Phi2 mini Chinese
1.0.0
Этот проект представляет собой экспериментальный проект с открытым исходным кодом и весами моделей, а также меньшим количеством данных для предварительного обучения. Если вам нужна лучшая маленькая китайская модель, вы можете обратиться к проекту ChatLM-mini-Chinese.
Осторожность
Этот проект является экспериментальным и в него в любое время могут быть внесены серьезные изменения, включая данные обучения, структуру модели, структуру файловых каталогов и т. д. Первая версия модели, проверьте tag v1.0
Например, добавление точек в конце предложений, преобразование традиционного китайского языка в упрощенный китайский, удаление повторяющихся знаков препинания (например, в некоторых диалоговых материалах много "。。。。。" ), стандартизация NFKC Unicode (в основном проблема полно- преобразование ширины в полуширину и данные веб-страницы u3000 xa0) и т. д.
Подробную информацию о процессе очистки данных см. в проекте ChatLM-mini-Chinese.
В этом проекте используется токенизатор BPE byte level . Для сегментаторов слов предусмотрено два типа обучающих кодов: char level и byte level .
После обучения токенизатор не забывает проверить, есть ли в словаре общие специальные символы, такие как t , n и т. д. Вы можете попробовать encode и decode текст, содержащий специальные символы, чтобы посмотреть, можно ли его восстановить. Если эти специальные символы не включены, добавьте их с помощью функции add_tokens . Используйте len(tokenizer) , чтобы получить размер словаря. tokenizer.vocab_size не учитывает символы, добавленные с помощью функции add_tokens .
Обучение токенизатора потребляет много памяти:
Для обучения 100 миллионов символов byte level требуется как минимум 32G памяти (на самом деле 32G недостаточно, и своп будет срабатывать часто. Обучение 13600k занимает около часа).
Обучение char level для 650 миллионов символов (именно такое количество данных в китайской Википедии) требует как минимум 32 ГБ памяти. Поскольку обмен запускается несколько раз, фактическое использование намного превышает 32 ГБ. Обучение 13600K занимает около половины времени. час.
Поэтому, когда набор данных большой (уровень ГБ), рекомендуется выполнять выборку из набора данных при обучении tokenizer .
Используйте большой объем текста для неконтролируемого предварительного обучения, в основном используя набор данных BELLE из bell open source .
Формат набора данных: одно предложение для одного образца. Если он слишком длинный, его можно усечь и разделить на несколько образцов.
Во время процесса предварительного обучения CLM входные и выходные данные модели одинаковы, и при расчете потерь перекрестной энтропии их необходимо сдвинуть на один бит ( shift ).
При обработке корпуса энциклопедии рекомендуется в конце каждой записи добавлять пометку '[EOS]' . Другая обработка корпуса аналогична. Конец doc (который может быть концом статьи или концом абзаца) должен быть помечен знаком '[EOS]' . Стартовую отметку '[BOS]' можно добавлять или нет.
В основном используйте набор данных bell open source . Спасибо, босс БЕЛЬ.
Формат данных для обучения SFT следующий:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" Когда модель вычисляет потерю, она будет игнорировать часть перед знаком "##回答:" ( "##回答:" также будет игнорироваться), начиная с конца "##回答:" .
Не забудьте добавить специальный знак конца предложения EOS , иначе вы не будете знать, когда остановиться при decode модели. Отметку начала предложения BOS можно заполнить или оставить пустой.
Используйте более простой и экономящий память метод оптимизации предпочтений DPO.
Точная настройка модели SFT в соответствии с личными предпочтениями. В наборе данных должно быть три столбца: prompt , chosen и rejected . Столбец rejected содержит некоторые данные из основной модели на этапе sft (например, sft обучает 4 epoch и принимает a). Модель контрольной точки epoch 0,5) Генерировать, если сходство между сгенерированным rejected и chosen выше 0,9, то эти данные не потребуются.
