eye in the sky
1.0.0
Классификация спутниковых изображений, InterIIT Techmeet 2018, IIT Bombay.
Команда: Манидип Колла, Аникет Мэндл, Апурва Кумар
Этот репозиторий содержит реализацию двух алгоритмов, а именно U-Net: сверточные сети для сегментации биомедицинских изображений и сеть анализа пирамидальных сцен, модифицированных для задачи классификации спутниковых изображений.
main_unet.py : код Python для обучения алгоритма с архитектурой U-Net, включая кодирование основных данных.unet.py : содержит нашу реализацию слоев U-Net.test_unet.py : код для тестирования, расчета точности, расчета матриц путаницы для обучения и проверки и сохранения прогнозов модели U-Net для изображений обучения, проверки и тестирования.Inter-IIT-CSRE : содержит все данные обучения, проверки и тестирования рекламы.Comparison_Test.pdf : параллельное сравнение тестовых данных с прогнозами модели U-Net по данным.train_predictions : прогнозы модели U-Net для обучающих и проверочных изображений.plots : графики точности и потерь для обучения и проверки архитектуры U-Net.Test_images , Test_outputs : Содержит тестовые изображения и их прогнозы по модели U-Net.class_masks , compare_pred_to_gt , images_for_doc : Содержит несколько изображений для документации.PSPNet : Содержит обучающие файлы для реализации алгоритма PSPNet для классификации спутниковых изображений. Клонируйте репозиторий, измените текущий рабочий каталог на клонированный. Создайте папки с именами train_predictions и test_outputs для сохранения прогнозируемых результатов модели на обучающих и тестовых изображениях (сейчас это не требуется, поскольку репозиторий уже содержит эти папки)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
Для обучения модели U-Net и экономии весов выполните следующую команду:
$ python3 main_unet.py
Протестировать модель U-Net, вычислить точности, вычислить матрицы путаницы для обучения и проверки и сохранить прогнозы модели на изображениях обучения, проверки и тестирования.
$ python3 test_unet.py
При запуске нашего кода вы можете получить сообщение об ошибке: xrange is not defined . Эта ошибка возникает не из-за ошибок в нашем коде, а из-за устаревшего пакета Python с именем libtiff (некоторые части исходного кода пакета находятся в python2, а некоторые — в python3), который мы использовали для чтения набора данных, в котором изображения находятся в формате .tif. Мы не смогли использовать другие библиотеки, такие как openCV или PIL, для чтения изображений, поскольку они не поддерживают должным образом чтение 4-канальных изображений .tif.
Эту ошибку можно устранить, отредактировав исходный код библиотеки libtiff .
Перейдите к файлу в исходном коде библиотеки, откуда возникает ошибка (имя файла будет отображаться в терминале, когда он показывает ошибку) и замените все функции xrange() (python2) в файле на range() (питон3).
Мы предоставляем здесь несколько достаточно хороших предварительно подготовленных весов, чтобы пользователям не приходилось тренироваться с нуля.
| Описание | Задача | Набор данных | Модель |
|---|---|---|---|
| Архитектура UNet | Классификация спутниковых изображений | Набор данных IITB (см. папку Inter-IIT-CSRE ) | скачать (.h5) |
Чтобы использовать предварительно обученные веса, измените имя файла .h5 (файл весов), упомянутого в test_unet.py чтобы оно соответствовало имени загруженного вами файла весов, где это необходимо.
Давайте теперь обсудим
1. О чем этот проект,
2. Архитектуры, которые мы использовали и с которыми экспериментировали, и
3. Некоторые новые стратегии обучения, которые мы использовали в проекте
Дистанционное зондирование — это наука о получении информации об объектах или территориях на расстоянии, обычно с самолетов или спутников.
Мы осознали проблему классификации спутниковых изображений как проблему семантической сегментации и создали алгоритмы семантической сегментации в рамках глубокого обучения для ее решения.
