Stable Diffusion стала возможной благодаря сотрудничеству с Stability AI и Runway и основывается на нашей предыдущей работе:
Синтез изображений высокого разрешения с использованием моделей скрытой диффузии
Робин Ромбах*, Андреас Блаттманн*, Доминик Лоренц, Патрик Эссер, Бьорн Оммер
CVPR '22 Орал | Гитхаб | arXiv | Страница проекта
 Стабильная диффузия — это скрытая модель диффузии текста в изображение. Благодаря щедрым вычислительным пожертвованиям от Stability AI и поддержке LAION, мы смогли обучить модель скрытой диффузии на изображениях размером 512x512 из подмножества базы данных LAION-5B. Подобно Imagen от Google, эта модель использует замороженный текстовый кодер CLIP ViT-L/14 для настройки модели на текстовые подсказки. Благодаря 860M UNet и текстовому кодировщику 123M модель относительно легкая и работает на графическом процессоре с объемом видеопамяти не менее 10 ГБ. См. этот раздел ниже и карточку модели.
Стабильная диффузия — это скрытая модель диффузии текста в изображение. Благодаря щедрым вычислительным пожертвованиям от Stability AI и поддержке LAION, мы смогли обучить модель скрытой диффузии на изображениях размером 512x512 из подмножества базы данных LAION-5B. Подобно Imagen от Google, эта модель использует замороженный текстовый кодер CLIP ViT-L/14 для настройки модели на текстовые подсказки. Благодаря 860M UNet и текстовому кодировщику 123M модель относительно легкая и работает на графическом процессоре с объемом видеопамяти не менее 10 ГБ. См. этот раздел ниже и карточку модели.
Подходящую среду conda с именем ldm можно создать и активировать с помощью:
conda env create -f environment.yaml
conda activate ldm
Вы также можете обновить существующую среду скрытого распространения, запустив
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 относится к конкретной конфигурации архитектуры модели, которая использует автоэнкодер с коэффициентом понижающей дискретизации 8 с 860M UNet и кодировщиком текста CLIP ViT-L/14 для модели диффузии. Модель была предварительно обучена на изображениях размером 256x256, а затем настроена на изображениях 512x512.
Примечание. Stable Diffusion v1 — это общая модель диффузии текста в изображение, поэтому она отражает предвзятости и (неправильные) представления, присутствующие в ее обучающих данных. Подробности о процедуре и данных обучения, а также о предполагаемом использовании модели можно найти в соответствующей карточке модели.
Гири доступны через организацию CompVis в Hugging Face по лицензии, которая содержит конкретные ограничения на использование для предотвращения неправильного использования и нанесения вреда, как указано в карточке модели, но в остальном остается разрешительной. Хотя коммерческое использование разрешено условиями лицензии, мы не рекомендуем использовать предоставленные веса для услуг или продуктов без дополнительных механизмов и соображений безопасности , поскольку существуют известные ограничения и предвзятости весов, а также исследования по безопасному и этичному использованию весов. общие модели преобразования текста в изображение — это постоянные усилия. Веса являются исследовательскими артефактами, и к ним следует относиться соответственно.
Лицензия CreativeML OpenRAIL M — это лицензия Open RAIL M, адаптированная на основе совместной работы BigScience и RAIL Initiative в области ответственного лицензирования ИИ. См. также статью о лицензии BLOOM Open RAIL, на которой основана наша лицензия.
На данный момент мы предоставляем следующие контрольно-пропускные пункты:
sd-v1-1.ckpt : 237 тысяч шагов при разрешении 256x256 на laion2B-en. 194 тыс. шагов при разрешении 512x512 при высоком разрешении laion (170 млн примеров из LAION-5B с разрешением >= 1024x1024 ).sd-v1-2.ckpt : возобновлено с sd-v1-1.ckpt . 515 тыс. шагов при разрешении 512x512 в laion-aesthetics v2 5+ (подмножество laion2B-en с оценочной оценкой эстетики > 5.0 и дополнительно фильтруется для изображений с исходным размером >= 512x512 и предполагаемой вероятностью водяного знака < 0.5 . Оценка водяного знака взято из метаданных LAION-5B, оценка эстетики оценивается с использованием LAION-Aesthetics Predictor V2).sd-v1-3.ckpt : возобновлено с sd-v1-2.ckpt . 195 тыс. шагов при разрешении 512x512 для «laion-aesthetics v2 5+» и снижение обработки текста на 10 % для улучшения выборки рекомендаций без классификатора.sd-v1-4.ckpt : возобновлено с sd-v1-2.ckpt . 225 тыс. шагов при разрешении 512x512 для «laion-aesthetics v2 5+» и снижение на 10 % условий обработки текста для улучшения выборки рекомендаций без классификатора. Оценки с использованием различных руководящих шкал без классификаторов (1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0, 8,0) и 50 этапов выборки PLMS показывают относительные улучшения контрольных точек: 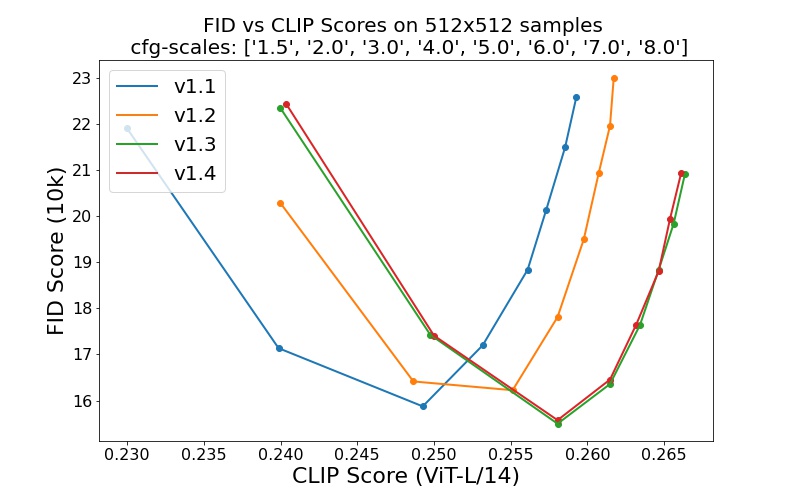


