reflexion
1.0.0
В этом репозитории хранятся код, демоверсии и файлы журналов для reflexion : «Языковые агенты с вербальным подкреплением обучения» Ноа Шинна, Федерико Кассано, Эдварда Бермана, Ашвина Гопината, Картика Нарасимхана, Шунью Яо.
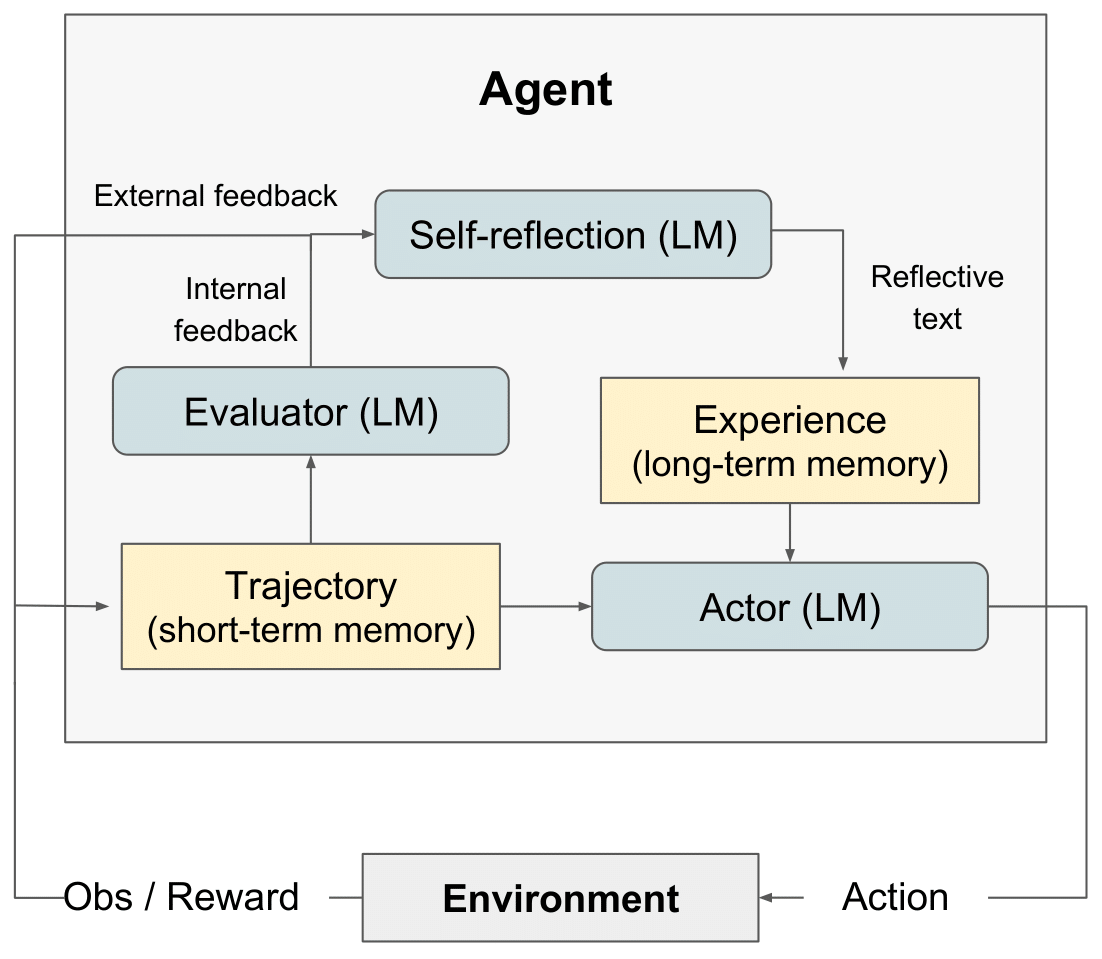 рефлексная RL-диаграмма" style="max-width: 100%;">
рефлексная RL-диаграмма" style="max-width: 100%;">
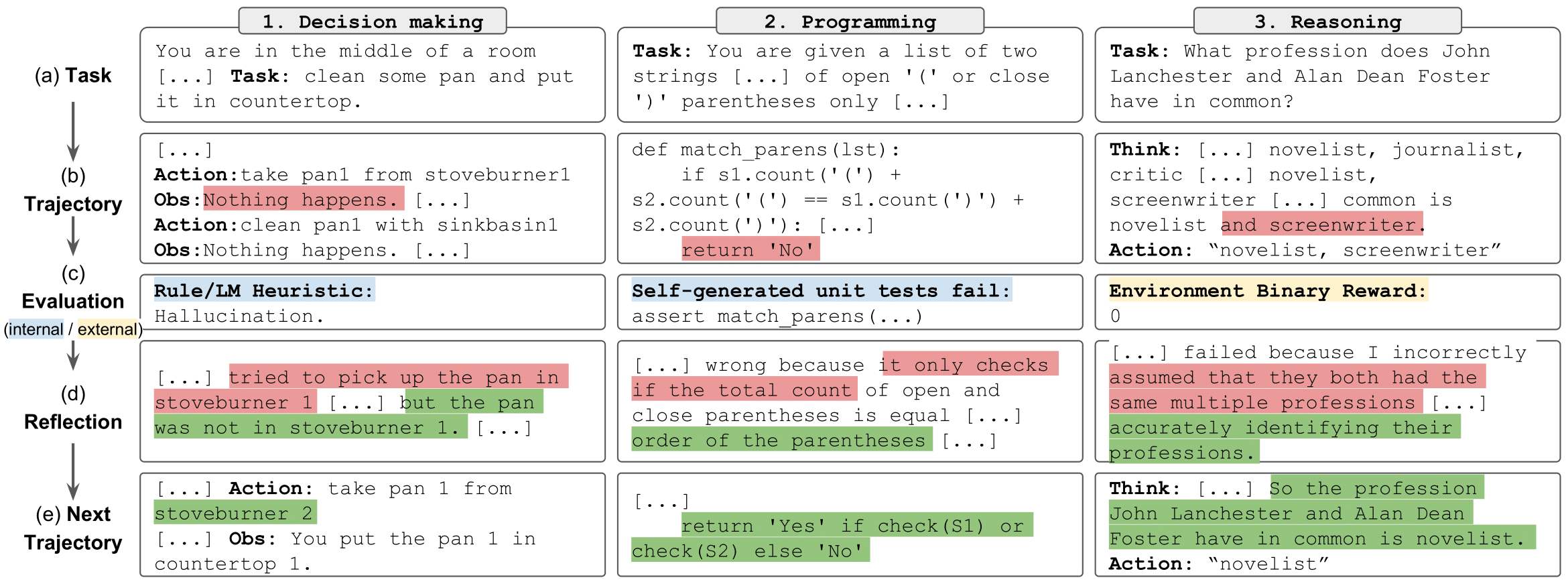 задачи на рефлексию" style="max-width: 100%;">
задачи на рефлексию" style="max-width: 100%;">
Мы выпустили LeetcodeHardGym здесь.
Мы предоставили набор блокнотов, чтобы можно было легко запускать, исследовать и взаимодействовать с результатами логических экспериментов. Каждый эксперимент состоит из случайной выборки из 100 вопросов из набора данных отвлекающих факторов HotPotQA. Каждый вопрос в выборке задается агентом с определенным типом и стратегией reflexion .
Чтобы начать:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY для вашего ключа API OpenAI: export OPENAI_API_KEY= < your key > Тип агента определяется выбранным вами блокнотом. Доступные типы агентов включают в себя:
ReAct - Агент ReAct
CoT_context — агенту CoT предоставлен вспомогательный контекст вопроса.
CoT_no_context — агенту CoT не предоставлен вспомогательный контекст по вопросу.
Записная книжка для каждого типа агента находится в каталоге ./hotpot_runs/notebooks .
Каждый блокнот позволяет указать стратегию reflexion , которую будут использовать агенты. Доступные стратегии reflexion , определенные в Enum , включают:
reflexion Strategy.NONE — агенту не предоставляется никакой информации о его последней попытке.
reflexion Strategy.LAST_ATTEMPT — агенту предоставляется след его рассуждений с последней попытки ответа на вопрос в качестве контекста.
