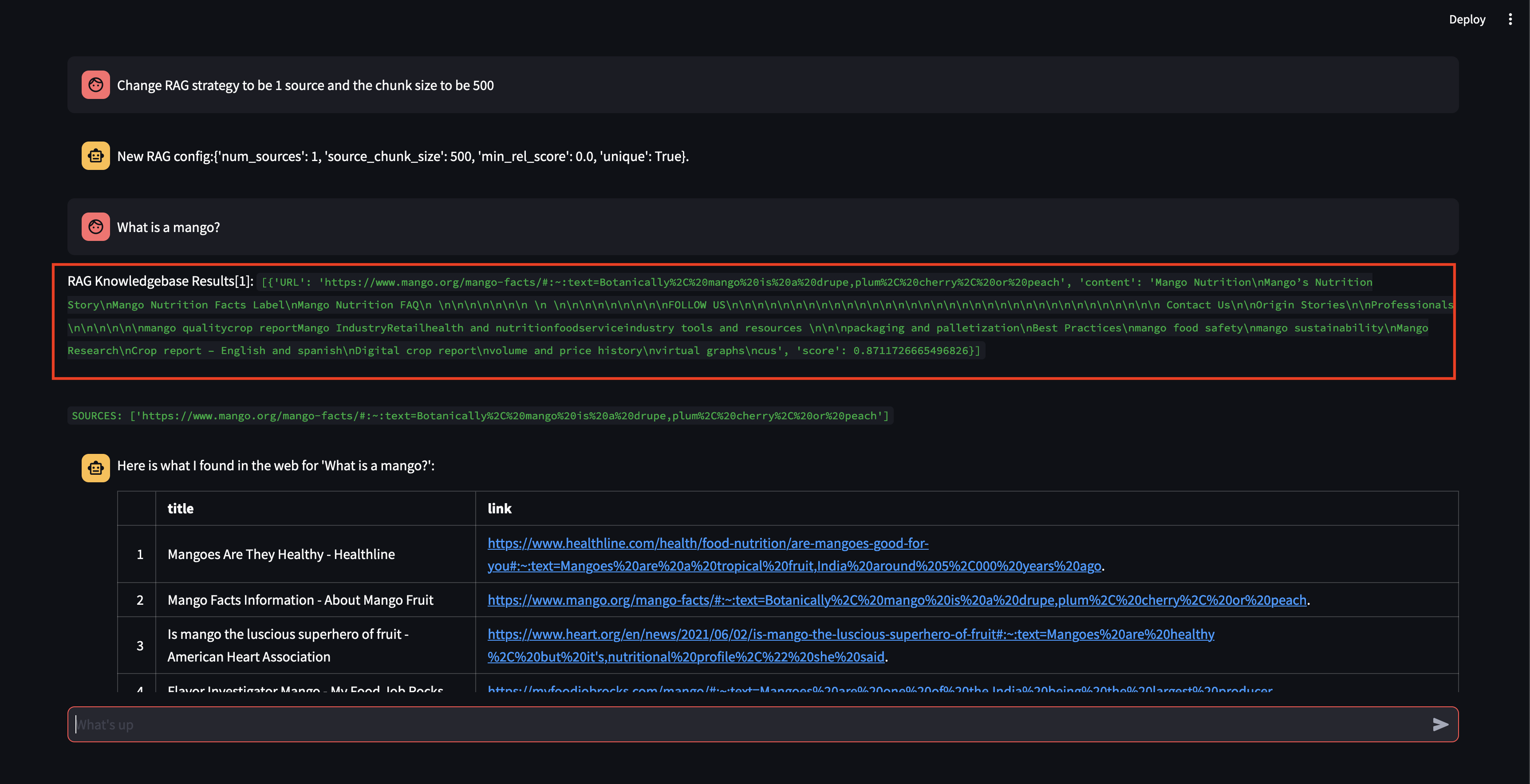
Обратите внимание: хотя ему удалось получить фрагмент с довольно высоким показателем релевантности, он не смог сгенерировать ответ, поскольку размер фрагмента был слишком мал, а содержимое фрагмента не было достаточно релевантным для формулирования ответа. Поскольку он не смог сгенерировать ответ с помощью небольшого фрагмента, он выполнил поиск в Интернете от имени пользователя.
