rtdl num embeddings
v0.0.11
Важный
Ознакомьтесь с новой табличной моделью DL: TabM
арXiv? Пакет Python Другие табличные проекты DL
Это официальная реализация статьи «О встраиваниях числовых функций в табличном глубоком обучении».
Одним предложением: преобразование исходных скалярных непрерывных функций в векторы перед их смешиванием в основной магистрали (например, в MLP, Transformer и т. д.) улучшает производительность последующих табличных нейронных сетей.
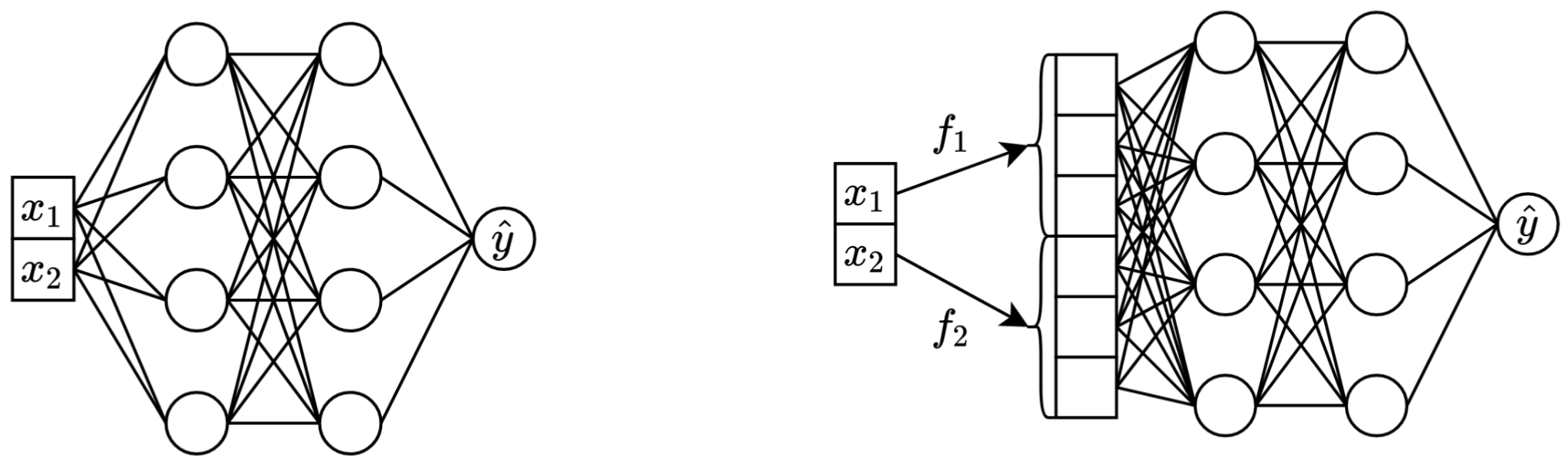
Слева: стандартный MLP, принимающий в качестве входных данных два непрерывных объекта.
Справа: тот же MLP, но теперь с вложениями для непрерывных функций.
Более подробно:
Строго говоря, единого объяснения нет. Очевидно, что встраивания помогают решать различные проблемы, связанные с непрерывными функциями, и улучшают общие оптимизационные свойства моделей.
В частности, неравномерно распределенные непрерывные функции (и их неравномерное совместное распределение с метками) — обычное явление в реальных табличных данных, и они представляют собой серьезную фундаментальную проблему оптимизации для традиционных табличных моделей DL. Отличным справочником для понимания этой проблемы (и отличным примером решения этих проблем путем преобразования входного пространства) является статья «Фурье-функции позволяют сетям изучать высокочастотные функции в низкоразмерных областях».
Однако неясно, являются ли нерегулярные распределения единственной причиной полезности вложений.
Пакет Python в каталоге package/ — это рекомендуемый способ использования статьи на практике и в будущей работе.
Остальная часть документа :
Каталог exp/ содержит многочисленные результаты и (настроенные) гиперпараметры для различных моделей и наборов данных, использованных в статье.
Например, давайте рассмотрим метрики модели MLP. Сначала загрузим отчеты (файлы report.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'exp' ). glob ( 'mlp/*/0_evaluation/*/report.json' )
])Теперь для каждого набора данных давайте посчитаем средний балл теста по всем случайным начальным значениям:
print ( df . groupby ( 'config.data.path' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Результат точно соответствует Таблице 3 из статьи:
config.data.path
data/adult 0.854
data/california -0.495
data/churn 0.856
data/covtype 0.964
data/fb-comments -5.686
data/gesture 0.632
data/higgs-small 0.720
data/house -32039.399
data/microsoft -0.747
data/otto 0.818
data/santander 0.912
Name: metrics.test.score, dtype: float64
Вышеупомянутый подход также можно использовать для исследования гиперпараметров, чтобы получить представление о типичных значениях гиперпараметров для различных алгоритмов. Например, вот как можно вычислить медианную настроенную скорость обучения для модели MLP:
Примечание
Для некоторых алгоритмов (например, MLP, MLP-LR, MLP-PLR) более поздние проекты предлагают больше результатов, которые можно исследовать аналогичным образом. Например, см. этот документ о TabR.
