альпака-rlhf
Точная настройка LLaMA с помощью RLHF (обучение с подкреплением и обратной связью с человеком).
Онлайн-демо
Изменения в чате DeepSpeed
Шаг 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- Установить специальные жетоны
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Тренируйтесь только на ответах и добавляйте eos
- Удалить end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
- Метки отличаются от входных данных
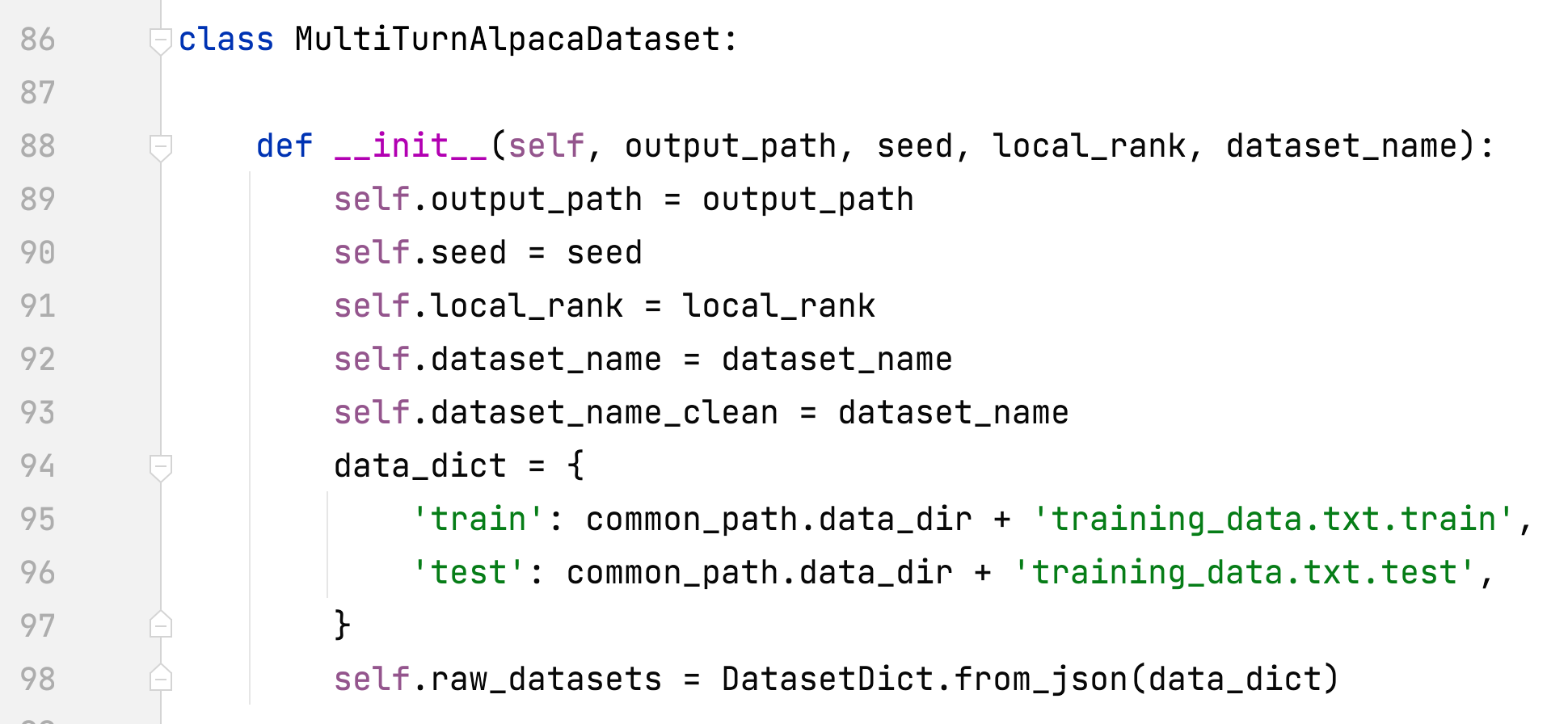
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- добавить MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- Поддержка нескольких имен модулей для lora
Шаг 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- Установить специальные жетоны
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- Исправление численной нестабильности
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Удалить end_of_conversation_token
