files search guide
1.0.0
Целью данного руководства является описание инструментов для поиска и упрощения поиска текстовой информации в большинстве популярных файлов и баз данных.
Это могло бы принести пользу журналистским расследованиям, работе с большими объемами данных, такими как утечки документов и обнаружение электронных данных.
Руководство применимо для поиска нарушений различных форматов (архивные большие текстовые файлы, csv/sql), документов (pdf, xls/x, doc/x) и в специализированных базах данных (1С, Кронос и др.).
Английская версия | Русская версия
Datashare — мультиоперационная платформа от ICIJ, предназначенная для обмена большими наборами данных документов, особенно среди исследователей и журналистов.
Он позволяет выполнять поиск в PDF-файлах, изображениях, текстах, электронных таблицах, слайдах и многом другом.
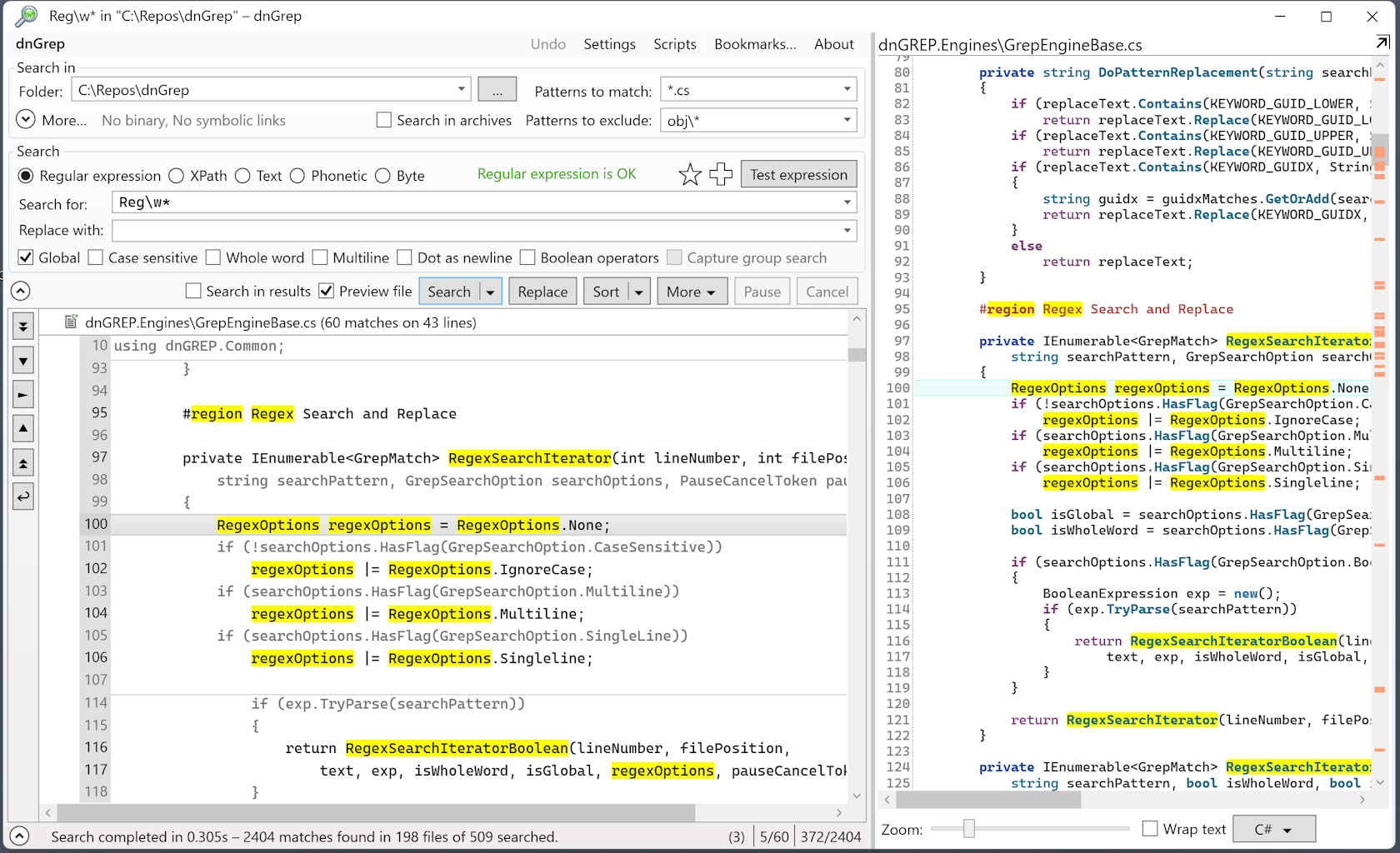
dnGrep — инструмент с графическим интерфейсом для Windows, способный осуществлять поиск по текстовым файлам, документам PDF и архивам самых популярных форматов. Поддерживаются регулярные выражения и рекурсивный поиск по каталогам. Дополнительные возможности: интеграция с Windows Explorer!
