linformer pytorch
version
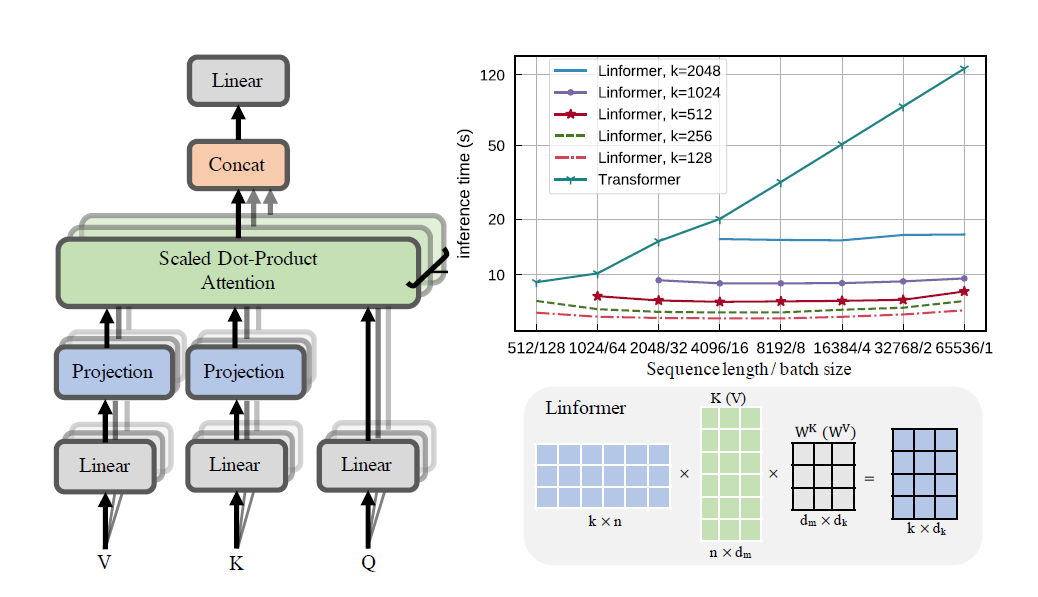
Практическая реализация бумаги Linformer. Это внимание только с линейной сложностью n, что позволяет обрабатывать последовательности очень большой длины (1 мил+) на современном оборудовании.
Этот репозиторий представляет собой преобразователь стиля «Внимание — это все, что вам нужно» в комплекте с модулем кодера и декодера. Новизна здесь в том, что теперь можно сделать головы внимания линейными. Узнайте, как его использовать ниже.
Это находится в процессе проверки на wikitext-2. В настоящее время он работает на том же уровне, что и другие механизмы разреженного внимания, такие как Синкхорн-трансформатор, но лучшие гиперпараметры еще предстоит найти.
Возможна также визуализация голов. Чтобы просмотреть дополнительную информацию, посетите раздел «Визуализация» ниже.
Я не являюсь автором статьи.
1,23 млн токенов
pip install linformer-pytorch
Альтернативно,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Языковая модель Линформер
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Linformer самообслуживание, стеки MHAttention и FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Linformer Multihead Внимание!
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)Головка линейного внимания, новинка статьи
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)Модуль кодера/декодера.
Примечание. Для причинно-следственных последовательностей можно установить флаг causal=True в LinformerLM , чтобы замаскировать правый верхний угол в матрице внимания (n,k) .
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) Простой способ получить матрицы E и F можно сделать, вызвав функцию get_EF . Например, для n = 1000 и k = 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) С помощью флага method можно установить метод, с помощью которого линформер выполняет понижающую дискретизацию. На данный момент поддерживаются три метода:
learnable : этот метод понижающей дискретизации создает обучаемый модуль n,k nn.Linear .convolution : этот метод понижающей дискретизации создает 1d-свертку с длиной шага и размером ядра n/k .no_params : создаёт фиксированную матрицу n,k со значениями от N(0,1/k).В будущем я могу включить пул или что-то еще. Но на данный момент такие варианты существуют.
В качестве попытки обеспечить дополнительную экономию памяти была введена концепция уровней контрольных точек. Текущие три уровня контрольных точек — C0 , C1 и C2 . При повышении уровня контрольных точек приходится жертвовать скоростью ради экономии памяти. То есть уровень контрольной точки C0 — самый быстрый, но занимает больше всего места на графическом процессоре, а C2 — самый медленный, но занимает меньше всего места на графическом процессоре. Подробности каждого уровня контрольной точки следующие:
C0 : Нет контрольных точек. Модели работают, сохраняя все головы внимания и слои ff в памяти графического процессора.C1 : Контрольная точка для каждого внимания MultiHead, а также для каждого слоя ff. При этом увеличение depth должно оказывать минимальное влияние на память.C2 : Наряду с оптимизацией на уровне C1 , проверьте каждую головку на каждом уровне внимания MultiHead. При этом увеличение nhead должно оказывать меньшее влияние на память. Однако объединение голов с помощью torch.cat по-прежнему занимает много памяти, и мы надеемся, что в будущем это будет оптимизировано.Подробности производительности пока неизвестны, но существует возможность для пользователей, которые хотят попробовать.
