Лучшая студенческая работа ACM MM'18
Проект Multi-Human Parsing группы Learning and Vision (LV) Национального университета Сингапура (NUS) призван расширить границы детального визуального понимания людей в массовых сценах.
Многопользовательский анализ существенно отличается от традиционных четко определенных задач распознавания объектов, таких как обнаружение объектов, которое обеспечивает только грубый прогноз местоположений объектов (ограничивающие рамки); сегментация экземпляров, которая прогнозирует только маску уровня экземпляра без какой-либо подробной информации о частях тела и категориях моды; человеческий анализ, который основан на попиксельном прогнозировании на уровне категорий без дифференциации различных идентификаторов.
В реальном мире взаимодействие нескольких людей более реалистично и привычно. Таким образом, весьма желательны задача, соответствующие наборы данных и базовые методы, позволяющие учитывать как детальную семантическую информацию каждого отдельного человека, так и отношения и взаимодействия всей группы людей.
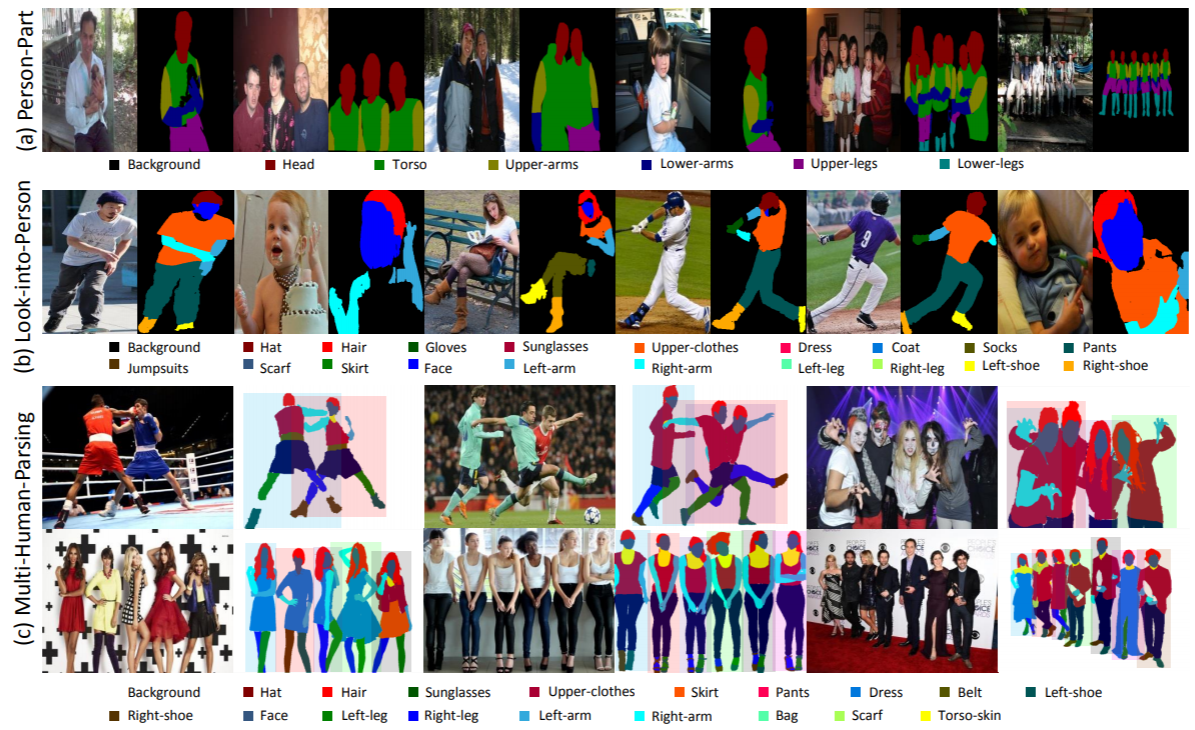
Статистика: Набор данных MHP v1.0 содержит 4980 изображений, на каждом из которых изображено как минимум два человека (в среднем 3). В качестве набора для тестирования мы случайным образом выбираем 980 изображений и соответствующие им аннотации. Остальные образуют обучающий набор из 3000 изображений и проверочный набор из 1000 изображений. Для каждого экземпляра определены и аннотированы 18 семантических категорий, за исключением категории «фон», т.е. «шляпа», «волосы», «солнечные очки», «верхняя одежда», «юбка», «брюки», «платье», « ремень», «левый ботинок», «правый ботинок», «лицо», «левая нога», «правая нога», «левая рука», «правая рука», «сумка», «шарф» и «кожа туловища». Каждый экземпляр имеет полный набор аннотаций всякий раз, когда соответствующая категория появляется в текущем изображении.
