icl selective annotation
1.0.0
Код на бумаге. Выборочная аннотация делает языковые модели более эффективными.
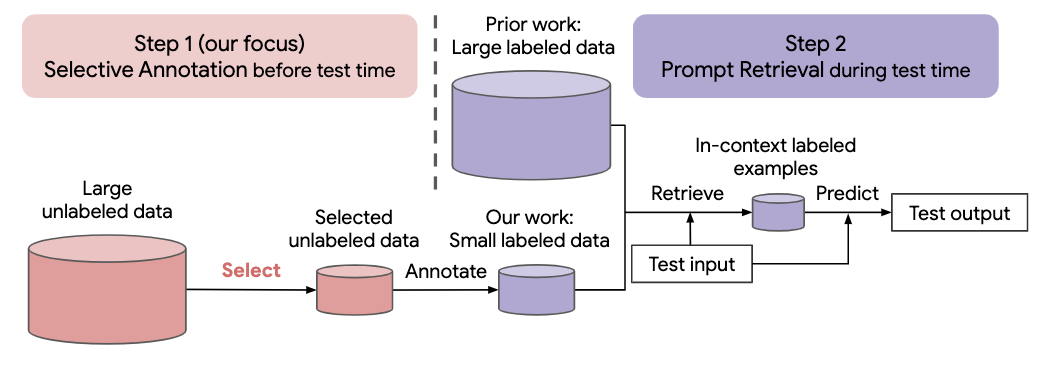
Многие современные подходы к задачам естественного языка основаны на замечательных возможностях больших языковых моделей. Большие языковые модели могут выполнять контекстное обучение, при котором они изучают новую задачу на основе нескольких демонстраций задач без каких-либо обновлений параметров. В этой работе исследуются последствия контекстного обучения для создания наборов данных для новых задач на естественном языке. Отталкиваясь от последних методов контекстного обучения, мы формулируем эффективную двухэтапную структуру аннотаций: выборочная аннотация , которая заранее выбирает пул примеров для аннотирования из немаркированных данных, за которым следует быстрый поиск, который извлекает примеры задач из аннотированного пула в время испытания. Основываясь на этой структуре, мы предлагаем неконтролируемый метод выборочной аннотации на основе графов, voice-k , для выбора разнообразных репрезентативных примеров для аннотирования. Обширные эксперименты с 10 наборами данных (охватывающими классификацию, здравый смысл, диалог и генерацию текста/кода) демонстрируют, что наш метод выборочного аннотирования значительно повышает производительность задачи. В среднем, voice-k достигает относительного выигрыша 12,9%/11,4% при бюджете аннотаций 18/100 по сравнению со случайным выбором примеров для аннотирования. По сравнению с современными подходами контролируемой точной настройки он обеспечивает аналогичную производительность при в 10–100 раз меньших затрат на аннотации для 10 задач. Далее мы анализируем эффективность нашей структуры в различных сценариях: языковые модели разных размеров, альтернативные методы выборочного аннотирования и случаи, когда происходит сдвиг предметной области тестовых данных. Мы надеемся, что наши исследования послужат основой для аннотаций данных, поскольку большие языковые модели все чаще применяются для решения новых задач.
Запустите следующую команду, чтобы клонировать этот репозиторий
git clone https://github.com/HKUNLP/icl-selective-annotation
Чтобы установить среду, запустите этот код в оболочке:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
Это создаст среду selective_annotation, которую мы использовали.
Активируйте среду, запустив
conda activate selective_annotation
GPT-J в качестве модели контекстного обучения, DBpedia в качестве задачи и voice-k в качестве метода выборочного аннотирования (1 графический процессор, 40 ГБ памяти)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
Если вы считаете нашу работу полезной, пожалуйста, цитируйте нас
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