Стабильная диффузия — это модель скрытой диффузии, основанная на (необъединенных) вложениях текста текстового кодера CLIP ViT-L/14. Мы предоставляем эталонный сценарий для семплирования, но существует также интеграция с диффузорами, от которой мы ожидаем более активного развития сообщества.
Мы предоставляем сценарий эталонной выборки, который включает в себя
После получения stable-diffusion-v1-*-original свяжите их
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
и образец с
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
По умолчанию здесь используется направляющая шкала --scale 7.5 , реализация сэмплера PLMS Кэтрин Кроусон, и визуализируются изображения размером 512x512 (на которых он обучался) за 50 шагов. Все поддерживаемые аргументы перечислены ниже (введите python scripts/txt2img.py --help ).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Примечание. Конфигурация вывода для всех версий v1 предназначена для использования только с контрольными точками EMA. По этой причине в конфигурации установлено use_ema=False , иначе код попытается переключиться с весов, отличных от EMA, на веса EMA. Если вы хотите изучить влияние EMA на отсутствие EMA, мы предоставляем «полные» контрольные точки, которые содержат оба типа весов. Для них use_ema=False будет загружать и использовать веса, отличные от EMA.
Простой способ загрузить и попробовать Stable Diffusion — использовать библиотеку диффузоров:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )Используя механизм диффузионного шумоподавления, впервые предложенный SDEdit, модель можно использовать для различных задач, таких как перевод изображения в изображение с текстовым управлением и масштабирование. Подобно сценарию выборки txt2img, мы предоставляем сценарий для модификации изображения с помощью Stable Diffusion.
Ниже описан пример, в котором черновой набросок, сделанный в Pinta, преобразуется в детальную иллюстрацию.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Здесь сила — это значение от 0,0 до 1,0, которое контролирует количество шума, добавляемого к входному изображению. Значения, приближающиеся к 1,0, допускают множество вариантов, но также создают изображения, которые семантически не соответствуют входным данным. См. следующий пример.
Вход

Выходы


Эту процедуру можно, например, использовать для масштабирования образцов базовой модели.
Наша кодовая база для моделей диффузии во многом основана на кодовой базе ADM OpenAI и https://github.com/lucidrains/denoising-diffusion-pytorch. Спасибо за открытый исходный код!
Трансформаторный энкодер реализован на основе x-трансформеров компании lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


