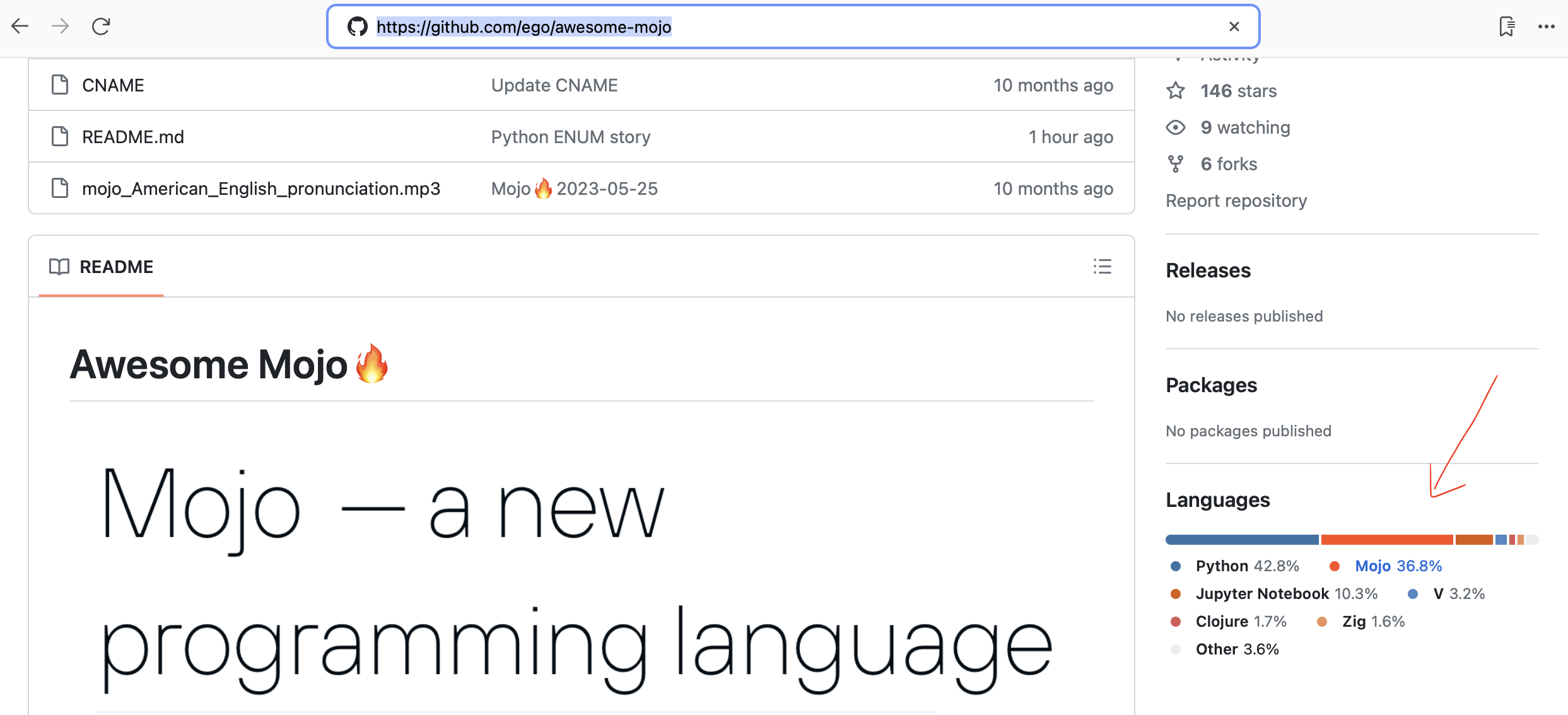
awesome mojo
1.0.0

Mojo — новый язык программирования для всех разработчиков, ученых в области искусственного интеллекта и машинного обучения и инженеров-программистов.
Кураторский список потрясающего кода Mojo, решений проблем, а также будущих библиотек, фреймворков, программного обеспечения и ресурсов.
Давайте аккумулировать здесь самые новые технологические знания и передовой опыт.
Mojo — это язык программирования, сочетающий в себе удобство Python с производительностью C++ и Rust. Кроме того, Mojo позволяет пользователям использовать обширную экосистему библиотек Python.
Вкратце
Mojo — это новый язык программирования, который устраняет разрыв между исследованиями и производством, сочетая лучшее из синтаксиса Python с системным программированием и метапрограммированием.
hello.mojo или hello. расширение файла может быть смайликом!
Вы можете узнать больше о том, почему Modular делает это. Почему Mojo
Нам нужна была инновационная и масштабируемая модель программирования, которая могла бы быть ориентирована на ускорители и другие гетерогенные системы, широко распространенные в области искусственного интеллекта. ... Прикладные системы искусственного интеллекта должны решать все эти проблемы, и мы решили, что нет причин, по которым это нельзя было бы сделать с помощью всего лишь одного языка. Так родился Моджо.
Но Python отлично справился со своей задачей =)
Мы не видели никакой необходимости в инновациях в синтаксисе языка или сообществе. Поэтому мы решили использовать экосистему Python, потому что она широко используется, ее любит экосистема искусственного интеллекта и потому что мы считаем, что это действительно хороший язык.
Моджо означает «магическое очарование» или «магические силы». Мы подумали, что это подходящее название для языка, который придаёт Python магические возможности :python:, включая открытие инновационной модели программирования для ускорителей и других гетерогенных систем, широко распространённых сегодня в искусственном интеллекте.
Гвидо ван Россум, пожизненный доброжелательный диктатор, и Кристофер Артур Латтнер, выдающийся изобретатель, создатель и известный лидер в области произношения Моджо =)
Судя по описанию
Кто знает, будут ли эти языки программирования очень довольны, ведь Mojo извлекает пользу из огромных уроков, извлеченных из других языков Rust, Swift, Julia, Zig, Nim и т. д.
[новый]
Github теперь автоматически определяет код Mojo!
Простой и быстрый HTTP-фреймворк для Mojo! Идеально подходит для создания веб-сервисов и простых API. Для моджичан
Система сравнительного анализа реализаций LLama
Автоматизированный перевод кода Python в Mojo
Исследование базы данных языка программирования
19 октября 2023 г. Mojo теперь доступен на Mac! Используйте консоль разработчика
Крис Лэттнер: Будущее программирования и искусственного интеллекта | Подкаст Лекса Фридмана №381
Объяснение системы типов Mojo и Python | Крис Лэттнер и Лекс Фридман
Может ли Mojo запускать код Python? | Крис Лэттнер и Лекс Фридман
Переход с Python на язык программирования Mojo | Крис Лэттнер и Лекс Фридман
Новая тема GitHub mojo-lang. Так что вы можете следить за ним.
Гвидо ван Россум о Mojo = Python с производительностью C++/GPU?
Тензорная структура с некоторыми базовыми операциями #251
Матрица fn с номером #267
Обновления о lambda выражениях и замыканиях parameter , а также функциях более высокого порядка в mojo #244.
25 мая 2023 г. Гвидо ван Россум (gvanrossum#8415), создатель и почетный BDFL Python, посетите общедоступный чат Discord Mojo.
Ожидание подсветки синтаксиса Mojo на GitHub
New Mojoвыпуск 24 мая 2023 г.
[старый]
Моджо
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon
Версии Python/Mojo/Codon/Rust
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)Давайте найдем последовательность Фибоначчи, где
Н = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py 'РЕЗУЛЬТАТ: ТАЙМ-АУТ, я отменил вычисления через 1 минуту.
