build your local ragstack chatbot
1.0.0
Добро пожаловать на этот семинар, где вы сможете создать и развернуть свой собственный Enterprise Co-Pilot с использованием извлеченной дополненной генерации с помощью DataStax Enterprise v7, локального средства вывода и Mistral, локальной и открытой модели большого языка.
В этом хранилище основное внимание уделяется безопасности и защищенности, поскольку ваши конфиденциальные данные сохраняются за брандмауэром!
Почему?
Он использует DataStax RAGStack, который представляет собой тщательно подобранный стек лучшего программного обеспечения с открытым исходным кодом для упрощения реализации шаблона RAG в готовых к работе приложениях, которые используют DataStax Enterprise, Astra Vector DB или Apache Cassandra в качестве векторного хранилища.
Что вы узнаете:
? Как использовать DataStax RAGStack для готового к использованию следующих компонентов:
? Как использовать Ollama в качестве локального механизма вывода
? Как использовать Mistral в качестве локальной и открытой модели большого языка (LLM) для чат-ботов в стиле вопросов и ответов.
? Как использовать Streamlit, чтобы легко развернуть ваше потрясающее приложение!
Слайды презентации можно посмотреть ЗДЕСЬ.
Этот семинар предполагает, что у вас есть доступ к:
На следующих шагах мы подготовим репозиторий, DataStax Enterprise, Jupyter Notebook и механизм вывода Ollama с Ollama.
Прежде всего нам нужно клонировать этот репозиторий на ваш локальный ноутбук для разработки.
Откройте репозиторий build-your-local-ragstack-chatbot.
Нажмите Use this template -> Ceate new repository следующим образом:
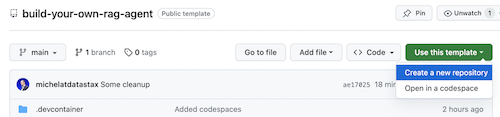
Теперь выберите свою учетную запись github и назовите новый репозиторий. В идеале также установите описание. Нажмите Create repository
Прохладный! Вы только что создали копию в своей учетной записи Gihub!
cd в разумный каталог (например, /projects или около того);git clone <url-to-your-repo>cd в новый каталог!И вы готовы к рок-н-роллу! ?
Полезно создать виртуальную среду . Используйте приведенную ниже информацию для настройки:
python3 -m venv myenv
Затем активируйте его следующим образом:
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
Теперь можно приступить к установке необходимых пакетов:
pip3 install -r requirements.txt
Запустите DSE 7 любым из этих двух способов из нового окна терминала:
docker-compose up
При этом используется файл docker-compose.yml в корне этого репозитория, который также удобно запускает интерпретатор Jupyter.
DataStax будет работать по адресу http://localhost:9042, а доступ к Jupyter будет осуществляться по адресу http://localhost:8888.
Существует множество механизмов вывода. Вы можете выбрать LM Studio с приятным пользовательским интерфейсом. В этом блокноте мы будем использовать Олламу.
ollama run mistral в новом окне терминала.Если все это не помогло из-за ограничений оперативной памяти, вы можете использовать tinyllama в качестве модели.
Чтобы начать этот семинар, мы сначала попробуем концепции из прилагаемого блокнота. Мы предполагаем, что вы будете работать из контейнера Jupyter Docker. В противном случае измените имена хостов с host.docker.internal на localhost .
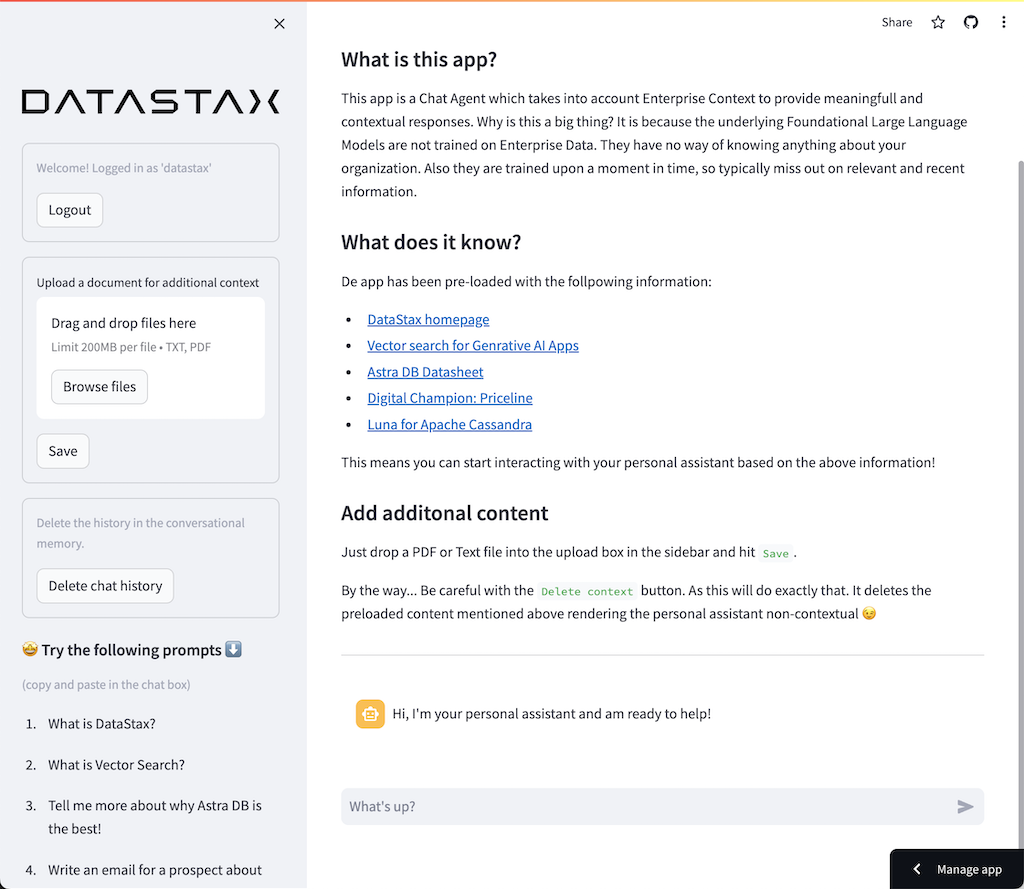
В этом блокноте показаны шаги, которые необходимо предпринять, чтобы использовать DataStax Enterprise Vector Store как средство, позволяющее сделать взаимодействие LLM осмысленным и без галлюцинаций. Здесь используется подход «Поисковая дополненная генерация».
Вы узнаете:
Перейдите по адресу http://localhost:8888 и откройте доступную в корне записную книжку с именем Build_Your_Own_RAG_Meetup.ipnb .
На этом семинаре мы будем использовать Streamlit — удивительно простую в использовании среду для создания интерфейсных веб-приложений.
Для начала давайте создадим приложение hello world следующим образом:
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () Первым шагом является импорт пакетаstreamlit. Затем мы вызываем st.markdown чтобы написать заголовок, и, наконец, записываем некоторый контент на веб-страницу.
Чтобы запустить это приложение локально, вам необходимо установить зависимостьstreamlit следующим образом (что уже должно быть сделано как часть предварительных условий):
pip install streamlitТеперь запустите приложение:
streamlit run app_1.pyЭто запустит сервер приложений и приведет вас на только что созданную веб-страницу.
Просто, не так ли? ?
На этом этапе мы начнем подготовку приложения для взаимодействия чат-бота с пользователем. Мы будем использовать следующие компоненты Streamlit: 1. 2. st.chat_input , чтобы пользователь мог ввести вопрос 2. st.chat_message('human') для отображения ввода пользователя 3. st.chat_message('assistant') чтобы нарисовать ответ чат-бота
В результате получается следующий код:
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) Попробуйте это, используя app_2.py, и начните следующим образом.
Если ваше предыдущее приложение все еще работает, просто закройте его, предварительно нажав ctrl-c .
streamlit run app_2.pyТеперь введите вопрос и введите еще раз. Вы увидите, что сохранен только последний вопрос.
Почему???
Это связано с тем, что Streamlit будет перерисовывать весь экран снова и снова на основе последних введенных данных. Поскольку мы не запоминаем вопросы, показывается только последний.
На этом этапе мы обязательно отслеживаем вопросы и ответы, чтобы при каждой перерисовке отображалась история.
Для этого предпримем следующие шаги:
st.session_state под названием messagesst.session_state под названием messagesfor message in st.session_state.messages Этот подход работает, поскольку session_state учитывает состояние во всех запусках Streamlit.
Ознакомьтесь с полным кодом в app_3.py.
Как вы увидите, мы используем словарь для хранения как role (которая может быть человеком или ИИ), так и question или answer . Отслеживать роль важно, поскольку она будет отображать правильную картинку в браузере.
Запустите его с помощью:
streamlit run app_3.pyТеперь добавьте несколько вопросов, и вы увидите, что они перерисовываются на экране каждый раз при повторном запуске Streamlit. ?
Здесь мы вернёмся к работе, которую мы проделали с использованием Jupyter Notebook, и объединим вопрос с вызовом модели чата Mistral.
Помните, что Streamlit перезапускает код каждый раз при взаимодействии пользователя? По этой причине мы будем использовать кэширование данных и ресурсов в Streamlit, чтобы соединение устанавливалось только один раз. Мы будем использовать @st.cache_data() и @st.cache_resource() для определения кэширования. cache_data обычно используется для структур данных. cache_resource в основном используется для таких ресурсов, как базы данных.
В результате получается следующий код для настройки модели подсказок и чата:
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()Вместо статического ответа, который мы использовали в предыдущих примерах, мы теперь переключимся на вызов Chain:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentОзнакомьтесь с полным кодом в app_4.py.