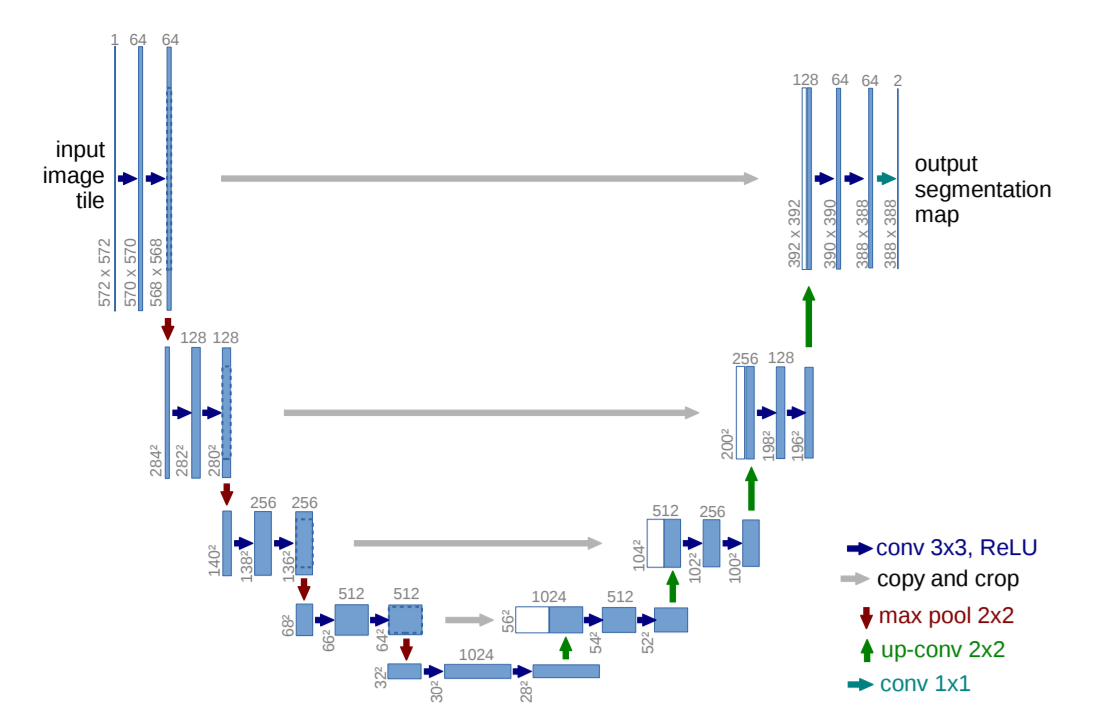
U-Net: сверточные сети для сегментации биомедицинских изображений
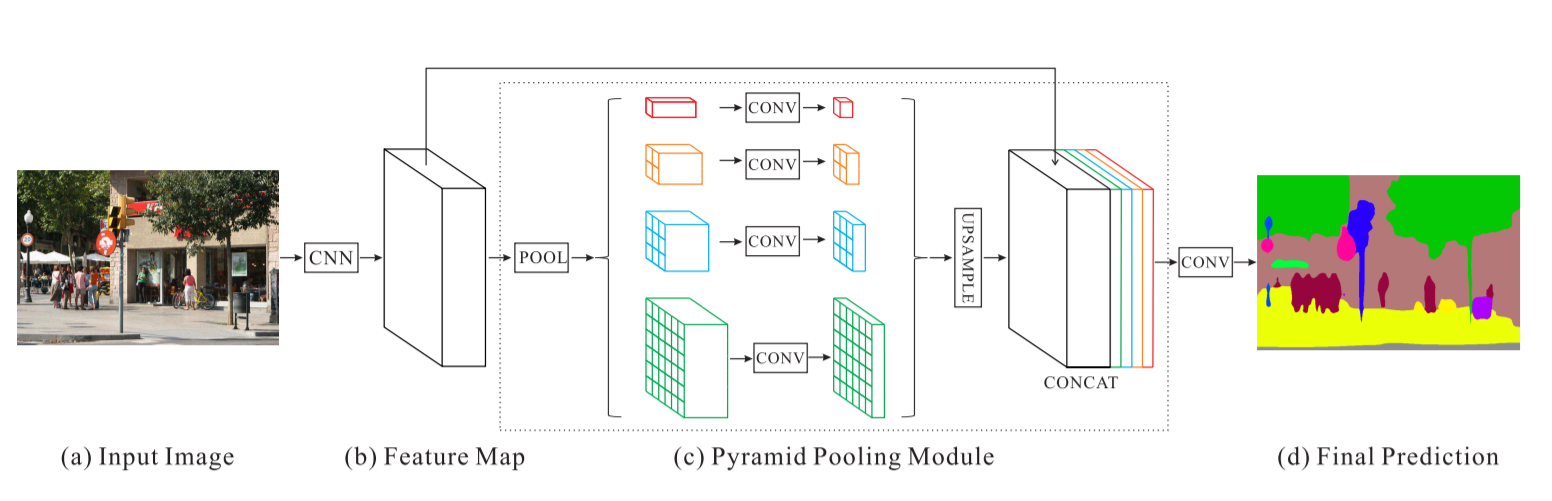
Сеть анализа сцен пирамид — PSPNet
Предоставленные основные сведения представляют собой 3-канальные изображения RGB. В текущем наборе данных в основных истинах содержится только 9 уникальных значений RGB, поскольку существует 9 классов, которые необходимо классифицировать. Эти 9 различных значений RGB подвергаются горячему кодированию для генерации 9-канальной базовой истины, где каждый канал представляет определенный класс.
Ниже приведена схема кодирования
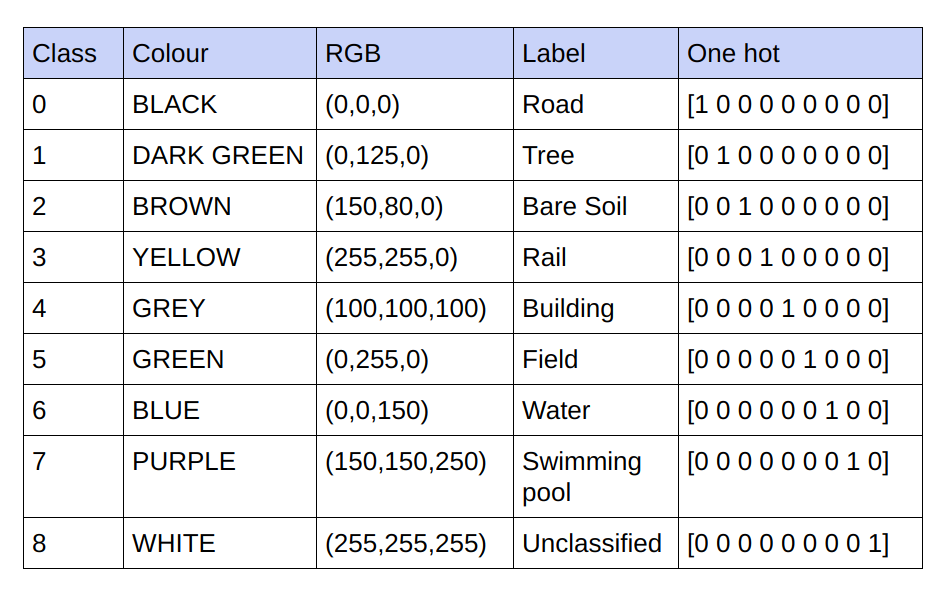
Реализация каждого канала в закодированной основной истине как класса

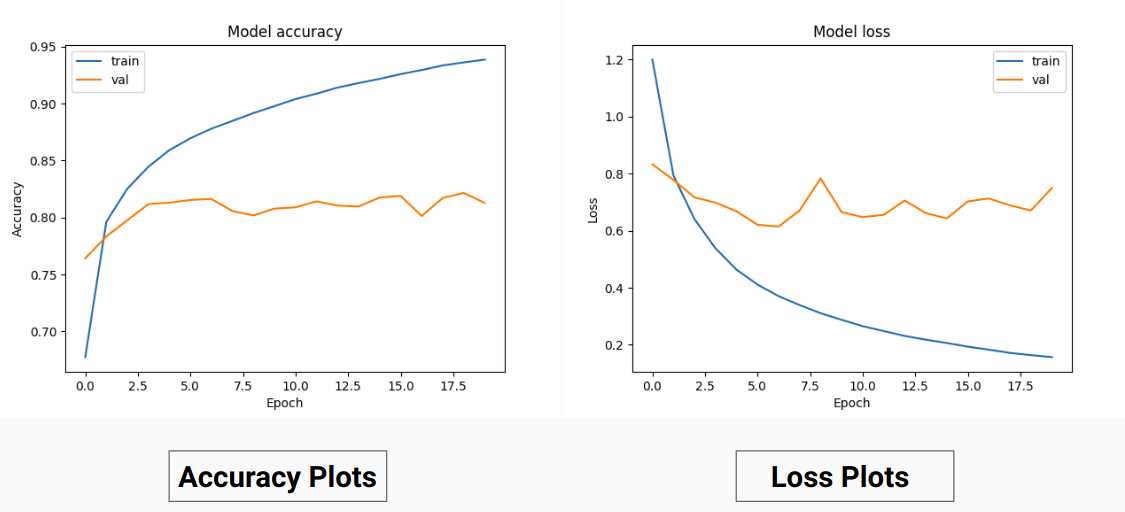
Поэтому вместо обучения значениям RGB основной истины мы преобразовали их в единые значения разных классов. Этот подход дал нам точность проверки 85% и точность обучения 92% по сравнению с точностью проверки 71% и точностью обучения 65%, когда мы использовали для обучения основные истинностные значения RGB.