Новости WeChat.
Загрузка: набор данных MHP v1.0 доступен на дисках Google и Baidu (пароль: cmtp).
Более подробную информацию можно найти в нашем документе MHP v1.0 (отправленном в IJCV).

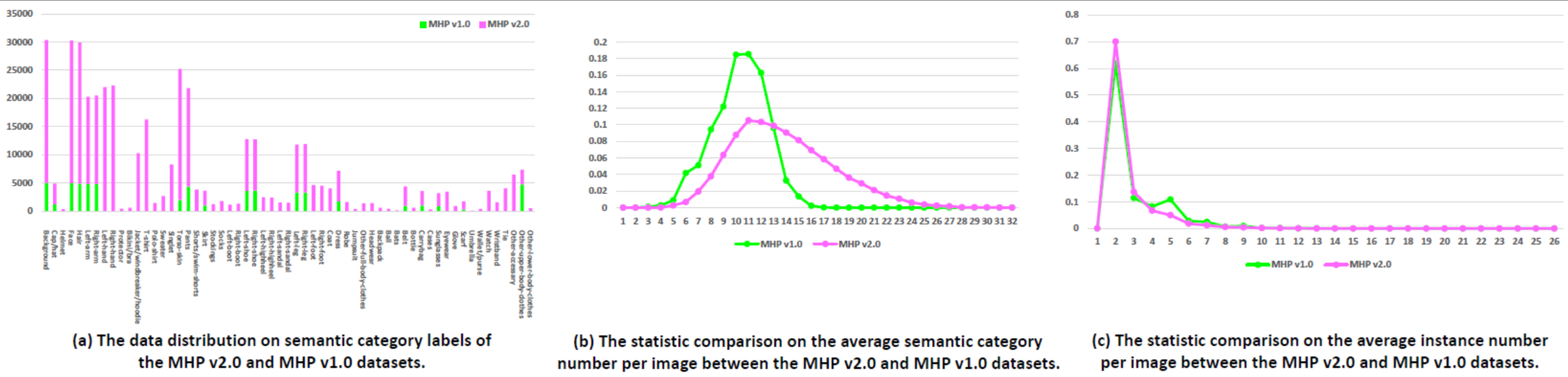

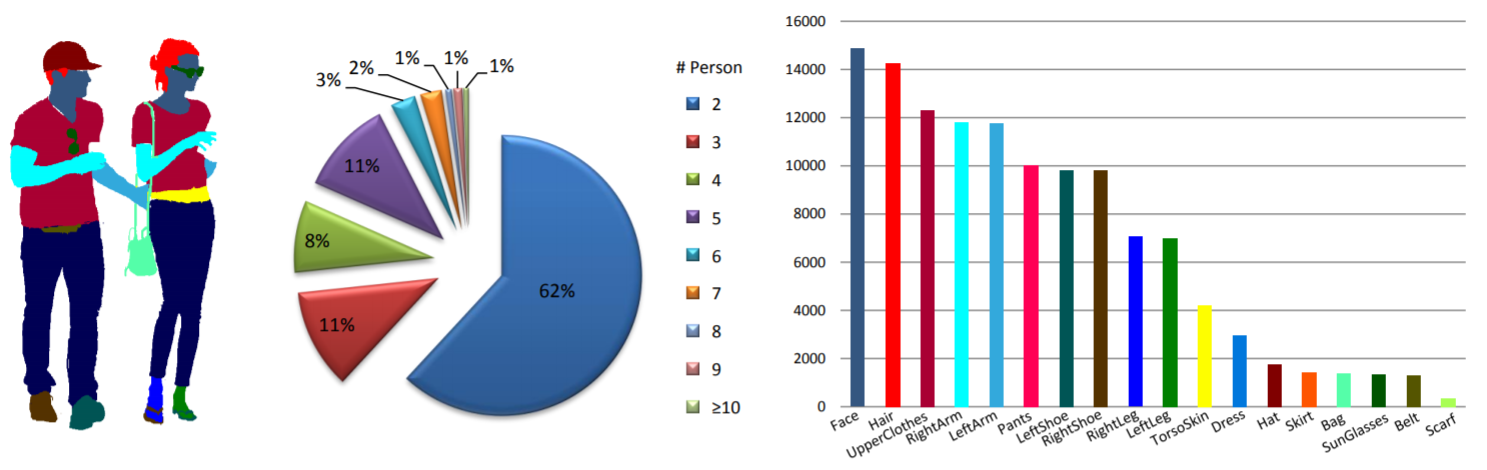
Статистика: Набор данных MHP v2.0 содержит 25 403 изображения, на каждом из которых изображено как минимум два человека (в среднем 3). Мы случайным образом выбираем 5000 изображений и соответствующие им аннотации в качестве набора для тестирования. Остальные образуют обучающий набор из 15 403 изображений и проверочный набор из 5 000 изображений. Для каждого экземпляра определены и аннотированы 58 семантических категорий, за исключением категории «фон», т.е. «кепка/шляпа», «шлем», «лицо», «волосы», «левая рука», «правая рука», «левша», «правша», «защитник», «бикини/бюстгальтер», «куртка/ветровка/толстовка», «футболка», «поло», «свитер», «майка», «кожа туловища», «штаны», «шорты/плавальные шорты», «юбка», «чулки», «носки», «левый ботинок», «правый ботинок», «левый ботинок», «правый ботинок», «левый ботинок». -высокий каблук", "правый-высокий каблук", "левая сандалия", "правая сандалия", "левая нога", "правая нога", "левая нога", "правая нога", "пальто", "одеваться", «халат», «комбинезон», «прочее-полная одежда», «головной убор», «рюкзак», «мяч», «биты», «пояс», «бутылка», «сумка», «футляры», «солнцезащитные очки», «очки», «перчатка», «шарф», «зонт», «кошелек», «часы», «браслет», «галстук», «другой аксессуар», «другая верхняя часть тела». -одежда" и «другая одежда для нижней части тела». Каждый экземпляр имеет полный набор аннотаций всякий раз, когда соответствующая категория появляется в текущем изображении. Кроме того, 2D-позы человека с 16 плотными ключевыми точками («правое плечо», «правое