intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
? Интеллектуальные торговые сигналы ? https://t.me/intelligent_trading_signals
Проект направлен на разработку интеллектуального торгового бота для автоматической торговли криптовалютами с использованием современных алгоритмов машинного обучения (ML) и разработки функций. Проект предоставляет следующие основные функции:
Служба сигнализации работает в облаке и отправляет свои сигналы на этот канал Telegram:
? Интеллектуальные торговые сигналы ? https://t.me/intelligent_trading_signals
Каждый может подписаться на канал, чтобы получить представление о сигналах, которые генерирует этот бот.
На данный момент бот настроен по следующим параметрам:
Существуют периоды молчания, когда оценка ниже порогового значения и на канал не отправляются уведомления. Если оценка превышает порог, то каждую минуту отправляется уведомление вида
₿ 24,518 ??? Оценка: -0,26
Первое число — это последняя цена закрытия. Оценка -0,26 означает, что весьма вероятно увидеть цену ниже текущей цены закрытия.
Если оценка превышает некоторый порог, указанный в модели, генерируется сигнал на покупку или продажу, что означает, что сейчас подходящее время для совершения сделки. Такие уведомления выглядят следующим образом:
? КУПИТЬ: ₿ 24 033 Оценка: +0,34
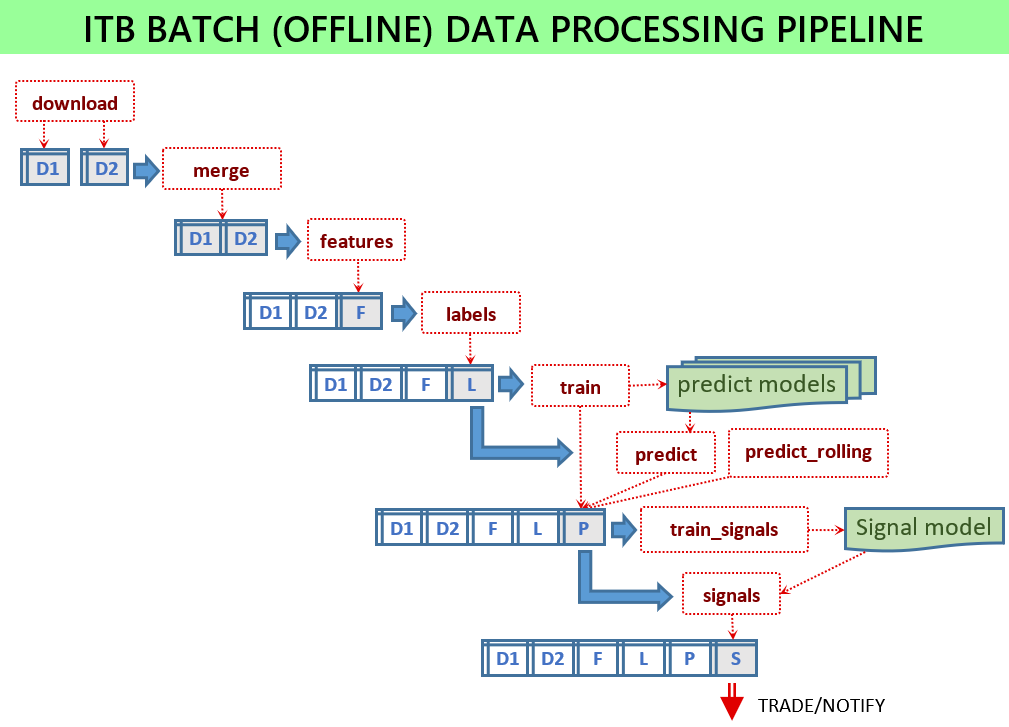
Чтобы служба сигнализатора работала, необходимо обучить несколько моделей машинного обучения и предоставить файлы моделей для службы. Все сценарии выполняются в пакетном режиме, загружая некоторые входные данные и сохраняя некоторые выходные файлы. Пакетные сценарии расположены в модуле scripts .
Если все настроено, то необходимо выполнить следующие скрипты:
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json Без файла конфигурации сценарии будут использовать параметры по умолчанию, что полезно для целей тестирования и не предназначено для демонстрации хорошей производительности. Используйте примеры файлов конфигурации, которые предоставляются для каждой версии, например config-sample-v0.6.0.jsonc .
Основным параметром конфигурации для обоих скриптов является список источников в data_sources . Одна запись в этом списке указывает источник данных, а также column_prefix используемый для различения столбцов с одинаковым именем из разных источников.