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py ' РЕЗУЛЬТАТ :
Тест 1: тесты python3/fibonacci_sequence/python_iteration.py
Время (среднее ± σ): 16374,7 ± 904,0 мкс [Пользователь: 11483,5 мкс, Система: 3680,0 мкс]
Диапазон (мин… макс): 15361,0 мкс… 22863,3 мкс 100 запусков
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc ' РЕЗУЛЬТАТ :
Тест 1: тесты python3/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
Время (среднее ± σ): 16 584,6 мкс ± 761,5 мкс [Пользователь: 11 451,8 мкс, система: 3813,3 мкс]
Диапазон (мин… макс): 15592,0 мкс… 20953,2 мкс 100 запусков
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo 'РЕЗУЛЬТАТ: ТАЙМ-АУТ, я отменил вычисления через 1 минуту.
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo ' РЕЗУЛЬТАТ :
Тест 1: тесты запуска mojo/fibonacci_sequence/mojo_iteration.mojo
Время (среднее ± σ): 43852,7 мкс ± 1353,5 мкс [Пользователь: 38156,0 мкс, Система: 10407,3 мкс]
Диапазон (мин… макс): 42033,6 мкс… 49357,3 мкс 100 запусков
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration ' РЕЗУЛЬТАТ :
Тест 1: ./benchmarks/fibonacci_sequence/mojo_iteration
Время (среднее ± σ): 934,6 ± 468,9 мкс [Пользователь: 409,8 мкс, Система: 247,8 мкс]
Диапазон (мин… макс): 552,7 мкс… 4522,9 мкс 100 запусков
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon 'РЕЗУЛЬТАТ: ТАЙМ-АУТ, я отменил вычисления через 1 минуту.
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon ' РЕЗУЛЬТАТ :