локоть», «правое запястье», «левое плечо», «левое локоть», «левое запястье», «правое запястье»). бедро», «правое колено», «правая лодыжка», «левое бедро», «левое колено», «левая лодыжка», «голова», «шея», «позвоночник» и «таз». Каждый ключевой момент имеет флаг, указывающий, является ли он видимым-0/закрытым-1/вне изображения-2), а также предоставляются ограничивающие рамки головы и экземпляра для облегчения исследования оценки позы нескольких людей.
Загрузка: набор данных MHP v2.0 доступен на дисках Google и Baidu (пароль: uxrb).
Более подробную информацию можно найти в нашей статье MHP v2.0 (Лучшая студенческая статья ACM MM'18).
Многопользовательский анализ: мы используем две человеко-ориентированные метрики для оценки многопользовательского анализа, о которых первоначально сообщается в нашем документе MHP v1.0. Двумя метриками являются средняя точность на основе детали (AP p ) (%) и процент правильно проанализированных семантических частей (PCP) (%). Оценочный код можно найти в папке «Оценка» в нашем репозитории «Multi-Human-Parsing_MHP».
Оценка позы нескольких людей: В соответствии с MPII мы используем показатель оценки mAP (%).
Мы организовали семинар CVPR 2018 по визуальному пониманию людей в сцене толпы (VUHCS 2018). Этот семинар проводится при сотрудничестве НУК, КМУ и СЮГУ. Основываясь на VUHCS 2017, мы еще больше усилили этот семинар, дополнив его 5 конкурсными треками: анализ одного человека, анализ нескольких человек, оценка позы одного человека, оценка позы нескольких людей и точный анализ. зернистый многопользовательский анализ.
Представление результатов и таблица лидеров.
Новости WeChat.
Пожалуйста, проконсультируйтесь и рассмотрите возможность цитирования следующих документов:
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