Еще одной попыткой экономии памяти в статье было введение совместного использования параметров между прогнозами. Об этом упоминается в разделе 4 статьи; в частности, авторы обсуждали 4 различных типа совместного использования параметров, и все они были реализованы в этом репозитории. Первый вариант занимает больше всего памяти, и каждый последующий вариант уменьшает необходимые требования к памяти.
none : совместного использования параметров нет. Для каждой головки и каждого слоя рассчитывается новая матрица E и новая F матрица для каждой головки на каждом слое.headwise : каждый слой имеет уникальную матрицу E и F Все головы в слое используют эту матрицу.kv : Каждый слой имеет уникальную матрицу проекции P и E = F = P для каждого слоя. Все головы разделяют эту матрицу проекции Playerwise : существует одна матрица проекции P , и каждая голова в каждом слое использует E = F = P Как было указано в статье, это означает, что для сети с 12 слоями и 12 головками будет 288 , 24 , 12 и 1 различных проекционных матриц соответственно.
Обратите внимание, что с параметром k_reduce_by_layer параметр layerwise не будет эффективен, поскольку для первого слоя будет использоваться размерность k . Следовательно, если значение k_reduce_by_layer больше 0 , скорее всего, не следует использовать опцию layerwise совместного использования.
Также обратите внимание, что, по мнению авторов на рис. 3, совместное использование параметров не слишком сильно влияет на конечный результат. Поэтому, возможно, лучше всего просто придерживаться layerwise обмена всем, но у пользователей есть возможность попробовать это.
Одна небольшая проблема с текущей реализацией Linformer заключается в том, что длина вашей последовательности должна соответствовать флагу input_size модели. Padder дополняет входной размер таким образом, чтобы тензор можно было передать в сеть. Пример:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 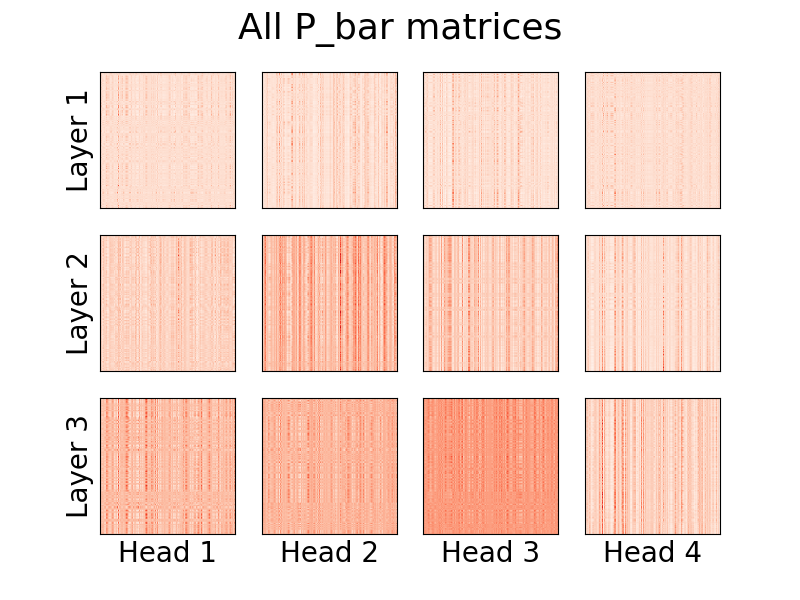
Начиная с версии 0.8.0 появилась возможность визуализировать внимание глав информера! Чтобы увидеть это в действии, просто импортируйте класс Visualizer и запустите plot_all_heads() , чтобы увидеть изображение всех голов внимания на каждом уровне размером (n,k). Убедитесь, что вы указали visualize=True при прямом проходе, так как при этом сохраняется матрица P_bar , чтобы класс Visualizer мог правильно визуализировать голову.
Рабочий пример кода можно найти ниже, тот же код можно найти в ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)Подробное объяснение того, что означают эти головы, можно найти в № 15.
Подобно «Реформеру», я попытаюсь создать модуль кодировщика/декодера, чтобы упростить обучение. Это работает как 2 класса LinformerLM . Параметры можно настроить индивидуально для каждого из них: кодер имеет префикс enc_ для всех гиперпараметров, а декодер имеет префикс dec_ аналогичным образом. На данный момент реализовано следующее:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )Я планирую найти способ генерировать для этого текстовую последовательность.
ff_intermediate настройка Теперь размер модели может быть разным в промежуточных слоях. Это изменение касается модуля ff и только энкодера. Теперь, если флаг ff_intermediate не равен None, слои будут выглядеть так:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
В отличие от
channels -> ff_dim -> channels (For all layers)
input_size и dim_k соответственно.apex , однако на практике это не проверено.input_size , k= dim_k и d= dim_d . LinformerEncDec Я впервые воспроизвожу результат из статьи, поэтому некоторые вещи могут быть неправильными. Если вы видите проблему, пожалуйста, откройте проблему, и я постараюсь над ней поработать.
Спасибо lucidrains, чьи другие репозитории с редким вниманием помогли мне в разработке этого репозитория Linformer.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}«Слушайте внимательно…»