Тест 1: запуск кодона --release тесты/fibonacci_sequence/codon_iteration.codon
Время (среднее ± σ): 628060,1 мкс ± 10430,5 мкс [Пользователь: 584524,3 мкс, Система: 39358,5 мкс]
Диапазон (мин… макс): 612742,5 мкс… 662716,9 мкс 100 запусков
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration ' РЕЗУЛЬТАТ :
Тест 1: ./benchmarks/fibonacci_sequence/codon_iteration.
Время (среднее ± σ): 2732,7 ± 1145,5 мкс [Пользователь: 1466,0 мкс, Система: 1061,5 мкс]
Диапазон (мин… макс): 2036,6 мкс… 13236,3 мкс 100 запусков
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion 'РЕЗУЛЬТАТ: ТАЙМ-АУТ, я отменил вычисления через 1 минуту.
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration ' РЕЗУЛЬТАТ :
Тест 1: ./benchmarks/fibonacci_sequence/rust_iteration
Время (среднее ± σ): 848,9 мкс ± 283,2 мкс [Пользователь: 371,8 мкс, Система: 261,4 мкс]
Диапазон (мин… макс): 525,9 мкс… 2607,3 мкс 100 запусков
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.pngРасширенная статистика
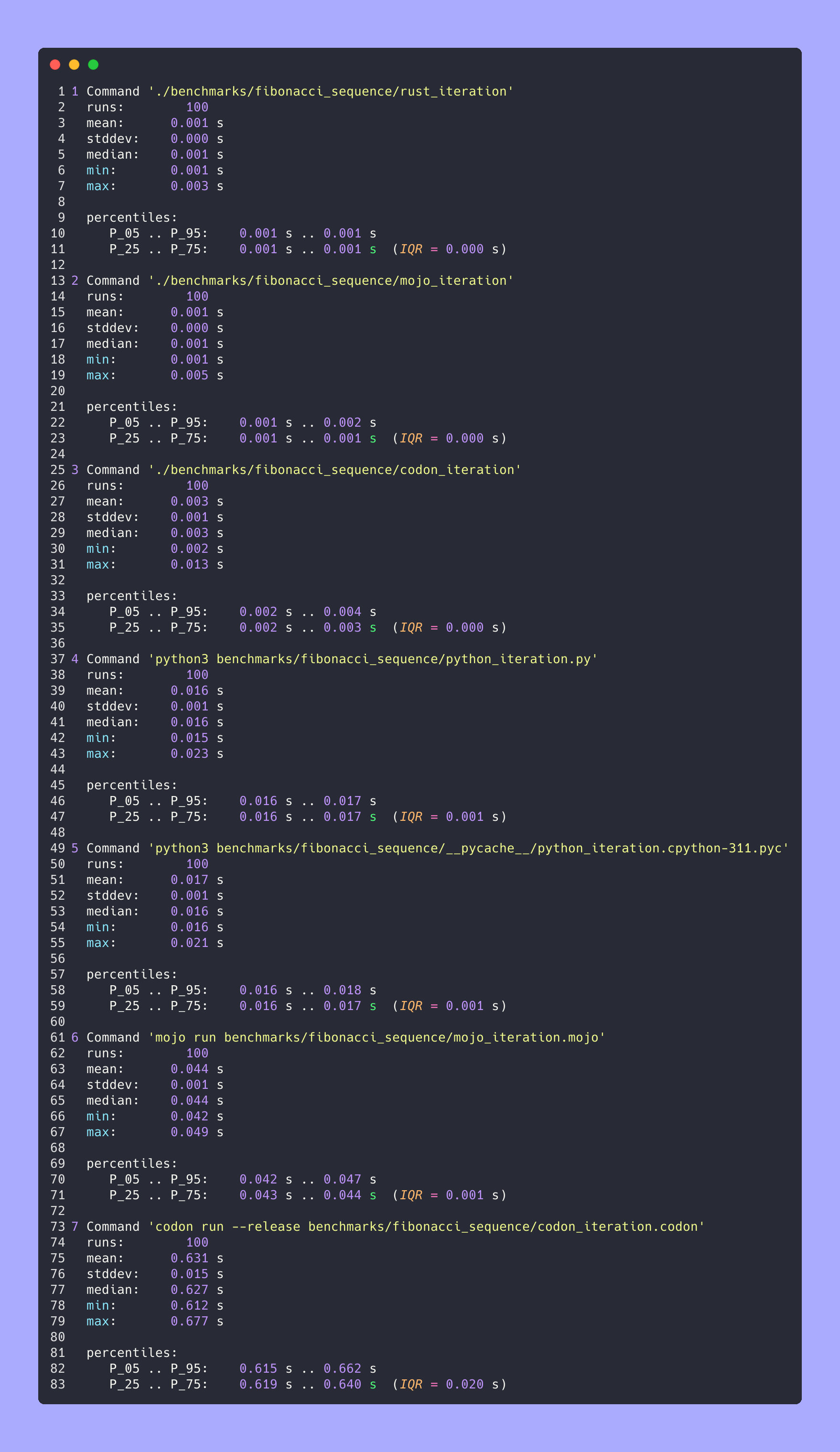
Все вместе
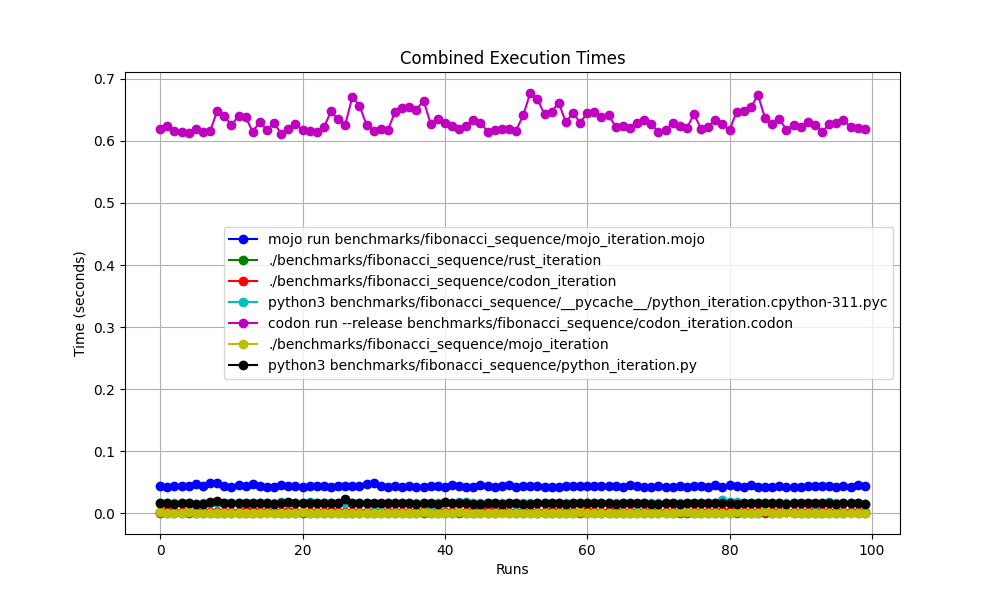
Увеличено
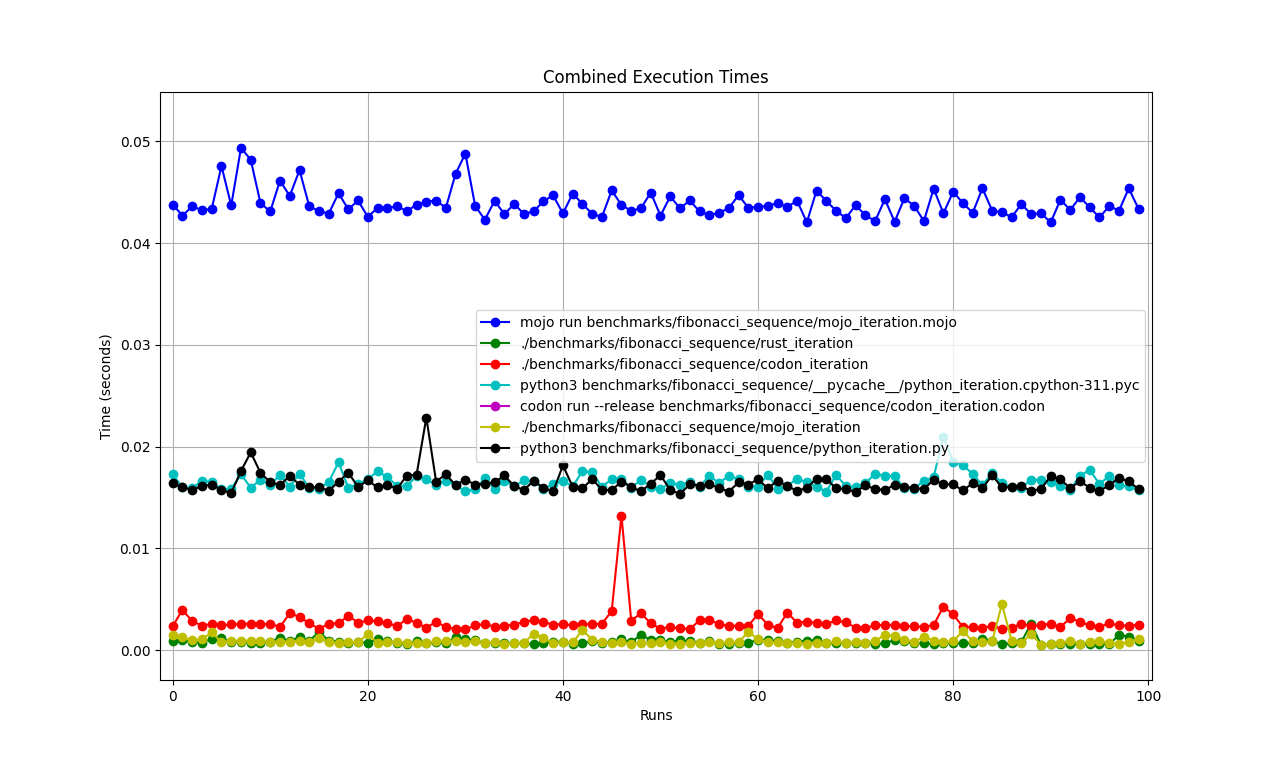
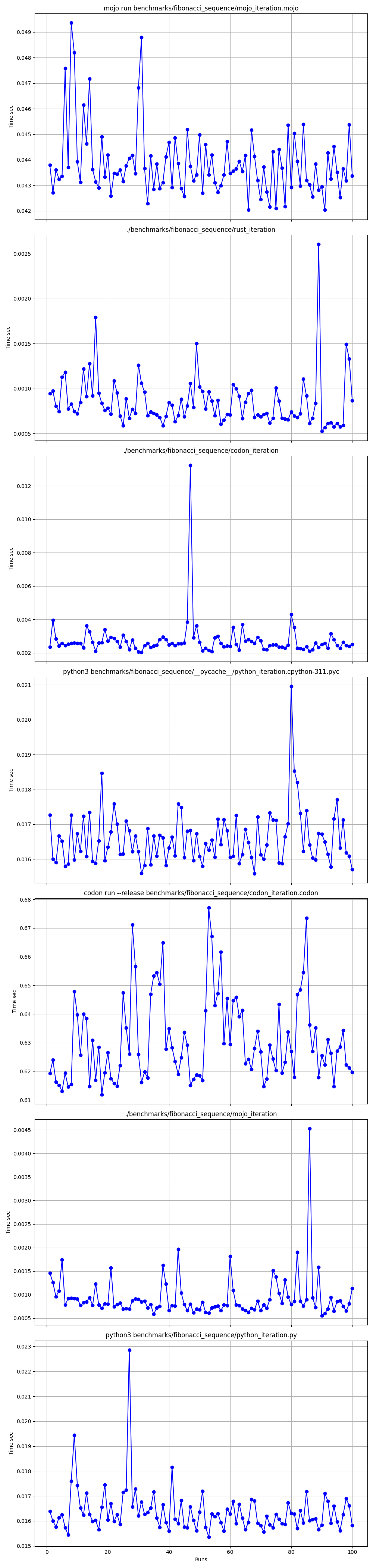
Подробно один за другим
Места
Но тут много вопросов:
mojo run так медленно?codon run --release так медленно?run быстрее, чем Mojo/Codon?Итак, можно сказать, что Mojo так же быстр, как и Rust на Mac!
