Dropout NeuralNetworks
1.0.0
В этом исследовательском проекте я сосредоточусь на влиянии изменения показателей отсева на набор данных MNIST. Моя цель — воспроизвести рисунок ниже с данными, использованными в исследовательской работе. Цель этого проекта — узнать, как была создана фигура машинного обучения. В частности, изучение влияния на ошибку классификации при изменении/не изменении вероятности отсева.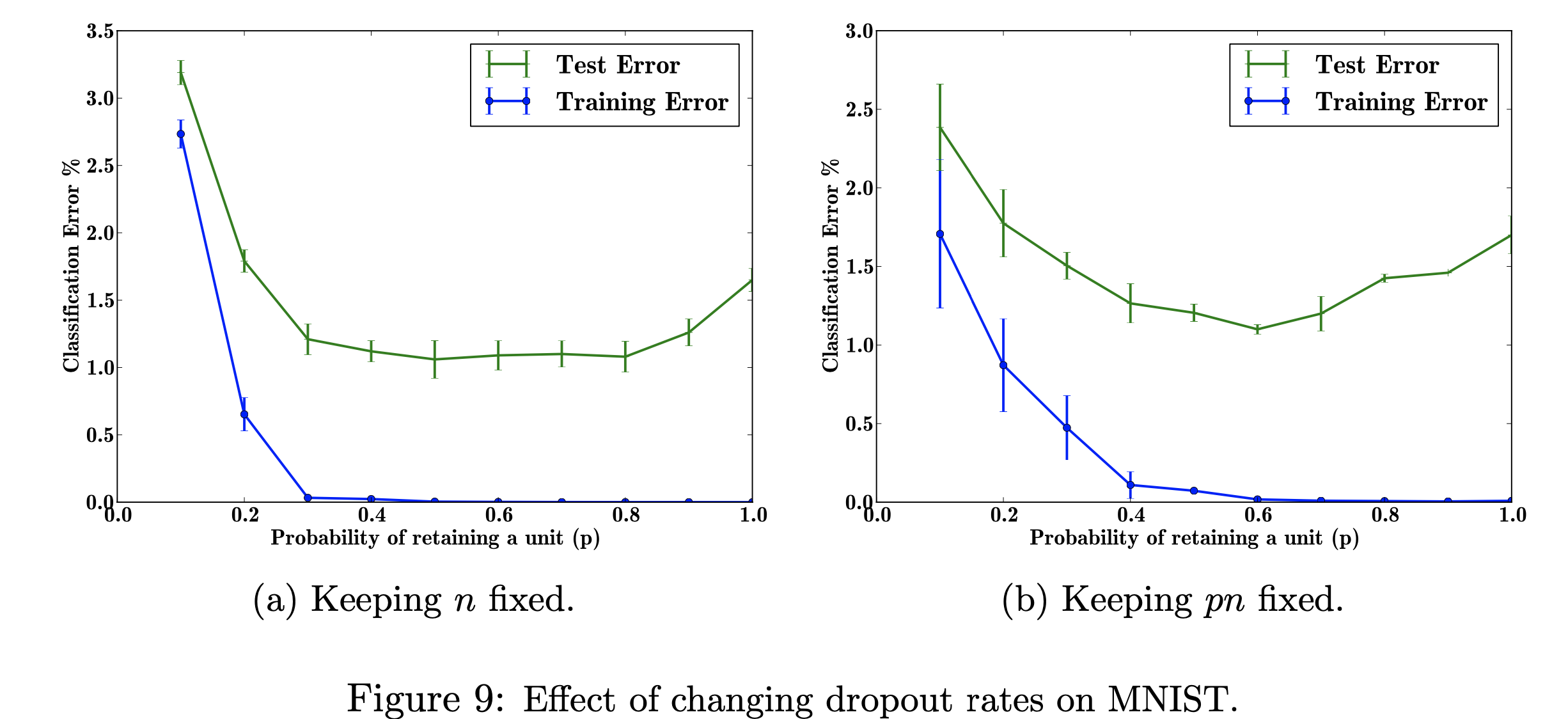 Ссылка на рисунок взята из: Шривастава Н., Хинтон Г., Крижевский А., Крижевский И., Салахутдинов Р., Dropout: простой способ предотвратить переобучение нейронных сетей, рисунок 9.
Ссылка на рисунок взята из: Шривастава Н., Хинтон Г., Крижевский А., Крижевский И., Салахутдинов Р., Dropout: простой способ предотвратить переобучение нейронных сетей, рисунок 9.
Я использовал TensorFlow для запуска отсева в наборе данных MNIST и Matplotlib, чтобы помочь воссоздать рисунок в статье. Я также использовал встроенную библиотеку Decimal для расчета различных значений p от 0,0 до 1,0. Импортирована библиотека "csv" для добавления ранее проведённых данных в CSV-файл, чтобы сэкономить время на вычислении уже вычисленных значений p. Numpy был импортирован, чтобы график имел одинаковый размер шага по осям x и y. Наконец, я импортировал «os», чтобы избавиться от ошибки, возникающей из-за использования процессора, а не графического процессора.
Изучение влияния различных значений настраиваемого гиперпараметра «p» (вероятность сохранения устройства в сети) и количества скрытых слоев «n», которые влияют на частоту ошибок. Когда произведение p и n фиксировано, мы видим, что величина ошибки для малых значений p уменьшилась (рис. 9а) по сравнению с сохранением постоянного количества скрытых слоев (рис. 9b).
При ограниченных обучающих данных многие сложные взаимосвязи между входными/выходными данными будут результатом шума выборки. Они будут существовать в обучающем наборе, но не в реальных тестовых данных, даже если они взяты из того же распределения. Это осложнение приводит к переобучению, это один из алгоритмов, помогающих предотвратить его возникновение. Входные данные для этого рисунка представляют собой набор данных рукописных цифр, а выходные данные после добавления исключения — это разные значения, которые описывают результат применения метода исключения. В целом, после добавления отсева получается меньше ошибок.
Реальная проблема, к которой это может относиться, — это поиск в Google: кто-то может искать название фильма, но он может искать только изображения, потому что он больше обучается визуальному зрению. Поэтому исключение текстовых частей или кратких пояснений поможет вам сосредоточиться на особенностях изображения. В статье указано, откуда они получают данные (http://yann.lecun.com/exdb/mnist/). Каждое изображение представляет собой представление размером 28x28 цифр. Метки y представляют собой столбцы данных изображения.
Моя цель при воспроизведении этой фигуры — протестировать/обучить данные и вычислить ошибку классификации для каждой вероятности p (вероятность сохранения единицы в сети). Моя цель — добиться увеличения p по мере уменьшения ошибки, чтобы показать, что моя реализация действительна, и я настрою этот гиперпараметр, чтобы получить тот же результат. Я сделаю это, просматривая все данные обучения и тестирования, используя архитектуру 784-2048-2048-2048-10, оставив n фиксированным, а затем изменив pn, чтобы он был фиксированным. Затем я соберу/запишу данные в CSV-файл. Этот CSV-файл будет содержать все необходимые данные для вывода цифр. В этом проекте я узнаю, как процент отсева может улучшить общую ошибку в нейронной сети.
Нажмите, чтобы просмотреть