Шаг 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- Установите специальные жетоны
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Исправить ошибку максимальной длины
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# вызов
- Исправить ошибку боковой прокладки
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
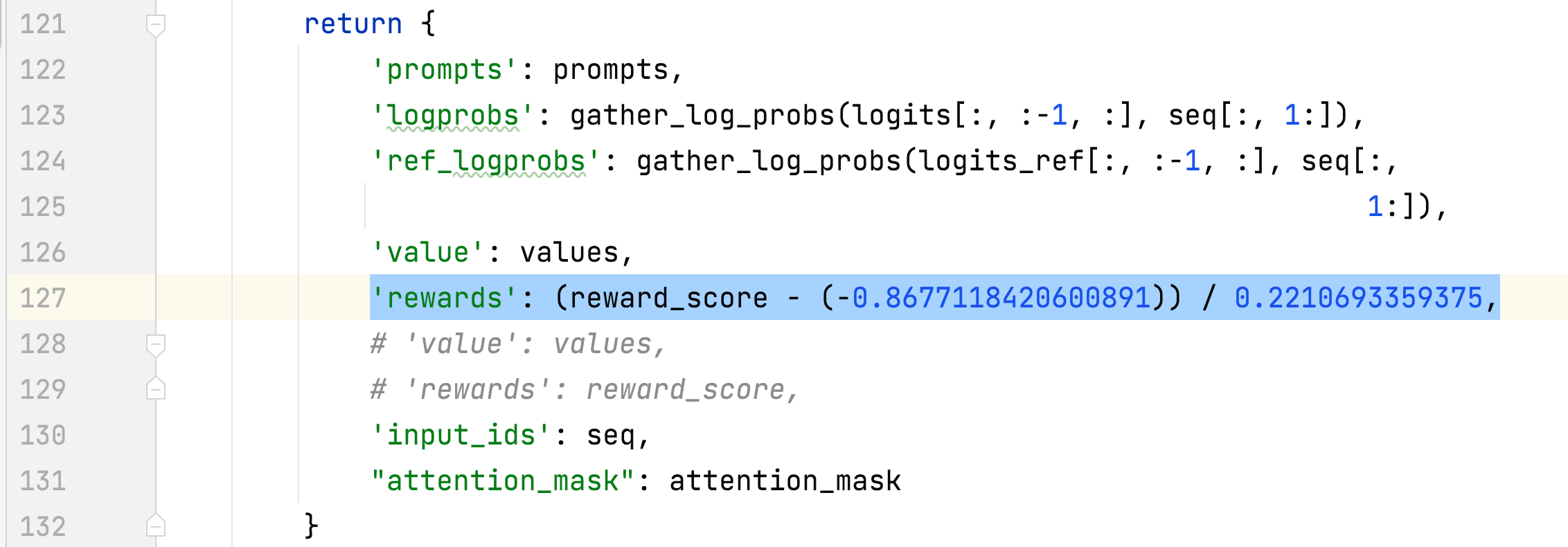
- Нормализовать вознаграждение
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
- Замаскируйте токены после eos
Стэй за шагом
- Выполнение всех трех шагов на 2 x A100 80G.
- Наборы данных
- Dahoas/rm-static HuggingFace Paper GitHub
- MultiTurnАльпака
- Это многоходовая версия набора данных альпака, построенная на основе AlpacaDataCleaned и ChatAlpaca.
- Сначала войдите в каталог ./alpaca_rlhf, затем выполните следующие команды:
- шаг 1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- при добавлении --sft_only_data_path MultiTurnAlpaca сначала разархивируйте data/data.zip.