Прежде чем продолжить, нам необходимо указать OLLAMA_ENDPOINT в ./streamlit/secrets.toml . В secrets.toml.example приведен пример:
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "Чтобы запустить это приложение локально, вам необходимо установить RAGStack, который содержит стабильную версию LangChain и все зависимости (что уже должно быть сделано как часть предварительных условий):
pip install ragstackТеперь запустите приложение:
streamlit run app_4.pyТеперь вы можете начать взаимодействие с чат-ботом в режиме вопросов и ответов. Разумеется, поскольку интеграции с DataStax Enterprise Vector Store нет, контекстуализированных ответов не будет. Поскольку встроенной потоковой передачи пока нет, дайте агенту немного времени, чтобы сразу дать полный ответ.
Начнем с вопроса:
What does Daniel Radcliffe get when he turns 18?
Как вы увидите, вы получите очень общий ответ без информации, доступной в данных CNN.
Теперь все становится по-настоящему интересно! На этом этапе мы интегрируем хранилище векторов DataStax Enterprise, чтобы обеспечить контекст в режиме реального времени для модели чата. Шаги, предпринятые для реализации поисковой дополненной генерации:
Мы будем повторно использовать данные CNN, которые мы вставили благодаря блокноту.
Чтобы включить это, нам сначала нужно настроить соединение с DataStax Enterprise Vector Store:
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()Единственное, что нам нужно сделать, это изменить цепочку, включив в нее вызов векторного хранилища:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})Ознакомьтесь с полным кодом в app_5.py.
Прежде чем продолжить, нам необходимо предоставить DSE_ENDPOINT , DSE_KEYSPACE и DSE_TABLE в ./streamlit/secrets.toml . В secrets.toml.example приведен пример:
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "И запустите приложение:
streamlit run app_5.pyДавайте еще раз зададимся вопросом:
What does Daniel Radcliffe get when he turns 18?
Как вы увидите, теперь вы получите очень контекстный ответ, поскольку хранилище векторов предоставляет соответствующие данные CNN в модель чата.
Как было бы здорово увидеть ответ на экране по мере его генерации! Ну, это легко.
Прежде всего, мы создадим обработчик обратного вызова потоковой передачи, который вызывается при каждом новом генерировании токена следующим образом:
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )Затем мы объясним модель чата, чтобы сделать пользователя StreamHandler:
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) response_placeholer в приведенном выше коде определяет место, куда необходимо записать токены. Мы можем создать это пространство, вызвав st.empty() следующим образом:
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()Ознакомьтесь с полным кодом в app_6.py.
И запустите приложение:
streamlit run app_6.pyТеперь вы увидите, что ответ будет записан в окне браузера в режиме реального времени.
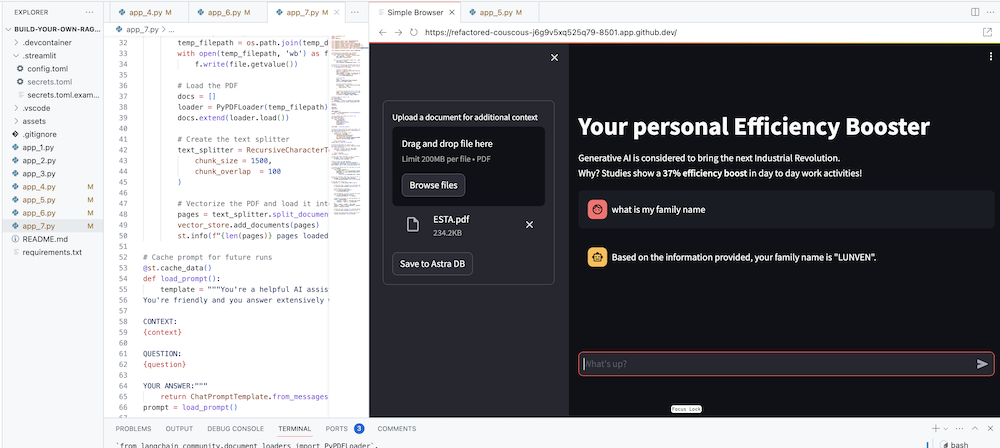
Конечной целью, конечно же, является добавление к агенту контекста вашей компании. Для этого мы добавим окно загрузки, которое позволит вам загружать PDF-файлы, которые затем будут использоваться для предоставления осмысленного и контекстуального ответа!
Сначала нам нужна форма загрузки, которую легко создать с помощью Streamlit:
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )Теперь нам нужна функция для загрузки PDF-файла и его вставки в DataStax Enterprise при векторизации содержимого.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )Ознакомьтесь с полным кодом в app_7.py.
Чтобы запустить это приложение локально, вам необходимо установить зависимость PyPDF следующим образом (что уже должно быть сделано как часть предварительных требований):
pip install pypdfИ запустите приложение:
streamlit run app_7.pyТеперь загрузите PDF-документ (чем больше, тем лучше), который вам подходит, и начните задавать о нем вопросы. Вы увидите, что ответы будут актуальными, значимыми и контекстуальными! ? Посмотрите, как происходит волшебство!