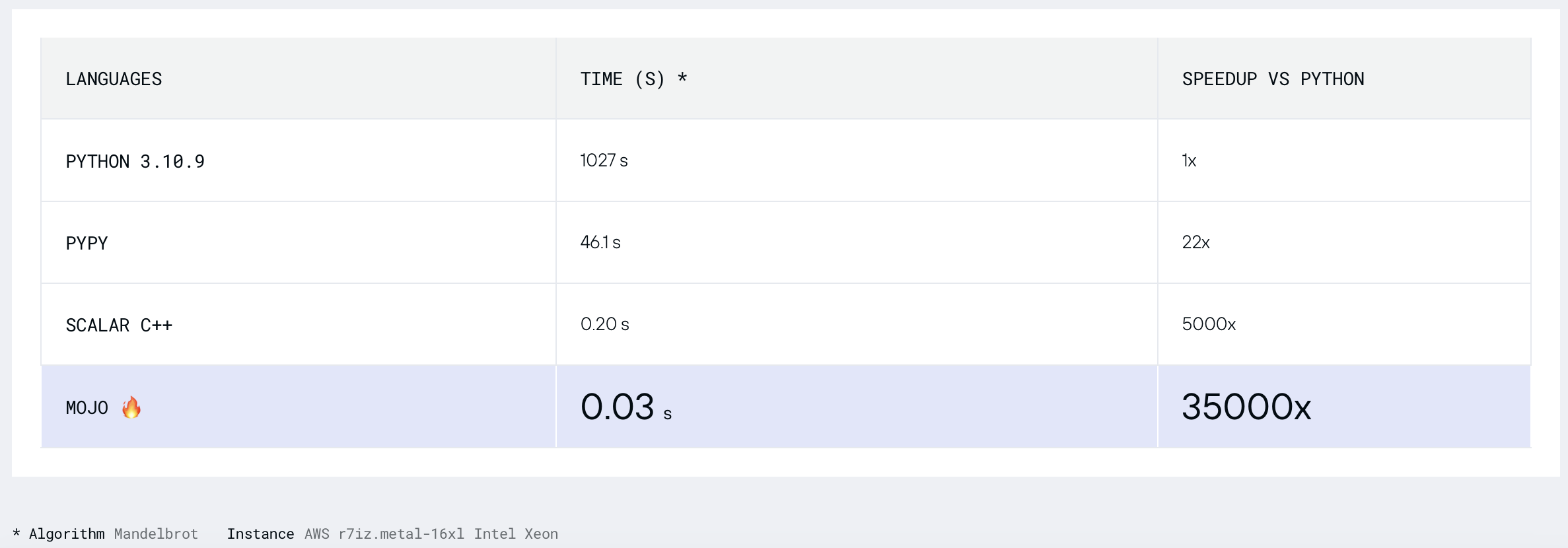
Найдем множество Мандельброта, где
ШИРИНА = 960
ВЫСОТА = 960
MAX_ITERS = 200
МИН_Х = -2,0
МАКС_Х = 0,6
МИН_Г = -1,5
МАКС_Y = 1,5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
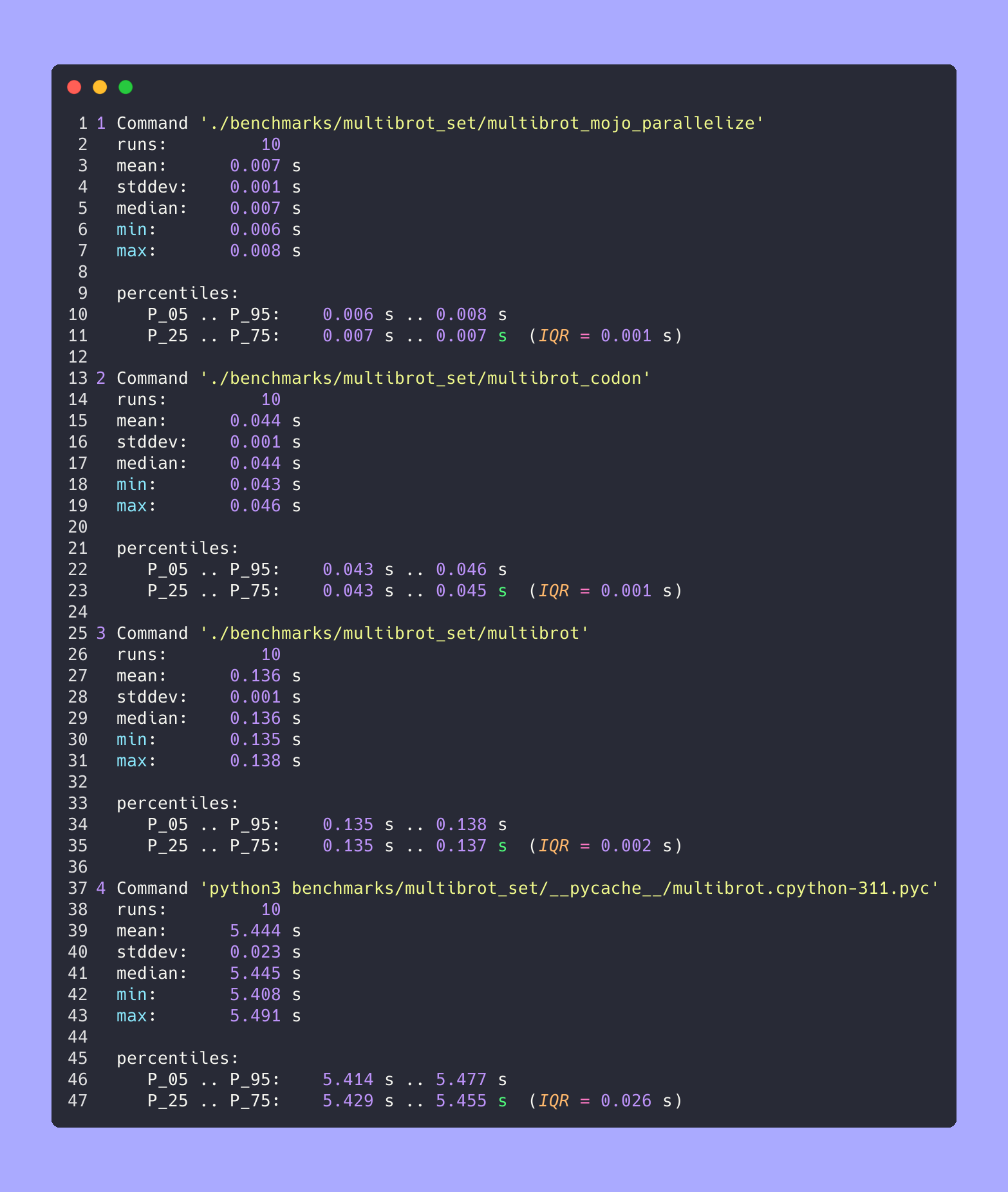
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc ' РЕЗУЛЬТАТ :
Тест 1: тесты python3/multibrot_set/ pycache /multibrot.cpython-311.pyc
Время (среднее ± σ): 5444155,4 мкс ± 23059,7 мкс [Пользователь: 5419790,1 мкс, Система: 18131,3 мкс]
Диапазон (мин…макс): 5408155,3 мкс… 5490548,4 мкс 10 запусков
Версия Mojo без оптимизации.