- шаг 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -хф --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
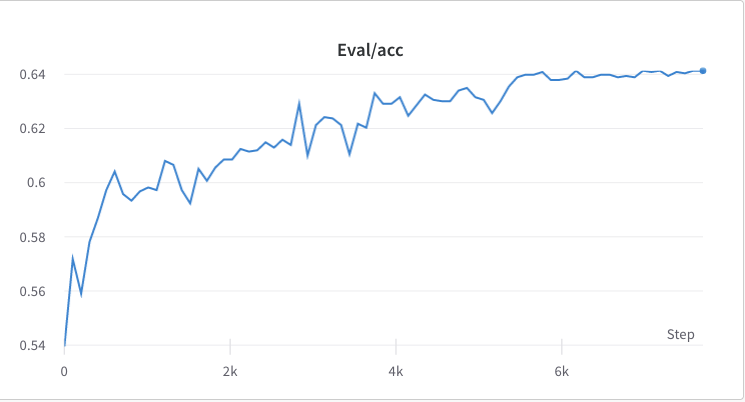
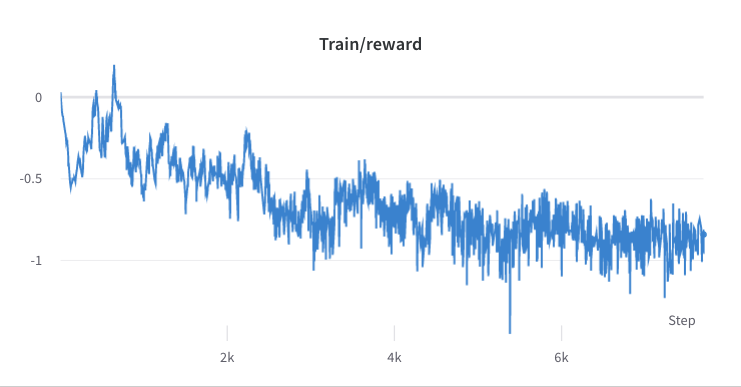
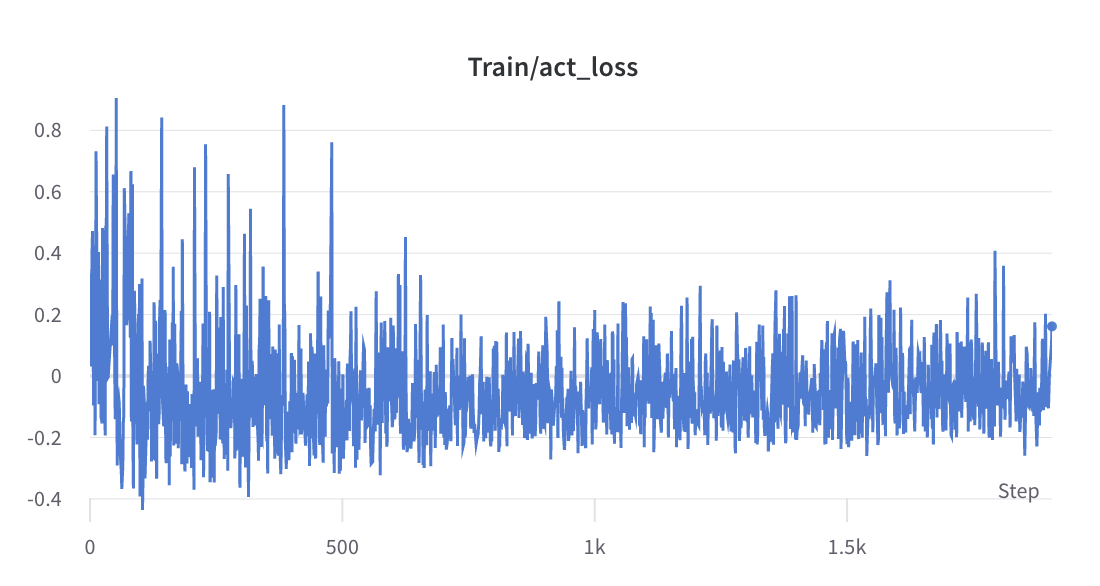
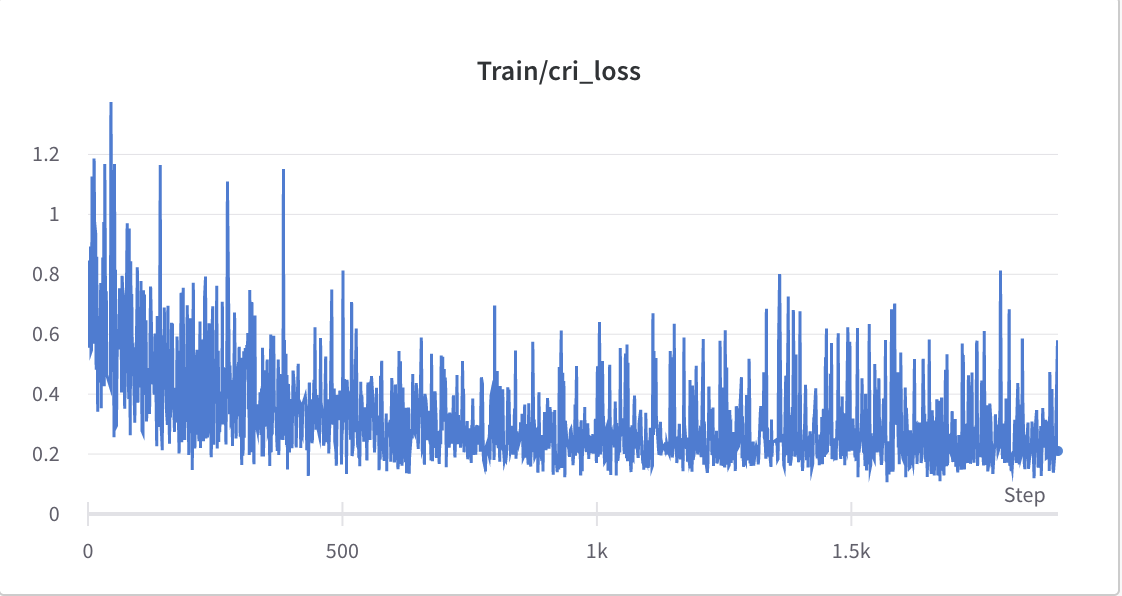
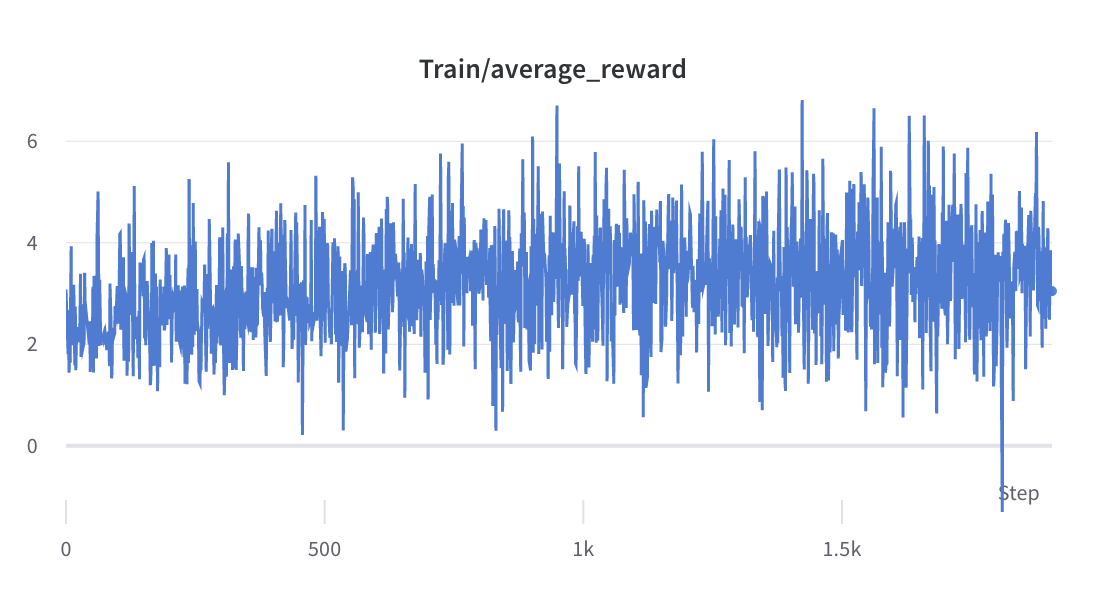
- тренировочный процесс шага 2
- Среднее и стандартное отклонение вознаграждения за выбранные ответы собираются и используются для нормализации вознаграждения на этапе 3. В одном эксперименте они составляют -0,8677118420600891 и 0,2210693359375 соответственно и используются в alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience методы: 'rewards': (reward_score - (-0,8677118420600891)) / 0,2210693359375.