Загрузите последние исторические данные: python -m scripts.download_binance -c config.json
Объедините несколько наборов исторических данных в один: python -m scripts.merge -c config.json
Этот скрипт предназначен для вычисления производных функций:
python -m scripts.features -c config.json Список генерируемых функций настраивается через список feature_sets в файле конфигурации. То, как генерируются функции, определяется генератором функций, каждый из которых имеет некоторые параметры, указанные в разделе конфигурации.
talib опирается на библиотеку технического анализа TA-lib. Вот пример его конфигурации "config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats реализует функции, которые можно найти в tsfresh, такие как scipy_skew , scipy_kurtosis , lsbm (самый длинный страйк ниже среднего), fmax (первое местоположение максимума), mean , std , area , slope . Вот типичные параметры: "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib реализован в ITB, но большинство его функций можно сгенерировать (гораздо быстрее) с помощью talib.tsfresh генерирует функции из библиотеки tsfresh Этот сценарий похож на создание объектов, поскольку он добавляет новые столбцы во входной файл. Однако эти столбцы описывают то, что мы хотим спрогнозировать, и то, что неизвестно при выполнении в онлайн-режиме. Например, это может быть повышение цен в будущем:
python -m scripts.labels -c config.json Список генерируемых меток настраивается через список label_sets в конфигурации. Один набор меток указывает на функцию, которая генерирует дополнительные столбцы. Их конфигурация очень похожа на конфигурации функций.
highlow возвращает значение True, если цена превышает указанный порог в пределах некоторого будущего горизонта.highlow2 Вычисляет будущие увеличения (уменьшения) при условии, что до этого не было значительных сокращений (увеличений). Вот его типичная конфигурация "config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot устарелtopbot2 Вычисляет максимальное и минимальное значения (помеченные как True). Каждый отмеченный максимум (минимум) гарантированно окружен минимумами (максимумами) ниже (выше) указанного уровня. Требуемая минимальная разница между соседними минимумами и максимумами задается с помощью параметров level . Параметр допуска позволяет включать также точки, близкие к максимуму/минимуму. Вот типичная конфигурация: "config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} Этот скрипт использует указанные входные функции и метки для обучения нескольких моделей машинного обучения:
python -m scripts.train -c config.jsonprediction-metrics.txt с оценками прогнозов для всех моделей.Конфигурация:
model_store.pytrain_featureslabelsalgorithms Цель этого шага — агрегировать оценки прогнозов, сгенерированные разными алгоритмами для разных меток. Результатом является одна оценка, которая должна быть использована правилами сигналов на следующем этапе. Параметры агрегации указываются в разделе score_aggregation . buy_labels и sell_labels определяют входные прогнозируемые оценки, обрабатываемые процедурой агрегирования. window — это количество предыдущих шагов, использованных для скользящего агрегирования, а combine — это способ объединения двух типов оценок (покупка и метки) в одну выходную оценку.
Оценка, полученная в результате процедуры агрегирования, представляет собой некоторое число, и цель правил сигналов — принять торговые решения: покупать, продавать или ничего не делать. Параметры правил сигналов описаны в trade_model .
Этот скрипт моделирует сделки, используя множество параметров сигналов покупки-продажи, а затем выбирает наиболее эффективные параметры сигнала:
python -m scripts.train_signals -c config.jsonЭтот скрипт запускает сервис, который периодически выполняет одну и ту же задачу: загружает последние данные, генерирует функции, делает прогнозы, генерирует сигналы, уведомляет подписчиков:
python -m service.server -c config.jsonЕсть две проблемы:
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.jsonПараметры конфигурации указаны в двух файлах:
service.App.py в поле config класса App .-c config.jsom для служб и сценариев. Значения из этого файла конфигурации перезапишут значения в App.config , когда этот файл загружается в скрипт или службу. Вот некоторые наиболее важные поля (как в App.py , так и в config.json ):
data_folder — расположение файлов данных, которые необходимы только для пакетных автономных сценариев.symbol — это торговая пара, такая как BTCUSDTlabels Список имен столбцов, которые рассматриваются как метки. Если вы определяете новую метку, используемую для обучения, а затем для прогнозирования, вам необходимо указать здесь ее имя.algorithms Список названий алгоритмов, используемых для обученияtrain_features Список всех имен столбцов, используемых в качестве входных функций для обучения и прогнозирования.buy_labels и sell_labels Списки прогнозируемых столбцов, используемых для сигналовtrade_model Параметры сигнализатора (в основном некоторые пороги)trader — раздел параметров трейдера. На данный момент тщательно не проверено.collector Этот раздел параметров предназначен для служб сбора данных. Существует два типа сервисов сбора данных: синхронный с регулярными запросами к поставщику данных и асинхронный потоковый сервис, который подписывается на поставщика данных и получает уведомления, как только становятся доступны новые данные. Они работают, но не протестированы и не интегрированы в основной сервис. Текущая основная схема использования основана на пакетном обновлении данных вручную, создании признаков и обучении модели. Одной из причин использования этих служб сбора данных является 1) более быстрое обновление 2) наличие данных, недоступных в обычном API, таком как книга заказов (существуют некоторые функции, которые используют эти данные, но они не интегрированы в основной рабочий процесс).Дополнительные сведения см. в примерах файлов конфигурации и комментариях в App.config.
Каждую минуту сигнализатор выполняет следующие шаги, чтобы сделать прогноз о том, будет ли цена увеличиваться или уменьшаться:
Примечания:
Запуск службы: python3 -m service.server -c config.json
Трейдер рабочий, но не до конца отлаженный, в частности, не проверенный на стабильность и надежность. Поэтому его следует рассматривать как прототип с базовым функционалом. В настоящее время он интегрирован с Signaler, но в лучшем дизайне он должен быть отдельной службой.
Бэктестирование
Внешние интеграции


