php rag
v1.1.0
Это приложение использует LLM (большая языковая модель) GPT-4o, доступ к которому осуществляется через API OpenAI, для генерации текста на основе пользовательского ввода. Пользовательский ввод используется для извлечения соответствующей информации из базы данных, а затем полученная информация используется для генерации текста. Этот подход сочетает в себе мощь преобразователей и доступ к исходным документам.
В этом конкретном приложении в базе данных более 1000 веб-сайтов осуществляется поиск информации, относящейся к конкретному человеку. Настоящая проблема здесь заключается в том, что искомый человек «Михал Жарнецкий» появляется в двух разных контекстах как два разных человека с одинаковым именем. Цель состоит в том, чтобы не только найти конкретную информацию, но и понять контекст и избежать ошибок, таких как смешивание информации о двух разных людях с одинаковым именем.
Я описал концепции, используемые в этом приложении, более подробно в статье на Medium.com https://medium.com/@michalzarnecki88/a-guide-to-using-llm-retrieval-augmented-generation-with-php-3bff25ce6616.
Для установки вам необходимо сначала установить Docker и Docker Compose https://docs.docker.com/compose/install/.
Запуск в CLI: cd app/src && composer install
Настройка языковой модели — выберите один из вариантов ниже: вариант с OpenAI API
«А» с бесплатной моделью через локальный API3 ollama.
«Б» с OpenAI API
Вариант Б проще и требует меньше ресурсов ЦП и ОЗУ, но вам нужен ключ OpenAI API https://platform.openai.com/settings/profile?tab=api-keys Вариант А требует больше ресурсов ЦП и ОЗУ, но вы можете запустить это локально с использованием API ollama. Для этого варианта хорошо иметь графический процессор.
Следуйте инструкциям для предпочтительного варианта A или B ниже:
Если вы хотите настроить ollama локально, воспользуйтесь инструкциями внизу этого файла, но в случае использования Docker это не понадобится.
*Ollama предоставляет локальный API для LLM: «Приступайте к работе с большими языковыми моделями». https://ollama.com/
docker-compose up
*СОВЕТ: сначала скрипту необходимо преобразовать исходные документы, что может занять даже 30 минут. Если вы хотите сэкономить время, просто удалите часть документов из app/src/documents.
Подождите, пока завершится настройка контейнеров — в логах консоли вы должны увидеть:
php-app | Loaded documents complete
php-app | Postgres is ready - executing command
php-app | [Sat Nov 02 11:32:28.365214 2024] [core:notice] [pid 1:tid 1] AH00094: Command line: 'apache2 -D FOREGROUND'
Вы можете использовать приложение в качестве API, используя запросы, как показано ниже:
Вариант А оллама:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processOllama.php?api
Вариант Б OpenAI GPT:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processGpt.php?api
Запустите интерактивный docker exec -it php-app sh
Запуск в CLI: php minicli rag
Задать вопрос
##### INPUT:
What is the result of 2 + 2?
##### RESPONSE:
The result of 2 + 2 is 4.
##### INPUT:
what is specialization of Michał Żarnecki based on his website content
##### RESPONSE:
Michał Żarnecki is a programmer and lecturer specializing in several key areas related to modern software development and data-driven technologies.
His expertise includes:
1. **Programming Languages**: Python, PHP, JavaScript.
2. **AI and Machine Learning**: Designing systems and solutions related to artificial intelligence and machine learning.
3. **Data Mining and Big Data**: Extracting valuable insights from large datasets.
4. **Natural Language Processing (NLP)**: Working on systems that understand and generate human language.
5. **Software Development Frameworks**: Utilizing various tools and frameworks such as Streamlit, TensorFlow, PyTorch, and langchain.
6. **Database Systems**: Implementing and working with databases like PostgreSQL, Elasticsearch, Neo4j, and others.
His portfolio highlights projects such as an AI chatbot for analyzing company documents and a self-driving vehicle based on TensorFlow and Raspberry Pi.
Additionally, he has contributed to conferences and created e-learning courses focused on machine learning, underscoring his dual role as a developer and educator.