Давайте посмотрим, что произойдет, если мы увеличим размер фрагмента до 3000 символов вместо 500.
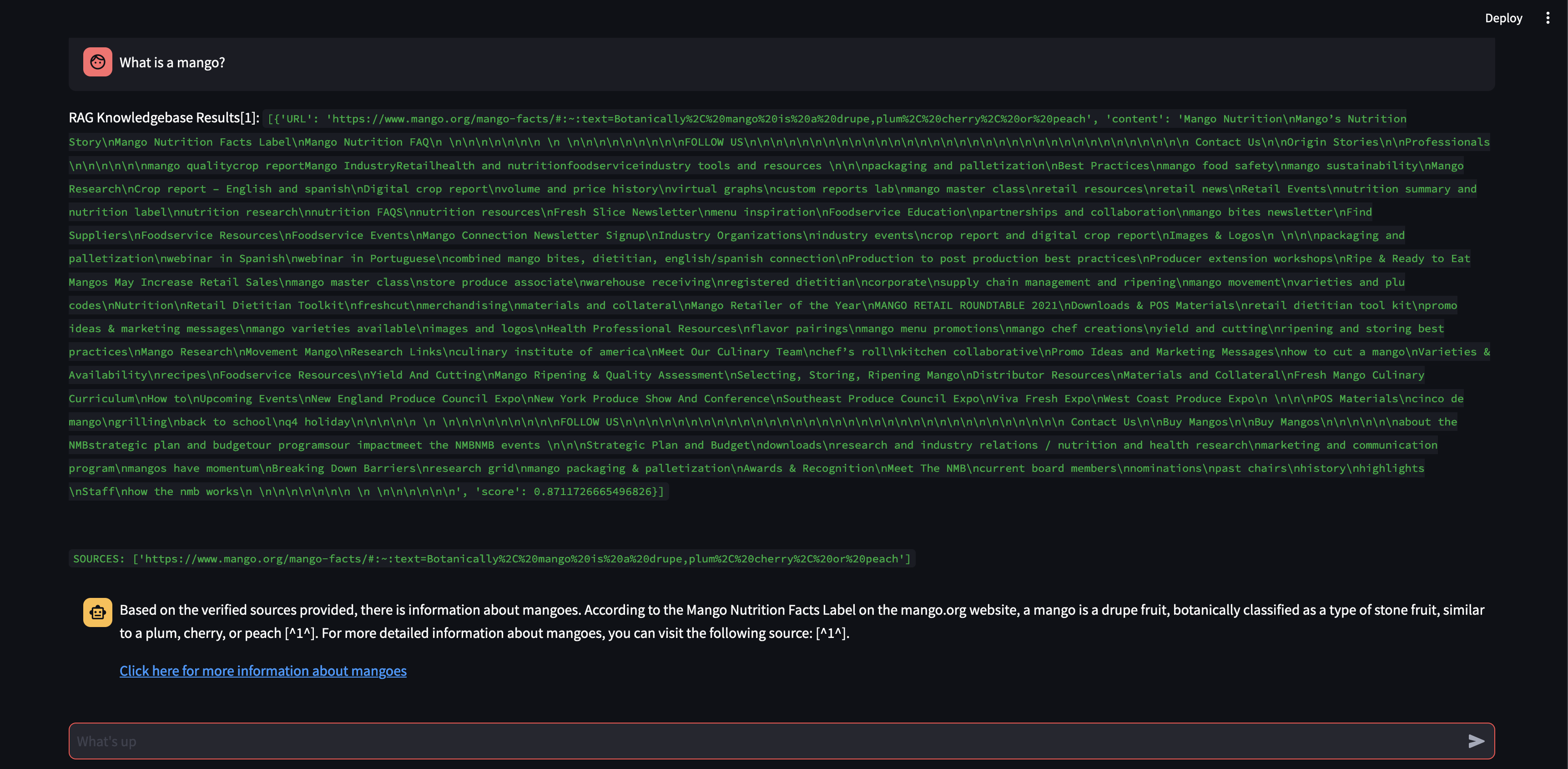
Теперь, благодаря большему размеру фрагмента, он смог точно сформулировать ответ, используя знания из векторной базы данных!
