byol pytorch
0.8.2
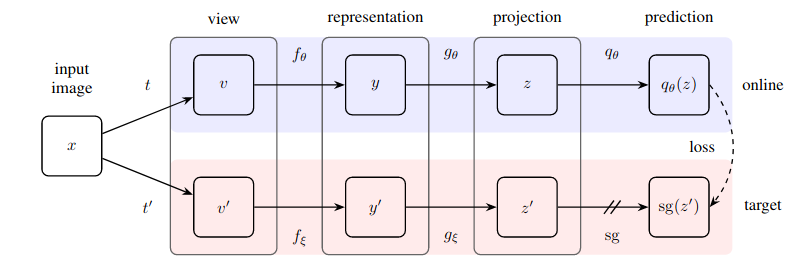
Практическая реализация поразительно простого метода самостоятельного обучения, который достигает нового уровня техники (превосходит SimCLR) без контрастного обучения и необходимости обозначения отрицательных пар.
Этот репозиторий предлагает модуль, в который можно легко обернуть любую нейронную сеть на основе изображений (остаточную сеть, дискриминатор, сеть политик), чтобы немедленно начать получать выгоду от немаркированных данных изображений.
Обновление 1: теперь появились новые доказательства того, что нормализация партий является ключом к эффективной работе этого метода.
Обновление 2: В новой статье норма партии успешно заменена групповой нормой + стандартизация веса, опровергая необходимость статистики партии для работы BYOL.
Обновление 3. Наконец, у нас есть некоторый анализ того, почему это работает.
Отличное объяснение Янника Килчера
Теперь избавьте свою организацию от необходимости платить за лейблы :)
$ pip install byol-pytorchПросто подключите свою нейронную сеть, указав (1) размеры изображения, а также (2) имя (или индекс) скрытого слоя, выходные данные которого используются в качестве скрытого представления, используемого для самостоятельного обучения.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Вот и все. После длительного обучения остаточная сеть теперь должна лучше выполнять свои последующие контролируемые задачи.
В новой статье Кайминга Хэ предполагается, что BYOL даже не требует, чтобы целевой кодировщик был экспоненциальным скользящим средним онлайн-кодировщика. Я решил встроить эту опцию, чтобы вы могли легко использовать этот вариант для обучения, просто установив для флага use_momentum значение False . Вам больше не нужно будет вызывать update_moving_average , если вы пойдете по этому пути, как показано в примере ниже.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Хотя для гиперпараметров уже установлены значения, которые в статье признаны оптимальными, вы можете изменить их с помощью дополнительных ключевых аргументов базового класса-оболочки.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) По умолчанию эта библиотека будет использовать дополнения из статьи SimCLR (которая также используется в статье BYOL). Однако, если вы хотите указать свой собственный конвейер расширения, вы можете просто передать свою собственную функцию расширения с помощью ключевого слова augment_fn .
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)В статье они, похоже, уверяют, что одно из дополнений имеет более высокую вероятность размытия по Гауссу, чем другое. Вы также можете настроить это по своему усмотрению.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) Чтобы получить внедрения или проекции, вам просто нужно передать флаг return_embeddings = True экземпляру учащегося BYOL .
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) Репозиторий теперь предлагает распределенное обучение с помощью ? Обнимающее лицо Ускорение. Вам просто нужно передать свой собственный Dataset в импортированный BYOLTrainer
Сначала настройте конфигурацию для распределенного обучения, вызвав интерфейс ускорения.
$ accelerate config Затем создайте сценарий обучения, как показано ниже, скажем, в ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()Затем снова используйте ускоренный интерфейс командной строки, чтобы запустить скрипт.
$ accelerate launch ./train.pyЕсли ваша последующая задача включает в себя сегментацию, просмотрите следующий репозиторий, который расширяет BYOL до обучения на уровне пикселей.
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