Это может быть связано с уменьшением дисперсии и среднего значения основных данных обучения, поскольку это действует как эффективный метод нормализации. Более высокая производительность этого метода обучения также объясняется тем, что модель выдает выходные данные с 9 картами признаков, каждая из которых указывает на класс, т. е. этот метод обучения действует так, как если бы модель в некоторой степени обучалась на каждом из 9 классов отдельно ( но тут однозначно прогноз на одном канале, который соответствует определенному классу, зависит от других) .
Наши результаты по PSPNet для классификации спутниковых изображений:
Точность обучения — 49% Точность проверки — 60%
Причины:
Ю-Нет:
Модифицированная U-Net:
Для обучения и проверки мы использовали 14 изображений «.tif» в папке Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset .
Для обучения мы использовали первые 13 изображений в наборе данных, а для проверки — 14-е изображение .
Каждое спутниковое изображение в папке sat содержит 4 канала, а именно R (диапазон 1), G (диапазон 2), B (диапазон 3) и NIR (диапазон 4).
Исходные изображения в каталоге gt представляют собой изображения RGB и отображают 8 классов: дороги, здания, деревья, трава, голая почва, вода, железные дороги и бассейны.
Причина, по которой мы рассмотрели только одно изображение (14-е изображение) в качестве набора проверки, заключается в том, что это одно из самых маленьких изображений в наборе данных, и мы не хотим оставлять меньше данных для обучения, поскольку набор данных довольно мал. Рассмотренный нами проверочный набор (14-е изображение) не содержит 3 классов (голый грунт, рельсы, опрос по плаванию), которые имеют довольно высокую точность обучения. Точность проверки была бы выше, если бы мы рассматривали изображение со всеми классами в нем (ни одно изображение в наборе данных не содержит всех классов, во всех изображениях отсутствует как минимум один класс).
Полосатая обрезка:
Чтобы получить достаточные обучающие данные из заданных изображений высокой четкости, необходимо обрезать классификатор, который имеет около 31 миллиона параметров нашей реализации U-Net. При обрезке размером 64x64 мы обнаруживаем недостаточное представление отдельных классов, а геометрия и непрерывность объектов теряются, уменьшая поле зрения извилин.