Давайте посмотрим, что доступно в базе знаний Агента, задав ему вопрос: Какие источники есть в вашей базе знаний?
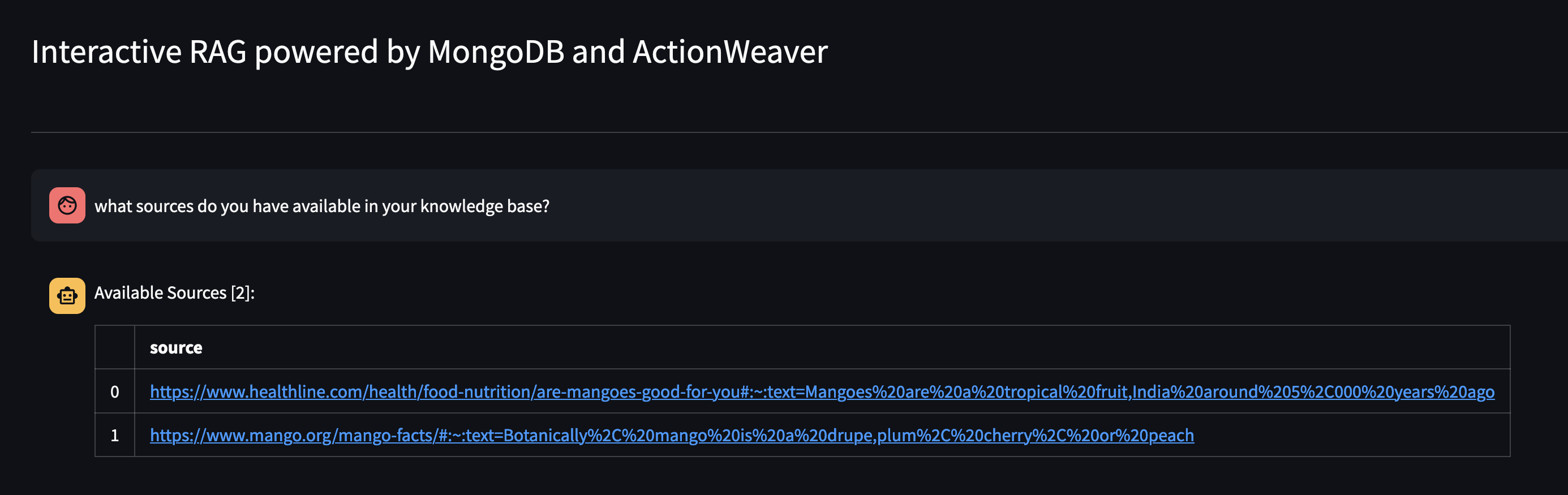
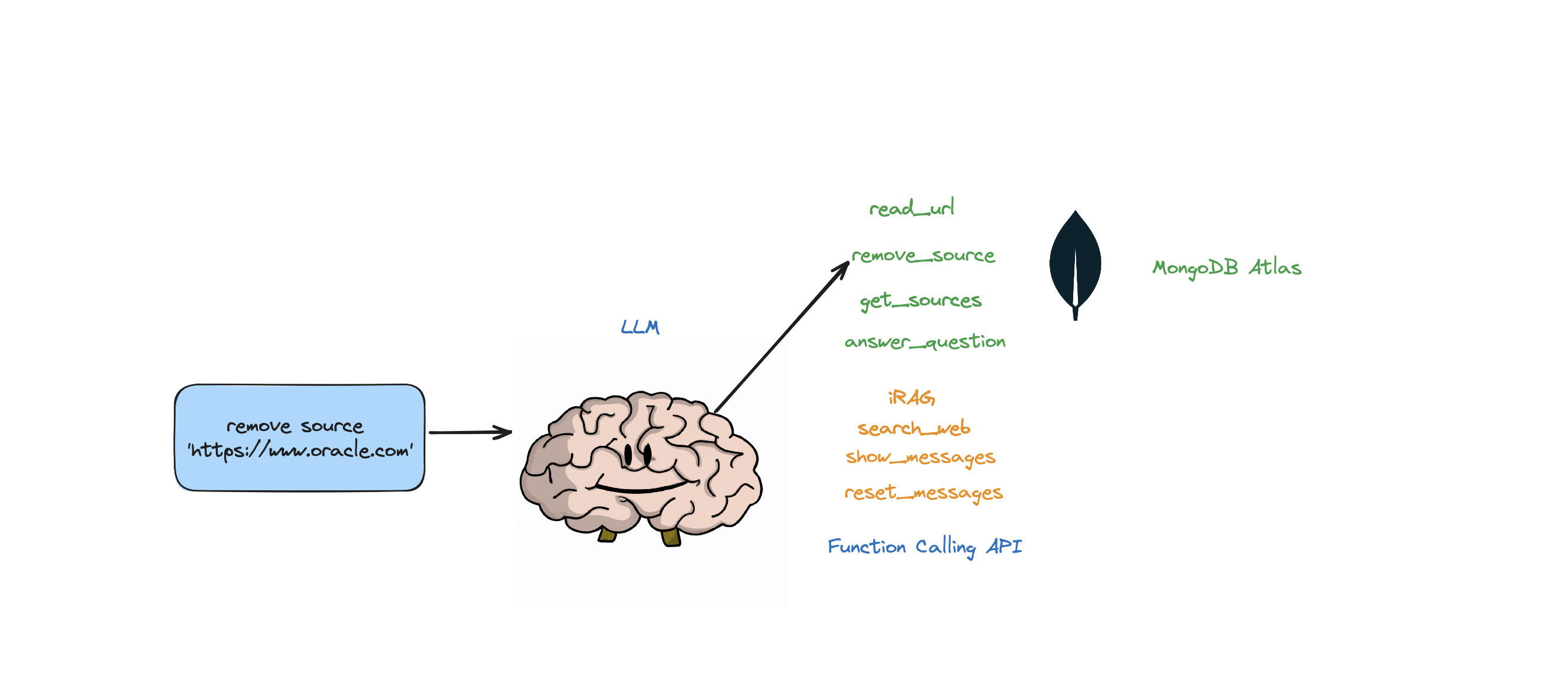
Если вы хотите удалить определенный ресурс, вы можете сделать что-то вроде:
USER: remove source 'https://www.oracle.com' from the knowledge base
Чтобы удалить все источники в коллекции. Мы могли бы сделать что-то вроде:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
Эта демонстрация позволила взглянуть на внутреннюю работу нашего ИИ-агента, продемонстрировав его способность обучаться и отвечать на запросы пользователей в интерактивном режиме. Мы стали свидетелями того, как компания органично сочетает свою внутреннюю базу знаний с веб-поиском в режиме реального времени для предоставления всеобъемлющей и точной информации. Потенциал этой технологии огромен и выходит далеко за рамки простого ответа на вопросы. Все это было бы невозможно без волшебства API вызова функций .
Это было вдохновлено https://github.com/TengHu/Interactive-RAG.
Мы приветствуем вклад сообщества открытого исходного кода.
Лицензия Апач 2.0