- шаг 3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/rlhf/actor/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
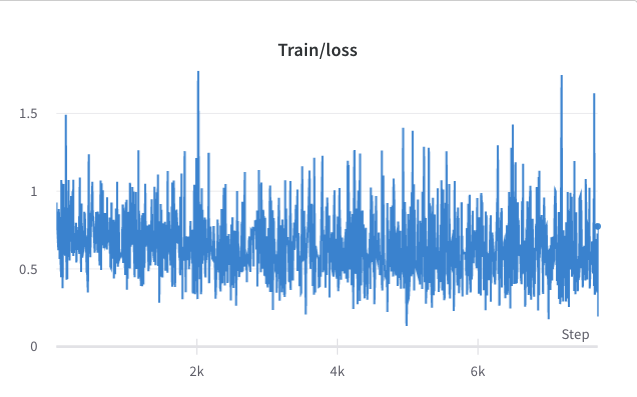
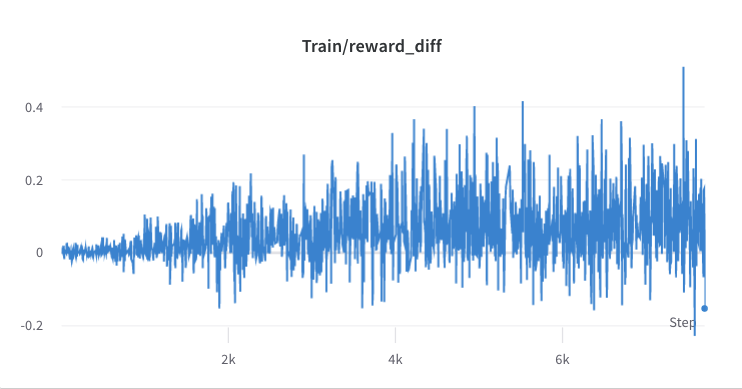
- тренировочный процесс шага 3