Используя окно обрезки размером 128x128 пикселей с шагом 32, получено 15887 обучающих 414 проверочных изображений.
Размеры изображения:
Перед обрезкой размеры тренировочных изображений преобразуются в кратные шагу для удобства во время пошаговой обрезки.
Для случаев, когда нет. количество обрезков не кратно размерам изображения. Мы изначально пробовали заполнение нулями. Мы поняли, что добавление заполнения добавит нежелательные артефакты в виде черных пикселей в обучающих и тестовых изображениях, что приведет к обучению на ложных данных и границах изображения.
В качестве альтернативы мы правильно изменили размеры изображения, добавив дополнительные пиксели в правой и нижней части изображения. Таким образом, мы добавили разницу от большей левой части изображения к ее правому краю, а также для верхней и нижней части изображения.
Пример обучения 1: Изображение «2.tif» из данных обучения
Пример обучения 2: Изображение «4.tif» из данных обучения
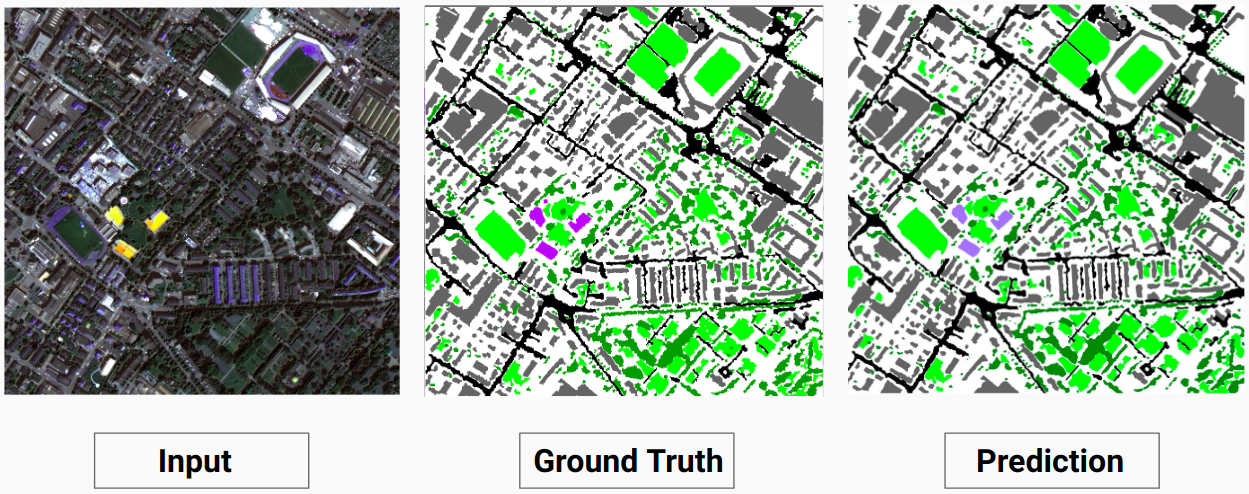
Пример проверки: изображение «14.tif» из набора данных

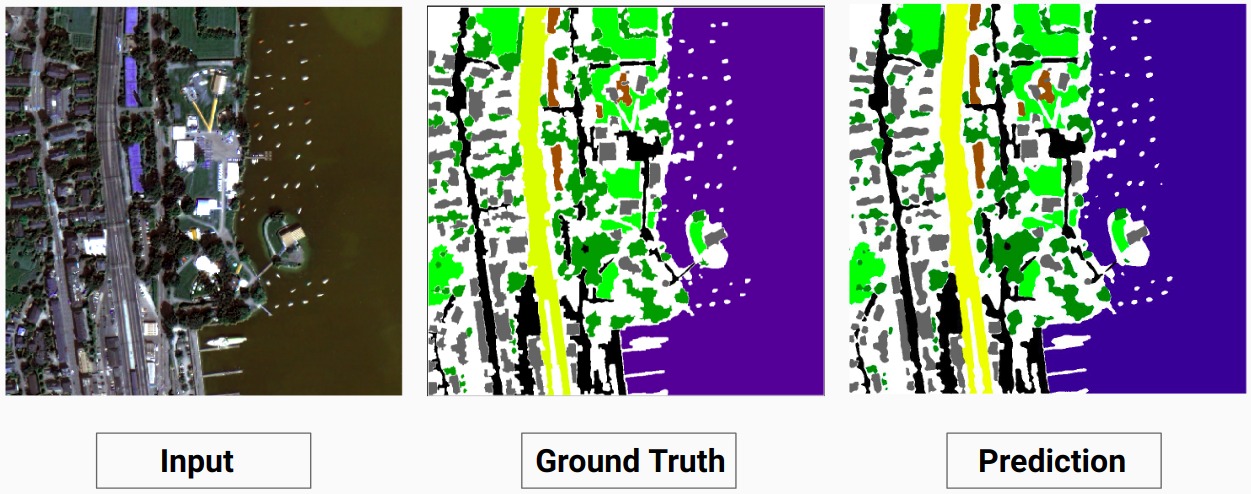
Наша модель способна предсказывать некоторые классы, которые не смог сделать человек-аннотатор. Неидентифицируемые классы на изображениях помечаются человеком-аннотатором как белые пиксели. Наша модель способна правильно предсказать некоторые из этих белых пикселей как некоторый класс, но это привело к снижению общей точности, поскольку белые пиксели рассматриваются моделью как отдельный класс.
Здесь модель способна предсказать белые пиксели как здание, которое является правильным и хорошо видно на входном изображении.
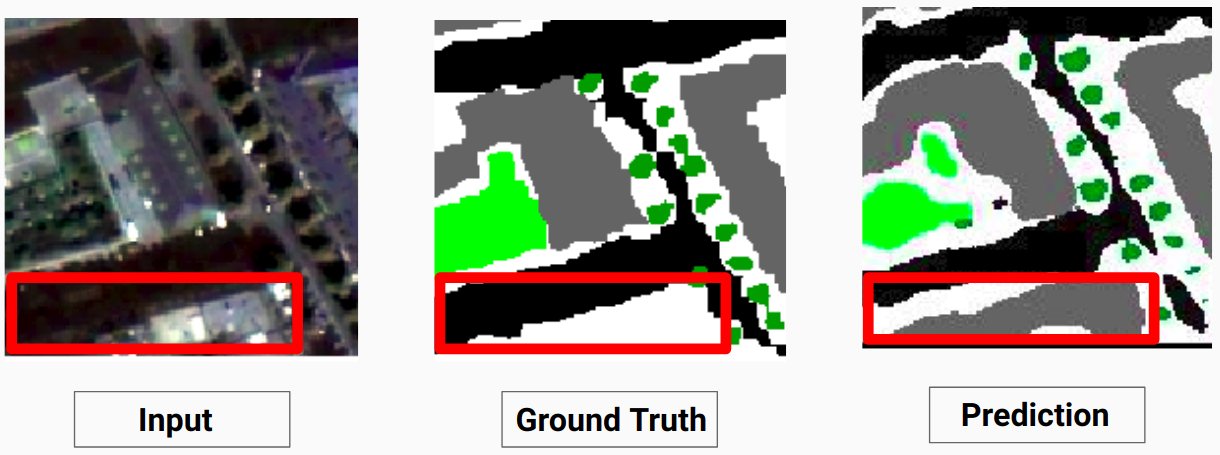
Ознакомьтесь с Comparison_Test.pdf для сравнения тестовых изображений и их прогнозируемых результатов с помощью модели.