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot ' РЕЗУЛЬТАТ :
Тест 1: ./benchmarks/multibrot_set/multibrot
Время (среднее ± σ): 135880,5 мкс ± 1175,4 мкс [Пользователь: 133309,3 мкс, Система: 1700,1 мкс]
Диапазон (мин… макс): 134639,9 мкс… 137621,4 мкс 10 запусков
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize ' РЕЗУЛЬТАТ :
Тест 1: ./benchmarks/multibrot_set/multibrot_mojo_parallelize
Время (среднее ± σ): 7139,4 мкс ± 596,4 мкс [Пользователь: 36535,2 мкс, Система: 6670,1 мкс]
Диапазон (мин… макс): 6222,6 мкс… 8269,7 мкс 10 запусков
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
Для тестового запуска или построения графика (раскомментируйте код в файле)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codonСтройте и запускайте
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon ' РЕЗУЛЬТАТ :
Тест 1: ./benchmarks/multibrot_set/multibrot_codon
Время (среднее ± σ): 44184,7 мкс ± 1142,0 мкс [Пользователь: 248773,9 мкс, Система: 72935,3 мкс]
Диапазон (мин… макс): 42963,8 мкс… 46456,2 мкс 10 запусков
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.pngРасширенная статистика
Все вместе
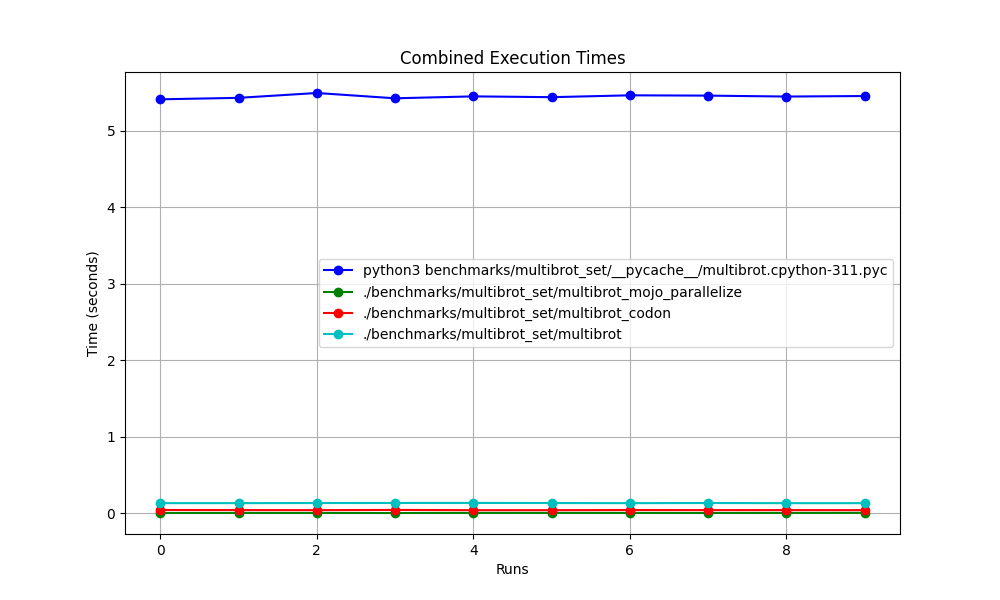
Увеличено
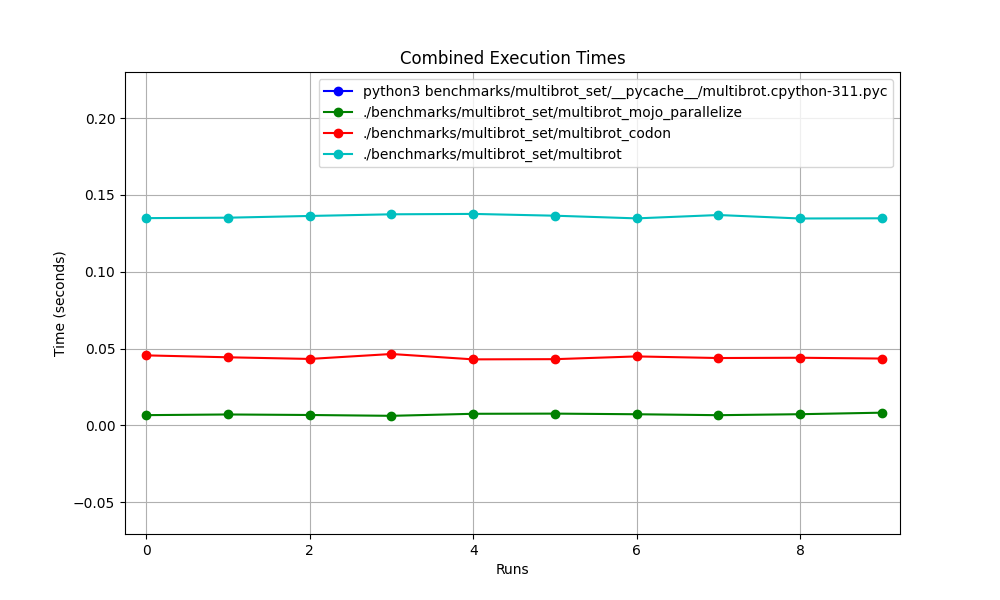
Подробно один за другим
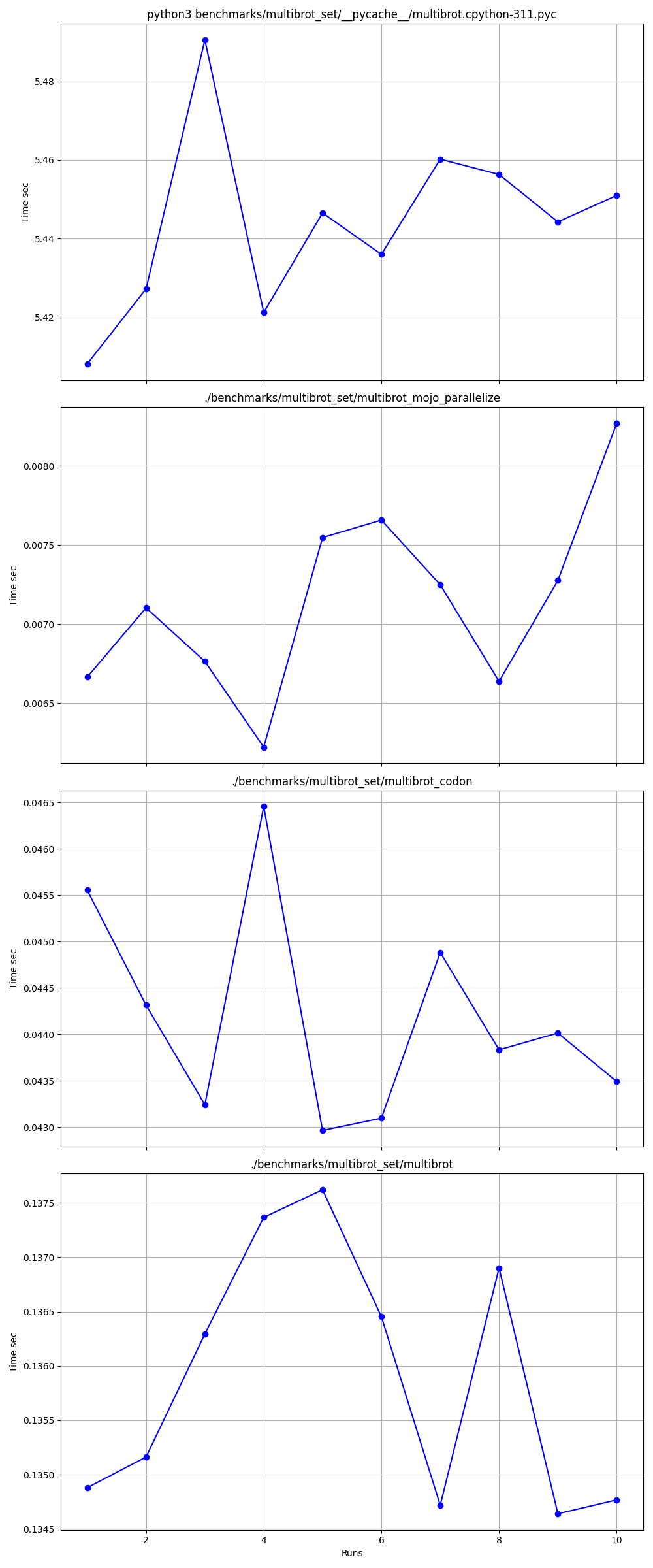
Места
Ссылки:
Мандельброт = Мультиброт с power = 2
z = z ** power + c # You can change this for different setПодушка встроенная в ImagingEffectMandelbrot
Exaloop Codon версия Мандельброта
Модульная версия Мандельброта Mojo
Комплекс Моджо
Матплотлиб Мандельброт
В информатике алгоритм двоичного поиска, также известный как полуинтервальный поиск, логарифмический поиск или двоичный поиск, представляет собой алгоритм поиска, который находит положение целевого значения в отсортированном массиве.
Давайте напишем код с помощью Python, Mojo, Swift, V, Julia, Nim, Zig.
Примечание. Для версий Python и Mojo я оставляю некоторую оптимизацию и делаю код похожим для измерения и сравнения.
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)Это первый бинарный поиск, написанный в сообществе Mojoby (@ego) и опубликованный в mojo-chat.
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 Это первая новость о Fizz, написанная в Mojo сообществом (@Ego).
Мы будем использовать алгоритм из известного справочника по книге «Введение в алгоритмы» A3.
Его известность привела к повсеместному использованию аббревиатуры « CLRS » (Кормен, Лейзерсон, Ривест, Штейн) или, в первом издании, « CLR » (Кормен, Лейзерсон, Ривест).
Глава 2 «2.3.1 Подход «разделяй и властвуй».
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06Вы можете использовать его как:
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ]) Встроенная from Sort import sort немного быстрее, чем наша реализация, но мы можем оптимизировать ее при глубоком изучении языка и, как обычно, с помощью алгоритмов =) и парадигм программирования.
