gigagan pytorch
0.2.20

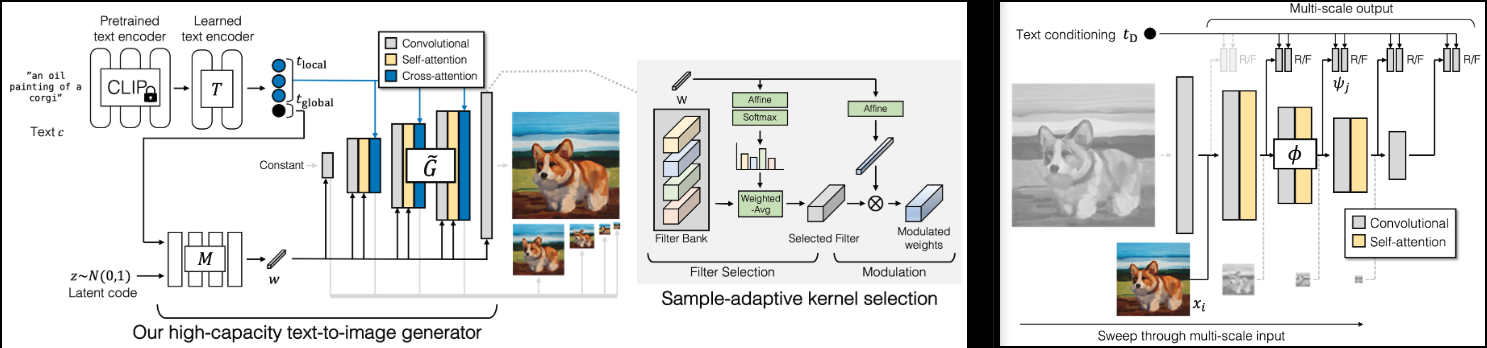
Реализация GigaGAN (страница проекта), новый SOTA GAN от Adobe.
Я также добавлю несколько выводов из легкого гана, для более быстрой сходимости (пропустить возбуждение слоя) и лучшей стабильности (восстановление вспомогательных потерь в дискриминаторе)
Он также будет содержать код для повышающих дискретизации 1–4 тыс., что, по моему мнению, является изюминкой этой статьи.
Пожалуйста, присоединяйтесь, если вы заинтересованы в помощи в воспроизведении с сообществом LAION.
СтабильностьAI и ? Huggingface за щедрую спонсорскую поддержку, а также другим моим спонсорам за предоставление мне независимости в области искусственного интеллекта с открытым исходным кодом.
? Huggingface за библиотеку ускорения
Всем специалистам по сопровождению OpenClip за их модели SOTA с открытым исходным кодом для контрастного обучения «текст-изображение».
Ксавьеру за очень полезный обзор кода и за обсуждение того, как следует обеспечивать масштабную инвариантность в дискриминаторе!
@CerebralSeed за запрос на вытягивание исходного кода выборки как для генератора, так и для повышающей дискретизации!
Кирту за проверку кода и указание на некоторые несоответствия с статьей!
$ pip install gigagan-pytorchПростой безусловный GAN, для начала.
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)Для безусловного Unet Upsampler
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - ГенераторMSG — многомасштабный генераторD – ДискриминаторMSD — многомасштабный дискриминаторGP – Градиентный штрафSSL — вспомогательная реконструкция в дискриминаторе (из облегченного GAN)VD - Дискриминатор с визуальным контролемVG - Генератор с визуальным контролемCL — Констративные потери генератораMAL – сопоставление с учетом потерь В нормальном режиме будут G , MSG , D , MSD со значениями, колеблющимися от 0 до 10 и обычно остающимися довольно постоянными. Если в любой момент после 1 тыс. шагов обучения эти значения сохранятся на трехзначном уровне, это будет означать, что что-то не так. Это нормально, если значения генератора и дискриминатора иногда опускаются до отрицательных значений, но они должны вернуться обратно в указанный выше диапазон.
GP и SSL должны быть переведены в сторону 0 . GP может иногда резко повышаться; Мне нравится представлять это, как сети, переживающие некое прозрение.
Класс GigaGAN теперь оснащен? Ускоритель. Вы можете легко выполнить обучение с использованием нескольких графических процессоров в два этапа, используя их accelerate интерфейс командной строки.
В корневом каталоге проекта, где находится сценарий обучения, запустите
$ accelerate configЗатем в том же каталоге
$ accelerate launch train . py убедитесь, что его можно обучить безоговорочно
прочитайте соответствующие статьи и выбейте все 3 вспомогательные потери
модуль повышения частоты дискретизации unet
получить обзор кода для многомасштабных входов и выходов, так как статья была немного расплывчатой
добавить сетевую архитектуру с повышающей дискретизацией
выполнить безусловную работу как для базового генератора, так и для повышающего семплера
заставить текстовое обучение работать как для базовой, так и для повышающей дискретизации
сделать разведку более эффективной с помощью патчей случайной выборки
убедитесь, что генератор и дискриминатор также могут принимать предварительно закодированные текстовые кодировки CLIP
сделать обзор вспомогательных потерь
добавьте несколько дифференцируемых дополнений, проверенную технику старых времен GAN
переместить все проекции модуляции в адаптивный класс conf2d
добавить ускорение
клип должен быть необязательным для всех модулей и управляться GigaGAN , при этом встраивание текста -> текста обрабатывается один раз.
добавить возможность выбирать случайное подмножество из многомасштабного измерения для повышения эффективности
порт через CLI из облегченного | stylegan2-pytorch
подключить набор данных Laion для текстового изображения
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