##### INPUT:
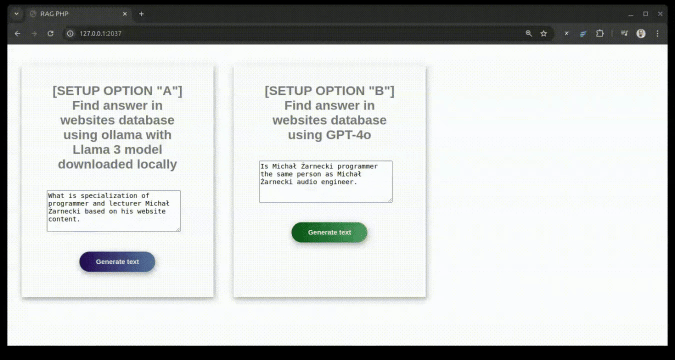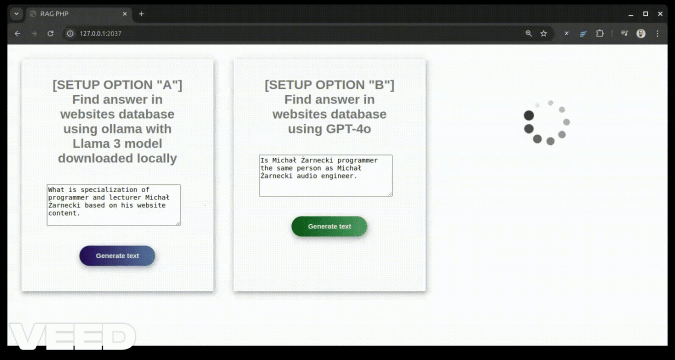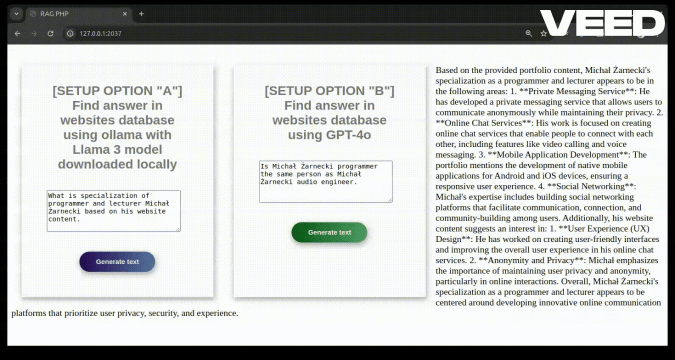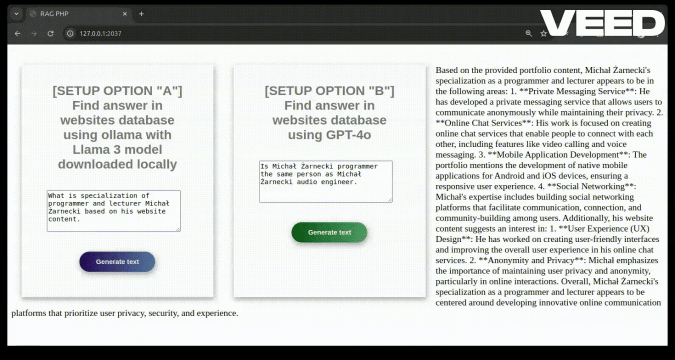
Is Michał Żarnecki programmer the same person as Michał Żarnecki audio engineer?
##### RESPONSE:
Based on the information provided, it appears that Michał Żarnecki the programmer and Michał Żarnecki the audio engineer are not the same person.
Here’s why:
1. **Fields of Expertise**:
- Michał Żarnecki, the audio engineer, was a well-known operator and reżyser dźwięku (sound director) in Poland, with notable contributions to the Polish film industry, as mentioned in the Wikipedia excerpt.
- Michal Żarnecki, the programmer, has a portfolio focused on programming in Python, PHP, and JavaScript, with projects related to AI, machine learning, data mining, and software development.
2. **Lifespan**:
- Michał Żarnecki the audio engineer was born on November 12, 1946, and passed away on November 21, 2016.
- The projects listed in Michał Żarnecki the programmer’s portfolio date from 2014 to 2016, which would be conflicting if he had passed away in 2016 and was actively working in those years.
3. **Occupational Focus**:
- The audio engineer has a career documented in film sound engineering and education.
- The programmer’s career is centered around software development, mobile applications, ERP systems, and consulting in technology.