В процессе DPO участвуют две модели: одна — модель для обучения, а другая — эталонная модель. При загрузке это фактически одна и та же модель, но эталонная модель не участвует в обновлении параметров.
huggingface веса модели: Phi2-Chinese-0.2B.
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
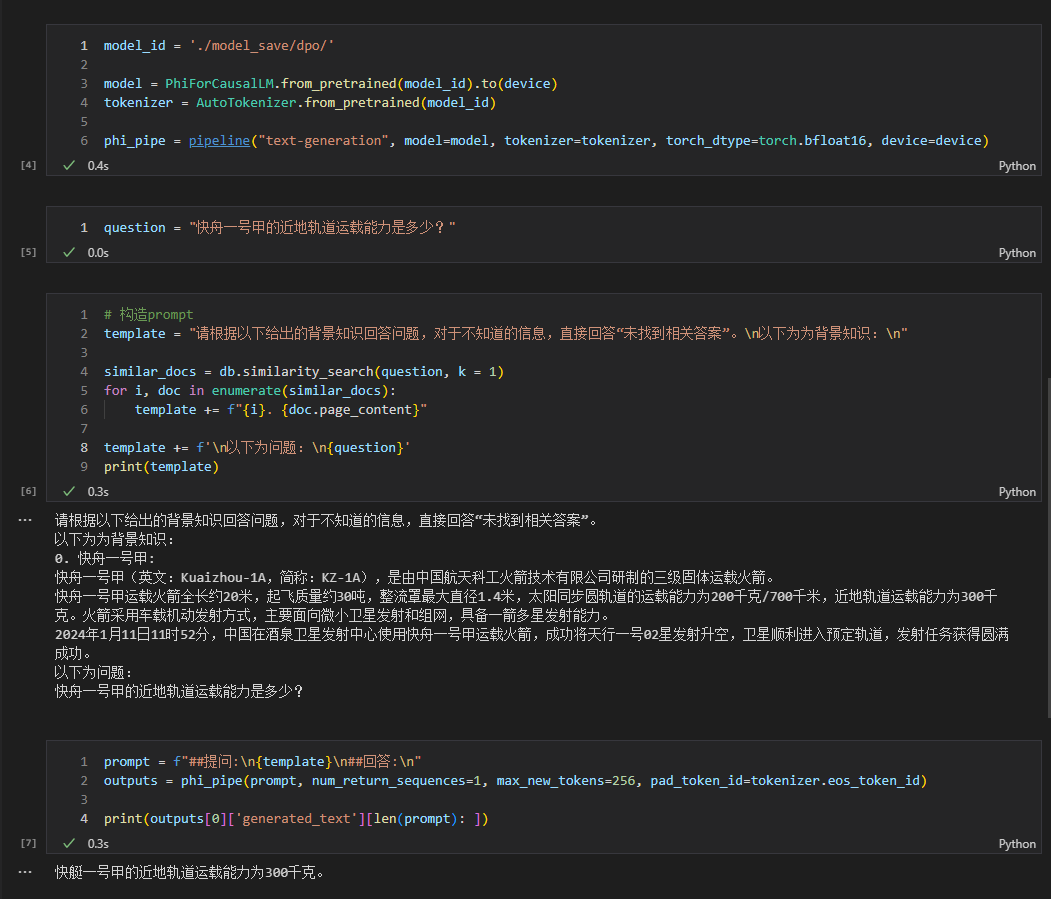
- 另外,如果感冒了,建议及时就医。 См. конкретный код в rag_with_langchain.ipynb .
Если вы считаете, что этот проект полезен для вас, процитируйте его.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
Этот проект не несет рисков и ответственности, связанных с безопасностью данных и рисками общественного мнения, вызванными моделями и кодами с открытым исходным кодом, а также рисками и ответственностью, возникающими в результате введения в заблуждение, злоупотреблений, распространения или ненадлежащего использования любой модели.