- Вывод
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
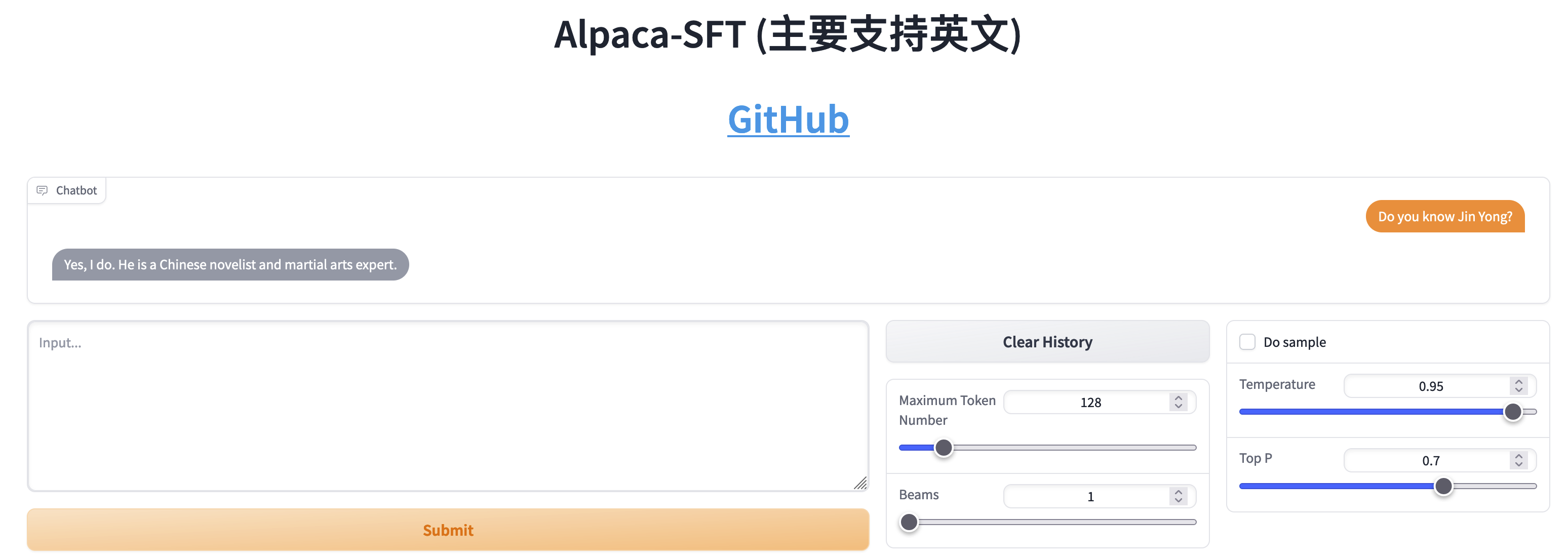
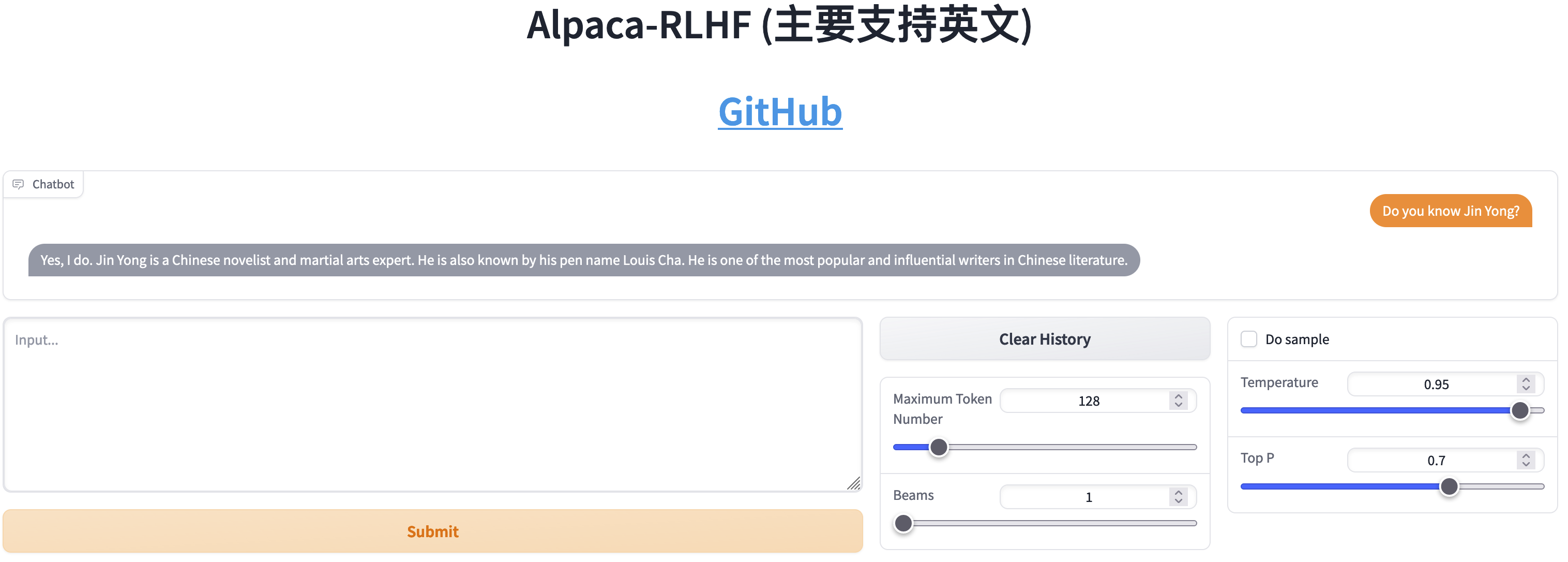
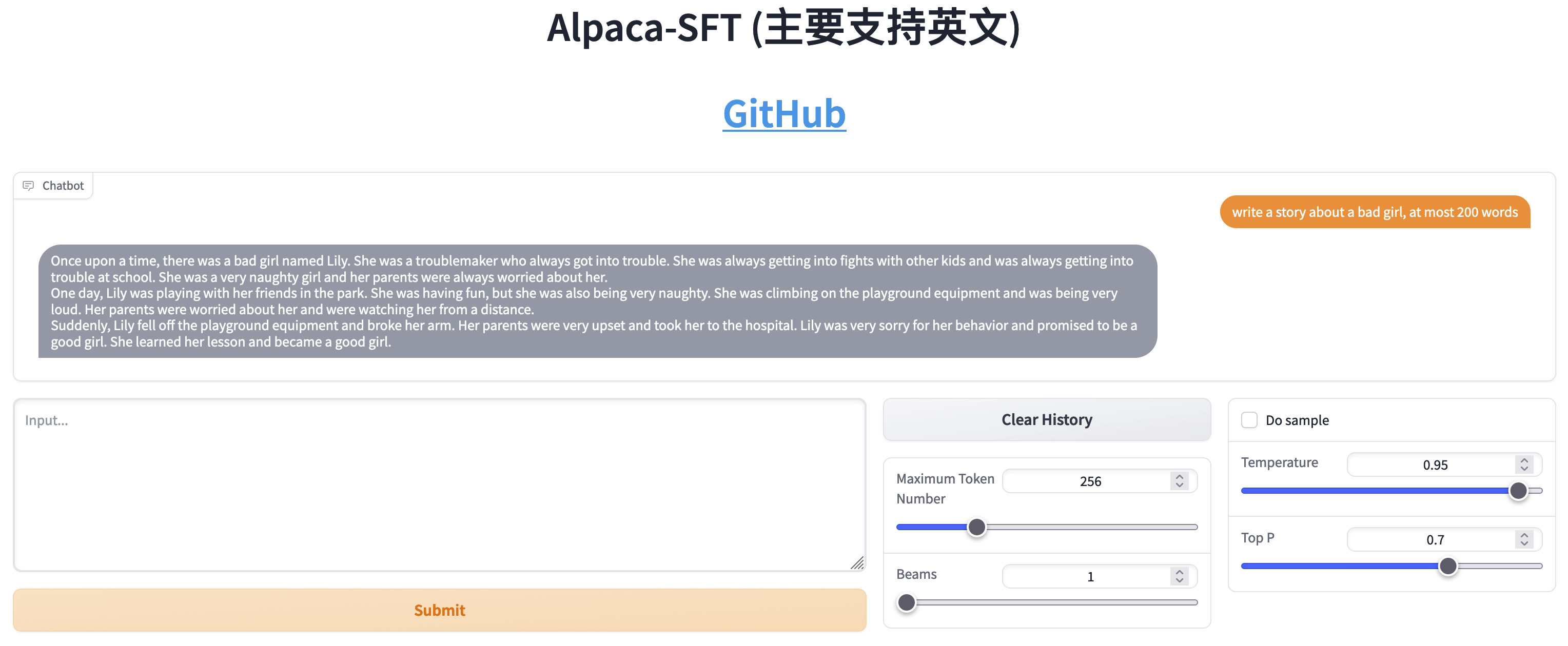
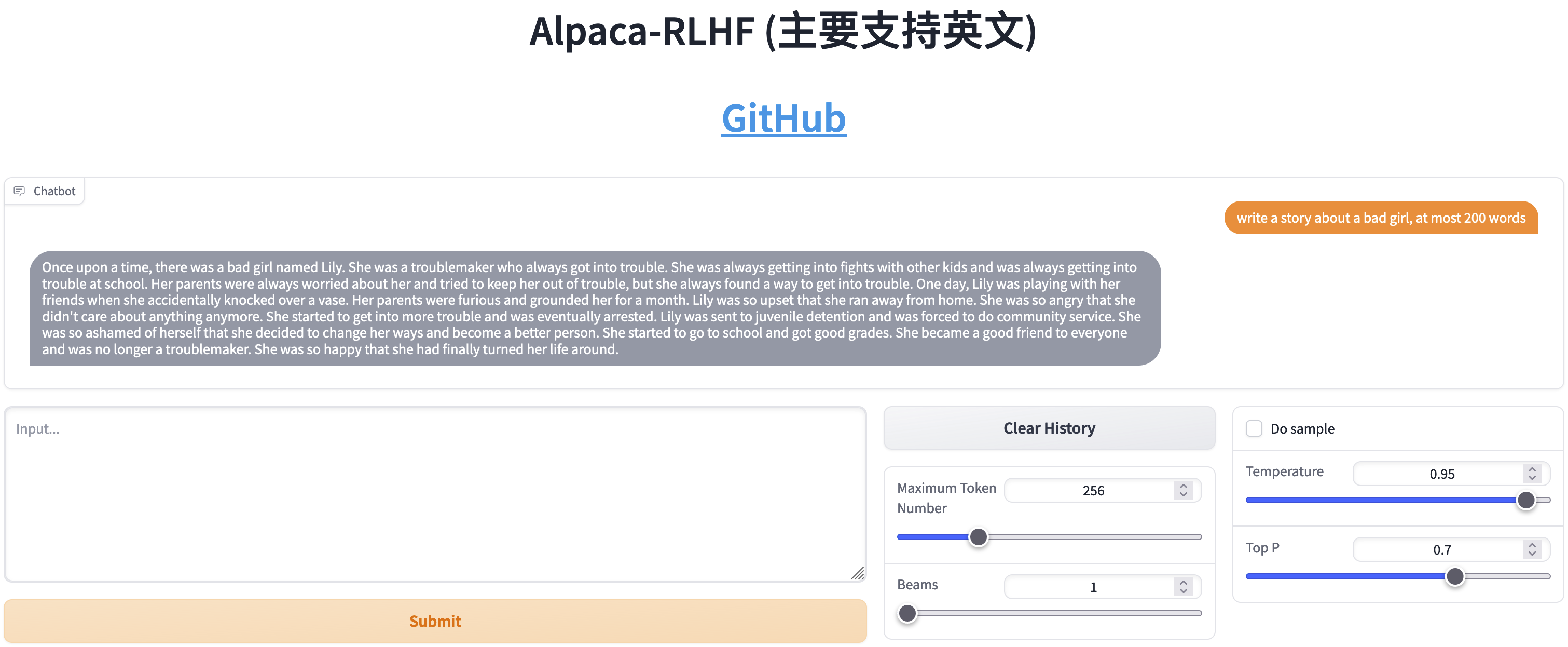
Сравнение SFT и RLHF
Ссылки
Статьи
- 如何正确复现 Проинструктировать GPT/RLHF?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
Источники
Инструменты
Наборы данных
- Стэнфордский набор данных о человеческих предпочтениях (SHP)
- HH-RLHF
- хх-рлф
- Обучение полезного и безвредного помощника с подкреплением обучения на основе обратной связи от человека [документ]
- Дахоас/статика-хх
- Дахоас/rm-static
- ГПТ-4-ЛЛМ
- Открытый помощник
Связанные репозитории
- моя-альпака
- многооборотная альпака