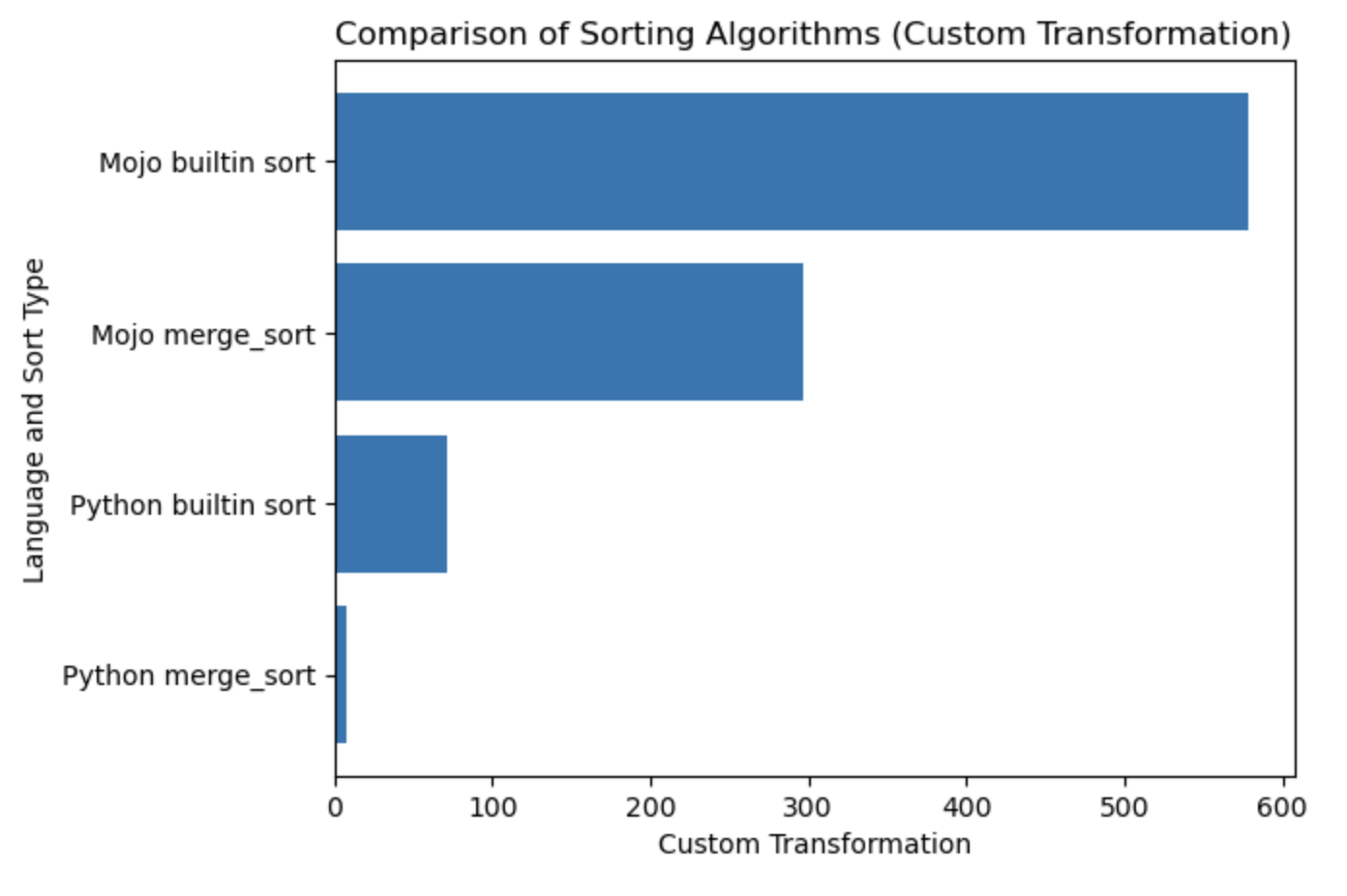
| Ланг | сек |
|---|---|
| Python merge_sort | 0,019136679 |
| Встроенная сортировка Python | 0,000199228 |
| Моджо merge_sort | 0,000011346 |
| Встроенная сортировка Mojo | 0,000002988 |
Давайте построим график для этой таблицы.
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()Примечания к сюжету: чем больше, тем лучше и быстрее.
Я настоятельно рекомендую начать отсюда HelloMojo и разобраться в параметризации [параметров] и [выражений параметров] здесь. Как в этом примере:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump () Время компиляции [Параметры]: fn concat[len1: Int, len2: Int] .
Время выполнения (Args) : fn concat(lhs: MySIMD, rhs: MySIMD) .
Синтаксис параметров PEP695 в квадратных скобках [] .
Теперь в Python:
def func ( a : _T , b : _T ) -> _T :
...Сейчас в Моджо:
def func [ T ]( a : T , b : T ) -> T :
... [Параметры] имеют имена и типы , как и обычные значения в программе Mojo, но parameters[] оцениваются во время компиляции .
Программа времени выполнения может использовать значение [parameters] — поскольку параметры разрешаются во время компиляции до того, как они потребуются программе времени выполнения, — но выражения параметров времени компиляции не могут использовать значения времени выполнения.
Self тип из PEP673
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return resultВ документации вы можете найти слово «Поля» — это атрибуты класса в Python.
Итак, вы называете их dot .
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all true Таким образом, String является всего лишь псевдонимом чего-то вроде DynamicVector[SIMD[DType.si8, 1]] .
VariadicList для деструктуризации/распаковки/доступа к аргументам from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )Это очень полезно для создания первоначальных коллекций. Мы можем написать так:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])Подробнее о функциях def и fn
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )Для строки вы можете использовать встроенный фрагмент со строковым фрагментом формата [начало: конец: шаг].
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])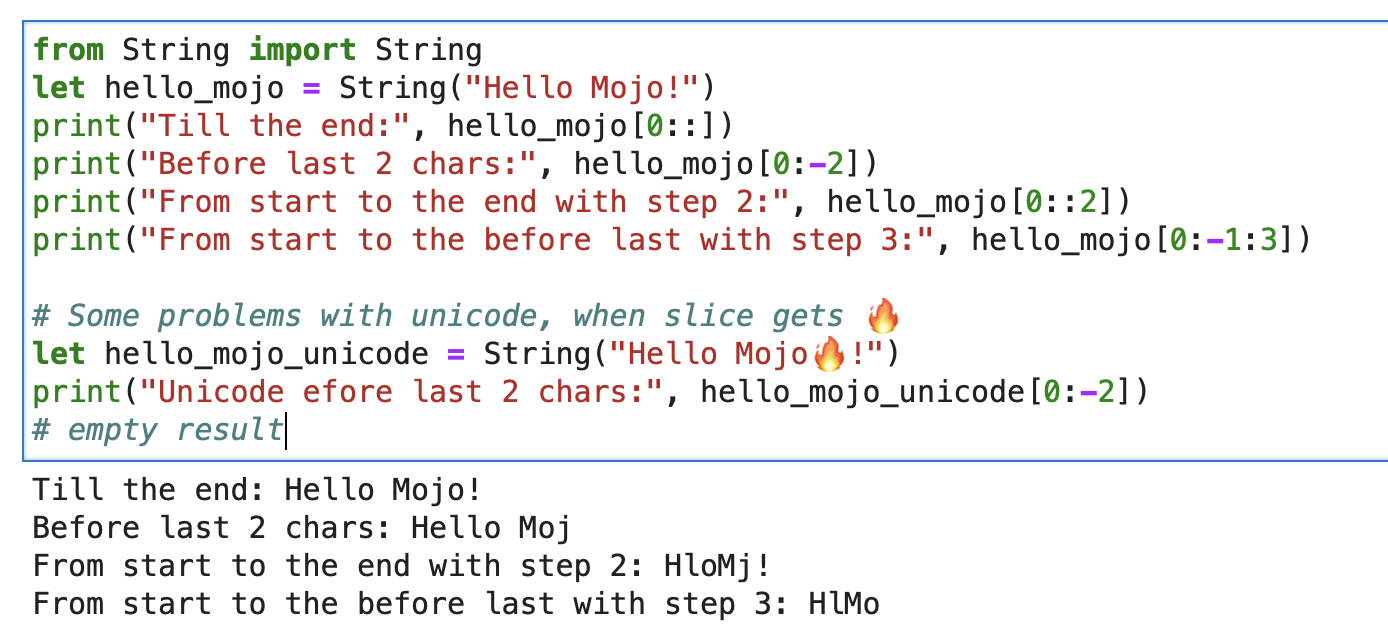
При нарезке возникает некоторая проблема с Юникодом:
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silentsВот объяснение и некоторое обсуждение.
mbstowcs — преобразовать многобайтовую строку в строку расширенных символов.