Несмотря на некоторые проблемы с визуализацией поиска и сбои при работе с большими архивами, dnGrep выглядит наиболее перспективным инструментом для массового поиска в текстовых файлах.
AstroGrep — инструмент с графическим пользовательским интерфейсом для Windows, который позволяет пользователям выполнять текстовый поиск по нескольким файлам, что делает его особенно полезным для тех, кому необходимо управлять большими наборами документов. Он поддерживает различные форматы файлов и предлагает удобный интерфейс.
К основным преимуществам AstroGrep относится его способность предоставлять быстрые результаты текстового поиска в огромном массиве файлов. Кроме того, AstroGrep выделяет искомые термины в файлах, что упрощает процесс просмотра результатов поиска. Он также включает в себя полезные функции, такие как сопоставление регулярных выражений, что позволяет выполнять более сложный и точный поиск.
Однако AstroGrep в первую очередь ориентирован на текстовый поиск, поэтому его полезность ограничивается текстовыми данными и не распространяется на поиск в документах Excel, архивах, изображениях или аудиофайлах.
Google Pinpoint — облачный инструмент, призванный помочь журналистам управлять большими объемами информации. Он поддерживает различные типы файлов, включая документы (почти все конвертирует в PDF), изображения и аудиофайлы, а также интегрируется с Google Диском для эффективного управления данными. Этот инструмент повышает эффективность исследований, позволяя осуществлять быстрый поиск по обширным наборам данных.
К преимуществам Pinpoint относятся надежные возможности поиска, которые экономят время за счет упрощения процесса просмотра данных. Он также поддерживает совместную работу, позволяя нескольким пользователям одновременно работать над одним проектом.
Однако, поскольку это облачный инструмент, ему требуется стабильное подключение к Интернету.
Инструмент Unix grep является стандартом поисковиков. Вам следует передать только два параметра: шаблон поиска и файл, и инструмент будет искать строки, соответствующие шаблону. Шаблон может представлять собой простую строку (например, номер телефона или адрес электронной почты).
grep используется другими утилитами (или только ее синтаксисом), поэтому давайте рассмотрим некоторые основные аргументы:
-A number — вывести number строк контекста после каждого совпадения.
-B number — печатать number строк контекста перед каждым совпадением
-C number — вывести number строк контекста, окружающих каждое совпадение.
-i - поиск без учета регистра: поиск по Target слову и target слова будут найдены TARGET
-R — рекурсивный поиск: инструмент сканирует все вложенные каталоги (вы можете использовать * в качестве имени файла)
-a — считать все файлы текстовыми, использовать в случае ошибки. Binary file (standard input) matches
Пример использования grep :
grep -iR target dumps/* — поиск по слову target (без учета регистра) во всех текстовых файлах в каталоге dumps
Лучше всего конвертировать файлы XLSX в CSV и использовать grep для поиска или просто использовать инструмент xlsxgrep .
Пример использования:
xlsxgrep target -H -N -r dumps/*
Для поиска в архивах .gz и .tgz лучше всего использовать zgrep .
Инструмент является прямым аналогом grep за исключением следующего:
-R не поддерживается Пример использования zgrep :
zgrep -ia target dumps/* — поиск по слову target (без учета регистра) во всех текстовых файлах и в gz-архивах и в дампах каталогов dumps
Для поиска в архивах 7z лучше всего использовать инструмент распаковки 7zip с grep :
Пример использования:
7z x archive.7z -so | grep ...
7zip также может работать с другими типами архивов.
Лучше всего использовать инструмент распаковки unrar с grep для поиска в архивах rar:
Пример использования:
unrar p archive.rar | grep ...
В России существует популярная программа для работы с базами данных и форматом файлов Cronos . Лучше всего использовать соответствующую версию официального клиента (Cronos, CronosPlus, CronosPro) или просто преобразовать базу данных в файл CSV с помощью инструмента cronodump:
git clone https://github.com/alephdata/cronodump && cd cronodump
python3 setup.py install
croconvert --csv cronos_db_directory/
# a new directory will be created
ls cronodump-2022-04-25-02-53-57-293000
БТК.csv Files-FL
grep ...
В России есть популярная программа 1С. 1С использует собственные форматы файлов: .1CD, .efd и другие. Вы можете использовать onec_dtools для написания собственного скрипта для извлечения всех данных из базы данных 1С или использовать 1с-конвертер баз данных для преобразования базы данных в файлы CSV.
./run.py 8-2-14.1CD
Target: 8-2-14.1CD
Results found: 1
1) Out Dir: 8-2-14.1CD_csv
File Type: 1CD
Status: Exported content of 1CD file
------------------------------
Total found: 1