Given the distinct differences in their professional domains, timelines, and expertise, it is highly unlikely that they are the same individual
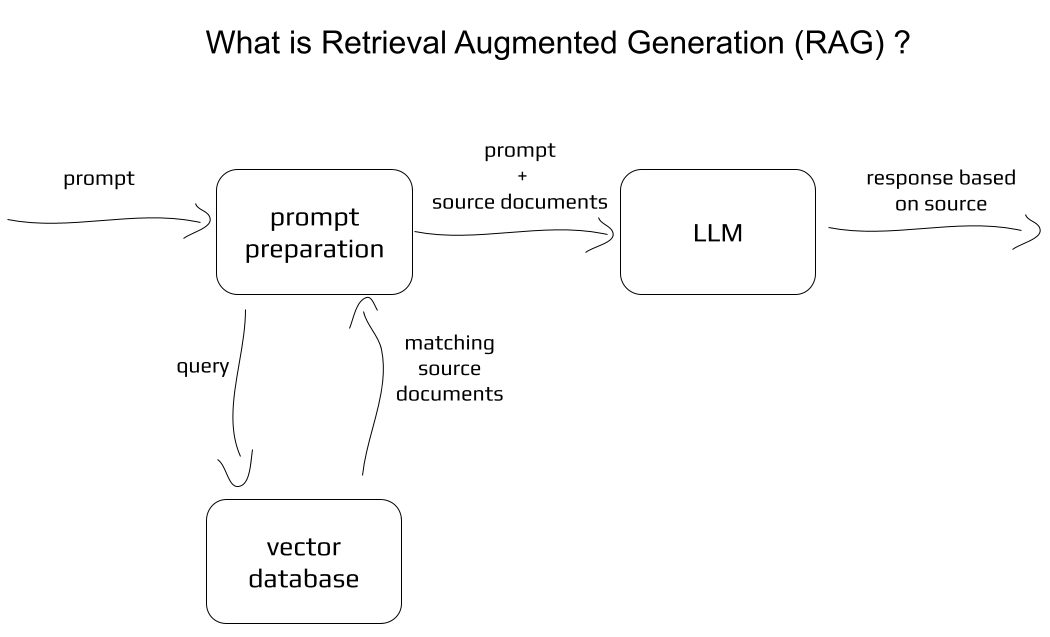
Основная концепция:
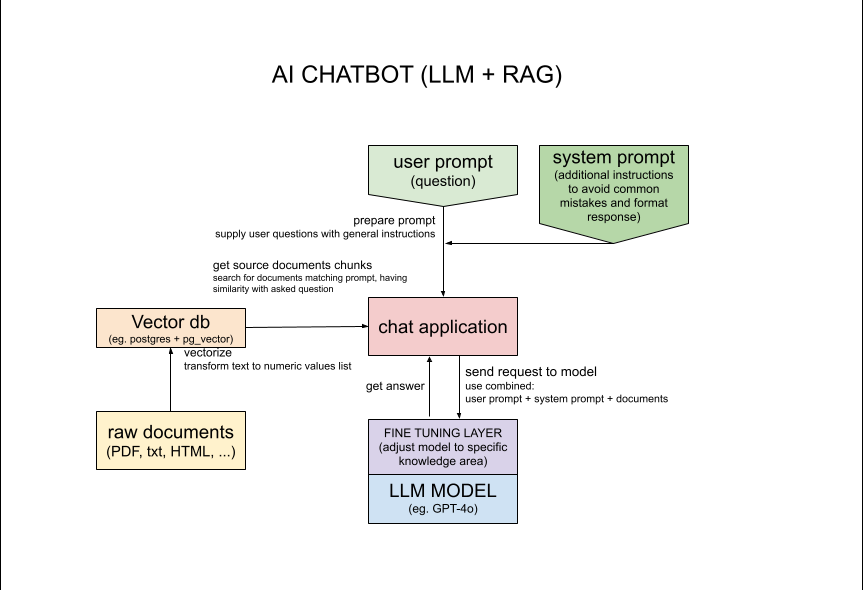
Подробности для ботаников:
Чтобы ускорить загрузку документов или использовать больше документов для лучшего поиска, манипулируйте значением $skipFirstN в app/src/service/DocumentLoader.php:20.
После изменений в PHP-скриптах пересоберите докер с помощью команд:
docker-compose rm
docker rmi -f php-rag
docker-compose up
веб-сайты, используемые для заполнения базы данных векторов, взяты из набора данных «Классификация веб-сайтов» на Kaggle. Автор: Хетул Мехта. Ссылка: https://www.kaggle.com/datasets/hetulmehta/website-classification?resource=download.
связанные статьи/репозитории:
https://medium.com/mlearning-ai/create-a-chatbot-in-python-with-langchain-and-rag-85bfba8c62d2
https://github.com/Krisseck/php-rag
https://ollama.com/downloadollama pull llama3:latestollama pull mxbai-embed-large ollama list
NAME ID SIZE MODIFIED
mxbai-embed-large:latest 468836162de7 669 MB 7 seconds ago
llama3:latest 365c0bd3c000 4.7 GB 17 seconds ago
ollama serveapp/src/loadDocuments.php (по умолчанию) Пожалуйста, дайте мне знать, если вы обнаружите какие-либо проблемы или вещи, которые можно улучшить. Вы можете связаться со мной по адресу электронной почты [email protected]. Не стесняйтесь сообщать об ошибках и предлагать обновления в запросах на включение.