декоратор struct , он же Python @dataclass . Он автоматически сгенерирует для вас методы __init__ , __copyinit__ , __moveinit__ .
@ value
struct dataclass :
var name : String
var age : Int Обратите внимание, что декоратор @value работает только с типами, члены которых можно copyable и/или movable .
Тривиальные типы. Этот декоратор сообщает Mojo, что тип должен быть копируемым __copyinit__ и подвижным __moveinit__ . Он также сообщает Mojo предпочитать передавать значение в регистры ЦП. Позволяет structs соглашаться на передачу в register вместо передачи через memory .
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`Декораторы, обеспечивающие полный контроль над оптимизацией компилятора . Указывает компилятору всегда встраивать эту функцию при ее вызове.
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlinedЕго можно поместить во вложенные функции, которые захватывают значения времени выполнения для создания «параметрических» замыканий захвата. Это позволяет замыканиям, фиксирующим значения времени выполнения, передавать их в качестве значений параметров.
@ always_inline
@ parameter
fn test (): return Несколько примеров кастинга
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer — храните адрес с заданным DType, что позволяет вам выделять, загружать и изменять данные с удобным доступом к операциям SIMD.
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()Struct может свести к минимуму потенциальную опасность указателей за счет ограничения обнаружения.
Отличная статья в блоге Mojo Dojo о DTypePointer здесь.
Плюс его пример Matrix Struct и DTypePointer.
Указатель сохраняет адрес любого register_passable type и выделяет n их количества в heap .
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()Полная статья о Пойнтере
Плюс пример указателя и структуры
Modular Intrinsics — это своего рода серверная часть выполнения :
Mojo-> MLIR Dialects -> бэкэнды выполнения с кодом оптимизации и архитектурой.
MLIR — это инфраструктура компилятора, реализующая различные этапы преобразования и оптимизации для разных языков программирования и архитектур .
MLIR сам по себе не предоставляет напрямую функций для взаимодействия с системными вызовами операционной системы.
Это низкоуровневые интерфейсы для служб операционной системы, которые обычно обрабатываются на уровне целевого языка программирования или самой операционной системы. MLIR спроектирован так, чтобы быть независимым от языка и цели, и его основная задача — предоставить промежуточное представление для выполнения оптимизации. Для выполнения системных вызовов операционной системы в MLIR нам необходимо использовать целевой бэкэнд .
Но с помощью этих execution backends , по сути, у нас есть доступ к системным вызовам ОС. И у нас под капотом целый мир C/LLVM/Python.
Давайте так же быстро посмотрим на это на практике:
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 ) В этом простом примере мы использовали external_call для получения переменной среды ОС с типом приведения между функциями Mojo и libc. Довольно круто, да!
У меня много идей на эту тему и я с нетерпением жду возможности их реализовать в ближайшее время. Действия могут привести к потрясающим результатам =)
Давайте сделаем что-нибудь интересное — вызовем libc function .
Функция имеет этот интерфейс int gethostname (char *name, size_t size) .
Для этого мы можем использовать вспомогательную функцию external_call из модуля Intrinsics или написать собственный MLIR.
Давайте перейдем к коду:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]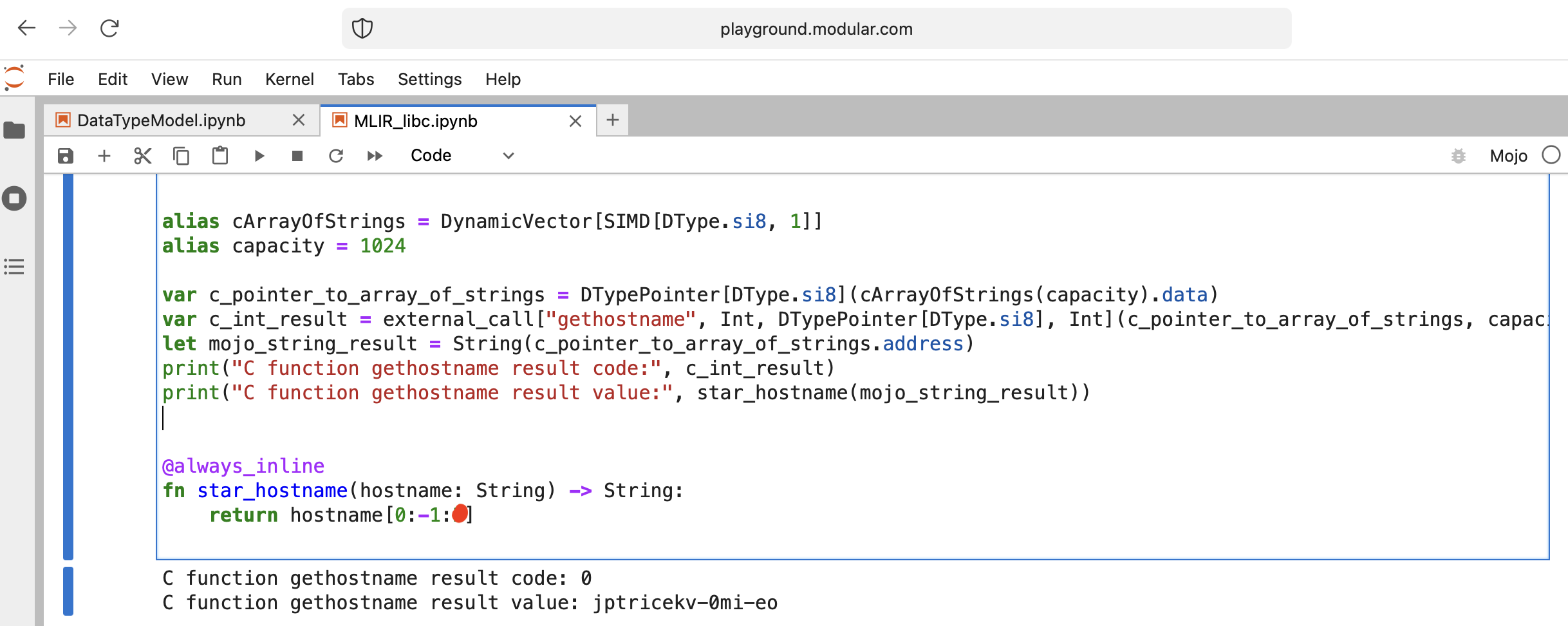
Давайте сделаем кое-что для Интернета с помощью Mojo. У нас нет доступа в Интернет на сайте player.modular.com, но мы можем воровать и делать некоторые интересные вещи, такие как TCP, на одной машине.
Давайте напишем первый TCP-клиент-серверный код в Mojo с PythonInterface.