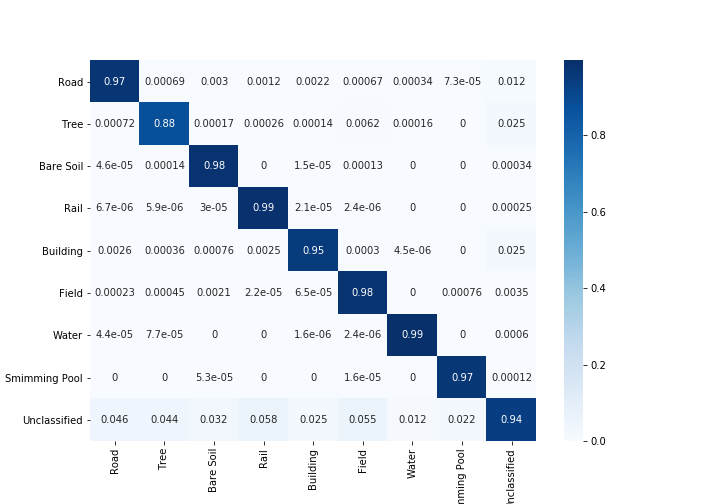
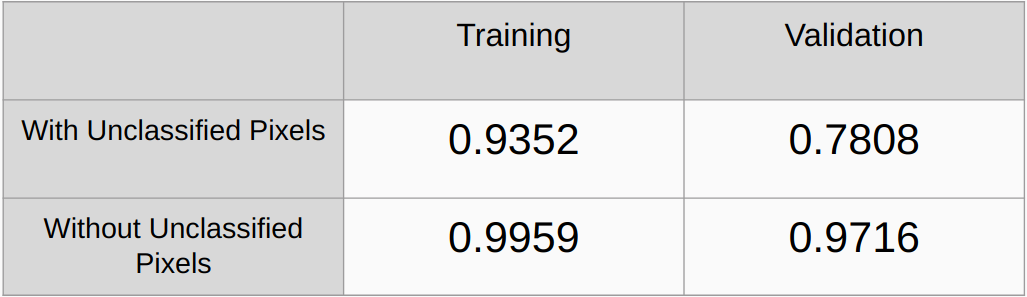
Коэффициенты Каппа с учетом и без учета неклассифицированных пикселей
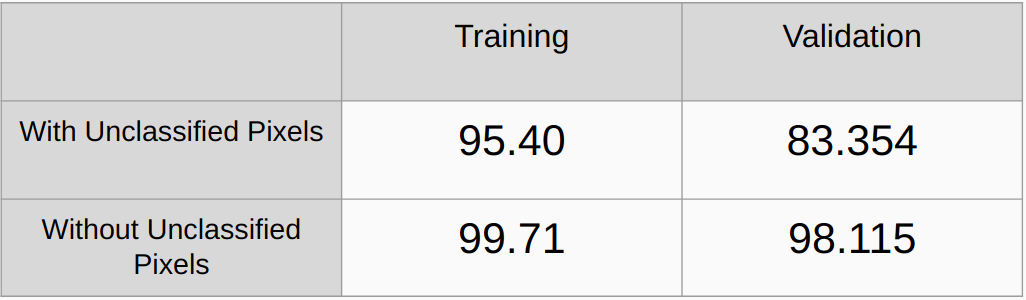
Общая точность с учетом и без учета неклассифицированных пикселей
Необходимо добавить методы регуляризации, такие как регуляризация L2 и отключение, и проверить производительность.
Внедрите алгоритм для автоматического обнаружения всех уникальных значений RGB в основных истинах и быстрого их кодирования вместо поиска значений RGB вручную.
[1] U-Net: сверточные сети для сегментации биомедицинских изображений, Олаф Роннебергер, Филипп Фишер и Томас Брокс.
[2] Сеть анализа сцен пирамид, Хэншуан Чжао, Цзяньпин Ши, Сяоцзюань Ци, Сяоган Ван, Цзя Цзя
[3] Руководство по семантической сегментации с помощью глубокого обучения, 2017 г., Сасанк Чиламкурти.


