Image to text chrome extension
1.0.0
Расширение Chrome, которое может распознавать любой тип текста в вашем браузере из любого видео или изображения, используя концепцию оптического распознавания символов. OCR — это краткая форма оптического распознавания символов или другого текста для поиска слов на изображениях. Ранее Google выпустила движок под названием Tesseract OCR. Это означает, что Google предоставляет вам программу, в которой уже обучено распознавание текста, поэтому мне не придется самому делать сложные вещи, такие как обучение данных в OCR. Но для большей точности нам необходимо предварительно обработать изображение перед передачей его через Tesseract, поскольку в Tesseract есть некоторые заранее определенные условия, которые необходимо соблюдать для получения точного результата. Таким образом, для обеспечения функциональности нашего расширения оно сначала делает снимок экрана с открытой в данный момент вкладки, затем обрезает нужную часть с помощью холста и настраивает ее с помощью пороговой бинаризации, чтобы оно могло удовлетворить требования OCR для получения более точных результатов. Затем отправьте его в pytesseract (версия Tesseract для Python), чтобы он мог его преобразовать. В конце получите текст и загрузите его в формате .txt. Таким образом, пользователь может открыть его в блокноте или любом другом текстовом редакторе и при необходимости сравнить и изменить текст.
Я очень часто встречаю фрагменты кода на YouTube или любом другом веб-сайте, и теперь я очень ценю усилия, которые создатели учебных пособий вкладывают в свои видео, каждый раз, когда я сталкиваюсь с фрагментом кода, который не содержит ссылки для его загрузки или копирования. Итак, чтобы получить коды из этих видео, я создал этот проект с помощью плагина tesseract, чтобы я мог извлекать текст из этих видео или изображений.
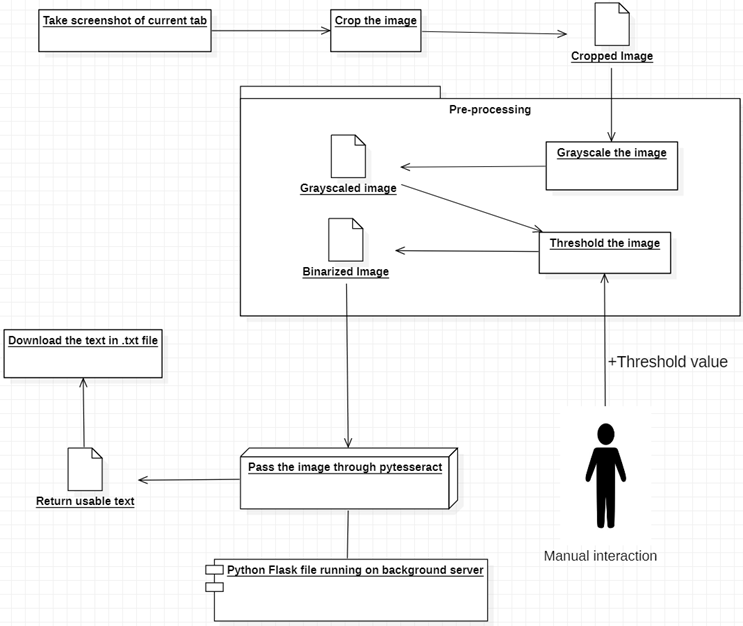
Реализацию и демонстрацию модулей можно найти в п.п.
pip install pytesseract
npm i flask
Мини-файл jQuery прилагается к файлам. Если вы хотите изменить его или использовать подход cdn, вы можете его изменить.