Предупреждение
Используйте этот подход с осторожностью. При изучении значений гиперпараметров:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002716544410603358Важный
Этот раздел длинный. Используйте функцию «Структура» на GitHub в своем текстовом редакторе, чтобы получить обзор этого раздела.
Предварительные сведения:
/usr/local/cuda-11.1/bin всегда находится в переменной среды PATH export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/num-embeddings
git clone https://github.com/yandex-research/tabular-dl-num-embeddings $PROJECT_DIR
cd $PROJECT_DIR
conda create -n num-embeddings python=3.9.7
conda activate num-embeddings
pip install torch==1.10.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
# the following command appends ":/usr/local/cuda-11.1/lib64" to LD_LIBRARY_PATH;
# if your LD_LIBRARY_PATH already contains a path to some other CUDA, then the content
# after "=" should be "<your LD_LIBRARY_PATH without your cuda path>:/usr/local/cuda-11.1/lib64"
conda env config vars set LD_LIBRARY_PATH= ${LD_LIBRARY_PATH} :/usr/local/cuda-11.1/lib64
conda env config vars set CUDA_HOME=/usr/local/cuda-11.1
conda env config vars set CUDA_ROOT=/usr/local/cuda-11.1
# (optional) get a shortcut for toggling the dark mode with cmd+y
conda install nodejs
jupyter labextension install jupyterlab-theme-toggle
conda deactivate
conda activate num-embeddingsЛИЦЕНЗИЯ: загружая наш набор данных, вы принимаете лицензии на все его компоненты. Мы не налагаем никаких новых ограничений в дополнение к этим лицензиям. Список источников вы можете найти в статье.
cd $PROJECT_DIR
wget " https://www.dropbox.com/s/r0ef3ij3wl049gl/data.tar?dl=1 " -O num_embeddings_data.tar
tar -xvf num_embeddings_data.tarКод ниже воспроизводит результаты для MLP в наборе данных по жилищному строительству Калифорнии. Конвейер для других алгоритмов и наборов данных абсолютно такой же.
# You must explicitly set CUDA_VISIBLE_DEVICES if you want to use GPU
export CUDA_VISIBLE_DEVICES="0"
# Create a copy of the 'official' config
cp exp/mlp/california/0_tuning.toml exp/mlp/california/1_tuning.toml
# Run tuning (on GPU, it takes ~30-60min)
python bin/tune.py exp/mlp/california/1_tuning.toml
# Evaluate single models with 15 different random seeds
python bin/evaluate.py exp/mlp/california/1_tuning 15
# Evaluate ensembles (by default, three ensembles of size five each)
python bin/ensemble.py exp/mlp/california/1_evaluation
В разделе «Метрики» показано, как обобщить полученные результаты.
Код организован следующим образом:
bintrain4.py для нейронных сетей (он реализует все вложения и основы из статьи)xgboost_.py для XGBoostcatboost_.py для CatBoosttune.py для настройкиevaluate.py для оценкиensemble.py для ансамбляdatasets.py использовался для построения разделения набора данных.synthetic.py для создания синтетических наборов данных, совместимых с GBDT.train1_synthetic.py для экспериментов с синтетическими даннымиlib содержит общие инструменты, используемые программами в binexp содержит конфигурации и результаты экспериментов (метрики, настроенные конфигурации и т. д.). Имена вложенных папок следуют за именами из статьи (пример: exp/mlp-plr соответствует модели MLP-PLR из статьи).package содержит пакет Python для этой статьиCUDA_VISIBLE_DEVICES при запуске сценариев.lib.dump_config и lib.load_config вместо голых библиотек TOML.Общий шаблон запуска сценариев:
python bin/my_script.py a/b/c.toml где a/b/c.toml — входной файл конфигурации (config). Выход будет расположен по адресу a/b/c . Структура конфигурации обычно соответствует классу Config из bin/my_script.py .
Существуют также скрипты, которые принимают аргументы командной строки вместо конфигураций (например, bin/{evaluate.py,ensemble.py} ).
Они все вам нужны для воспроизведения результатов, но для дальнейшей работы вам понадобится только train4.py , потому что:
bin/train1.py реализует расширенный набор функций из bin/train0.pybin/train3.py реализует расширенный набор функций из bin/train1.pybin/train4.py реализует расширенный набор функций из bin/train3.py Чтобы узнать, какой из четырех скриптов использовался для запуска данного эксперимента, проверьте поле «программа» соответствующего конфига настройки. Например, вот конфигурация настройки для MLP в наборе данных California Housing: exp/mlp/california/0_tuning.toml . В конфигурации указано, что использовался bin/train0.py . Это означает, что конфиги в exp/mlp/california/0_evaluation конкретно совместимы с bin/train0.py . Чтобы убедиться в этом, вы можете скопировать один из них в отдельное место и перейти к bin/train0.py :
mkdir exp/tmp
cp exp/mlp/california/0_evaluation/0.toml exp/tmp/0.toml
python bin/train0.py exp/tmp/0.toml
ls exp/tmp/0
@inproceedings{gorishniy2022embeddings,
title={On Embeddings for Numerical Features in Tabular Deep Learning},
author={Yury Gorishniy and Ivan Rubachev and Artem Babenko},
booktitle={{NeurIPS}},
year={2022},
}


