korpatbert
1.0.0
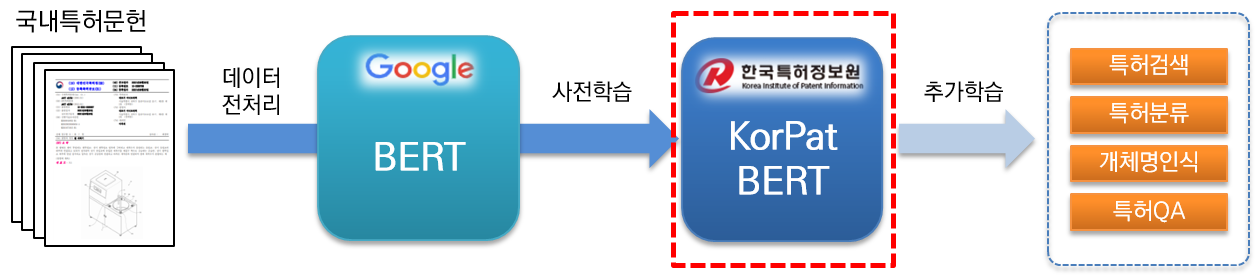
KorPatBERT (корейский патентный BERT) — это языковая модель искусственного интеллекта, исследованная и разработанная Службой патентной информации Кореи.
Чтобы решить проблемы обработки корейского естественного языка в патентной области и подготовить интеллектуальную информационную инфраструктуру в патентной отрасли, проводится предварительное обучение по большому количеству отечественных патентных документов (база: около 4,06 миллиона документов, большая: около 5,06 миллиона документов). основан на архитектуре существующей базовой модели Google BERT (предварительное обучение) и предоставляется бесплатно.
Это высокопроизводительная предварительно обученная языковая модель, специализирующаяся на патентной области, которую можно использовать в различных задачах обработки естественного языка.
[КорПатБЕРТ-база]
[КорПатБЕРТ-большой]
[КорПатБЕРТ-база]
[КорПатБЕРТ-большой]
Примерно 10 миллионов основных и составных существительных были извлечены из патентных документов, используемых при изучении языковых моделей, и добавлены в пользовательский словарь корейского анализатора морфем Mecab-ko, а затем разделены на подслова с помощью Google SentencePiece. Это специализированный MSP. токенизатор (патентный токенизатор Mecab-ko Sentencepiece).
| модель | Топ@1(ACC) |
|---|---|
| Google БЕРТ | 72,33 |
| КОРБЕРТ | 73,29 |
| КОБЕРТ | 33,75 |
| КрБЕРТ | 72,39 |
| КорПатБЕРТ-база | 76,32 |
| КорПатБЕРТ-большой | 77.06 |
| модель | Топ@1(ACC) | Топ@3(ACC) | Топ@5(АСС) |
|---|---|---|---|
| КорПатБЕРТ-база | 61,91 | 82,18 | 86,97 |
| КорПатБЕРТ-большой | 62,89 | 82,18 | 87,26 |
| Название программы | версия | Путь руководства по установке | Необходимый? |
|---|---|---|---|
| питон | 3.6 и выше | https://www.python.org/ | Да |
| анаконда | 4.6.8 и выше | https://www.anaconda.com/ | Н |
| тензорный поток | 2.2.0 и выше | https://www.tensorflow.org/install/pip?hl=ko | Да |
| кусок предложения | 0.1.96 или выше | https://github.com/google/sentencepiece | Н |
| мекаб-ко | 0.996-ан-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Да |
| мекаб-ко-дик | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Да |
| мекаб-питон | 0.996-ан-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Да |
| python-mecab-ko | 1.0.11 или выше | https://pypi.org/project/python-mecab-ko/ | Да |
| керас | 2.4.3 и выше | https://github.com/keras-team/keras | Н |
| bert_for_tf2 | 0.14.4 и выше | https://github.com/kpe/bert-for-tf2 | Н |
| tqdm | 4.59.0 и выше | https://github.com/tqdm/tqdm | Н |
| соинлп | 0.0.493 или выше | https://github.com/lovit/soynlp | Н |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ Это тот же базовый метод обучения Google BERT, примеры использования см. в разделе 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
Мы распространяем языковую модель Корейского института патентной информации посредством определенных процедур среди заинтересованных в ней организаций, компаний и исследователей. Пожалуйста, заполните форму заявки и соглашение в соответствии с процедурой подачи заявки, приведенной ниже, и отправьте заявку по электронной почте ответственному лицу.
| имя файла | объяснение |
|---|---|
| pat_all_mecab_dic.csv | Патентный пользовательский словарь Mecab |
| lm_test_data.tsv | Пример набора данных классификации |
| korpat_tokenizer.py | Программа токенизатора KorPat |
| test_tokenize.py | Пример использования токенайзера |
| test_tokenize.ipynb | Пример использования токенизатора (Юпитер) |
| test_lm.py | Пример использования языковой модели |
| test_lm.ipynb | Пример использования языковой модели (Jupyter) |
| korpat_bert_config.json | Конфигурационный файл KorPatBERT |
| korpat_vocab.txt | Словарные файлы KorPatBERT |
| model.ckpt-381250.meta | Файл модели KorPatBERT |
| модель.ckpt-381250.index | Файл модели KorPatBERT |
| model.ckpt-381250.data-00000-of-00001 | Файл модели KorPatBERT |