reflexion Strategy. reflexion . В качестве контекста агенту предоставляется саморефлексия последней попытки.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion — агенту в качестве контекста предоставляется как след его рассуждений, так и саморефлексия при последней попытке.
Клонируйте этот репозиторий и перейдите в каталог AlfWorld.
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs Укажите параметры запуска в ./run_ reflexion .sh . num_trials : количество шагов итеративного обучения num_envs : количество пар задача-среда на пробное испытание run_name : имя для этого запуска use_memory : использовать постоянную память для хранения саморефлексий (отключите для запуска базового запуска) is_resume : использовать каталог журналирования для возобновления предыдущий запуск resume_dir : каталог журнала, из которого можно возобновить предыдущий запуск. start_trial_num : если возобновить запуск, то пробный номер, с которого начать
Запустить пробную версию
./run_ reflexion .sh Журналы будут отправлены в ./root/<run_name> .
Из-за характера этих экспериментов отдельным разработчикам может оказаться невозможным повторить результаты, поскольку GPT-4 имеет ограниченный доступ и значительную плату за API. Все прогоны из статьи и дополнительные результаты записываются в ./alfworld_runs/root для принятия решений, ./hotpotqa_runs/root для рассуждений и ./programming_runs/root для программирования.
Проверьте код исходного кода здесь
Прочитайте сообщение в блоге здесь
Посмотрите интересную реализацию прогнозирования типов здесь: OpenTau
По всем вопросам обращайтесь на [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