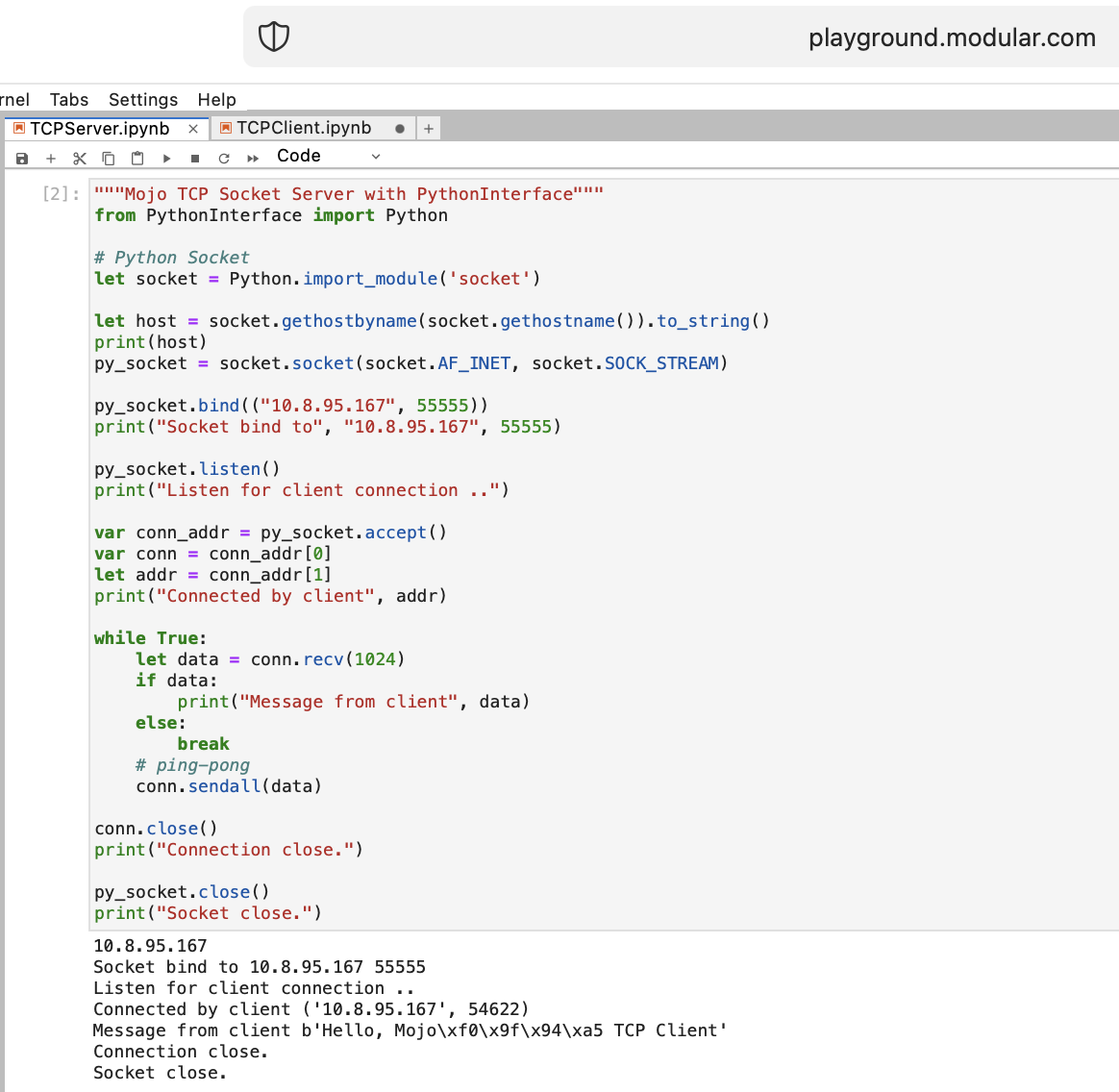
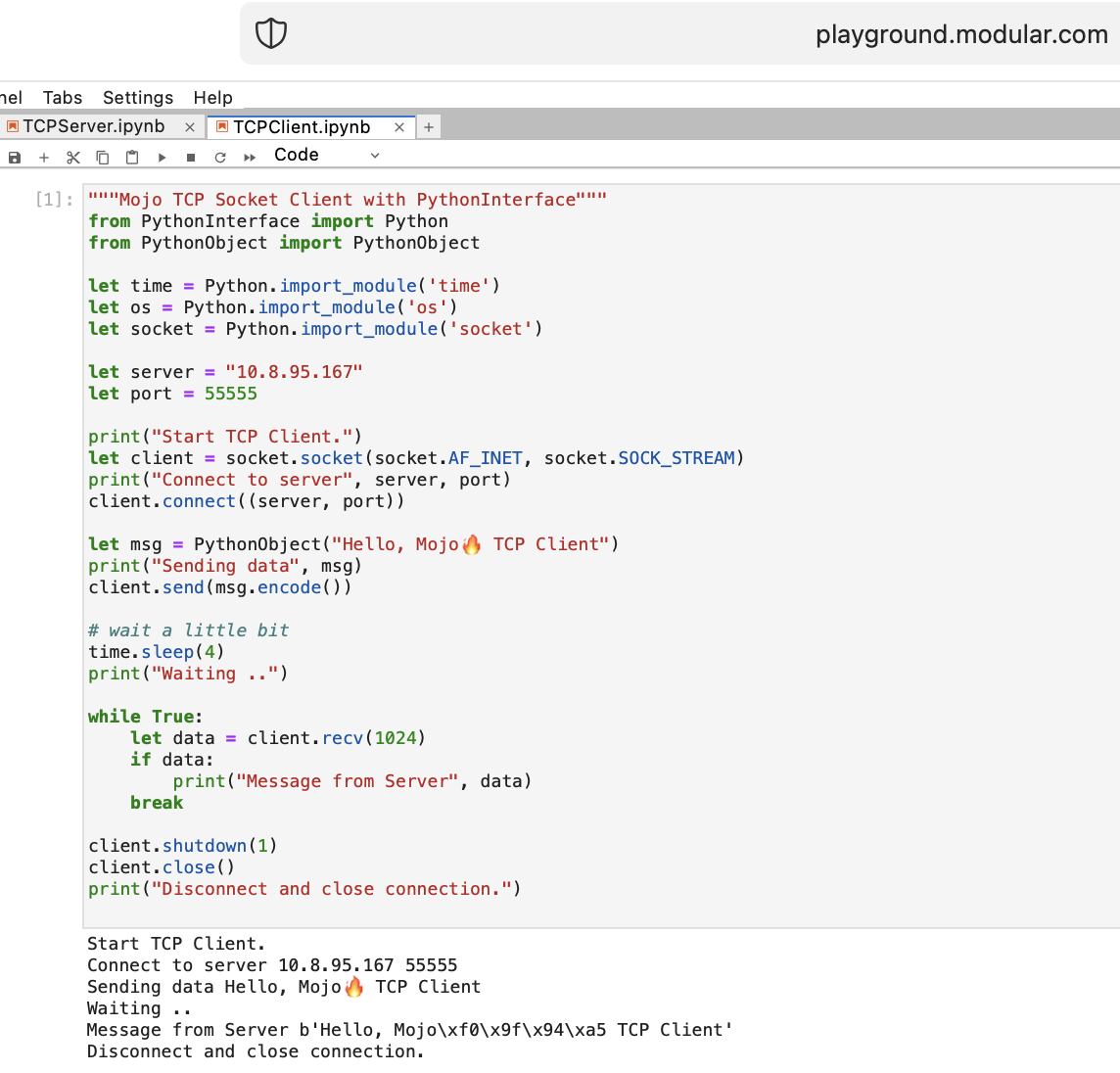
Вам следует создать две отдельные записные книжки и сначала запустить TCPSocketServer , а затем TCPSocketClient .
Версия этого кода на Python практически такая же, за исключением:
with синтаксисомlet назначитьa, b = (1, 2)После TCP Server в Mojo идем вперед =)
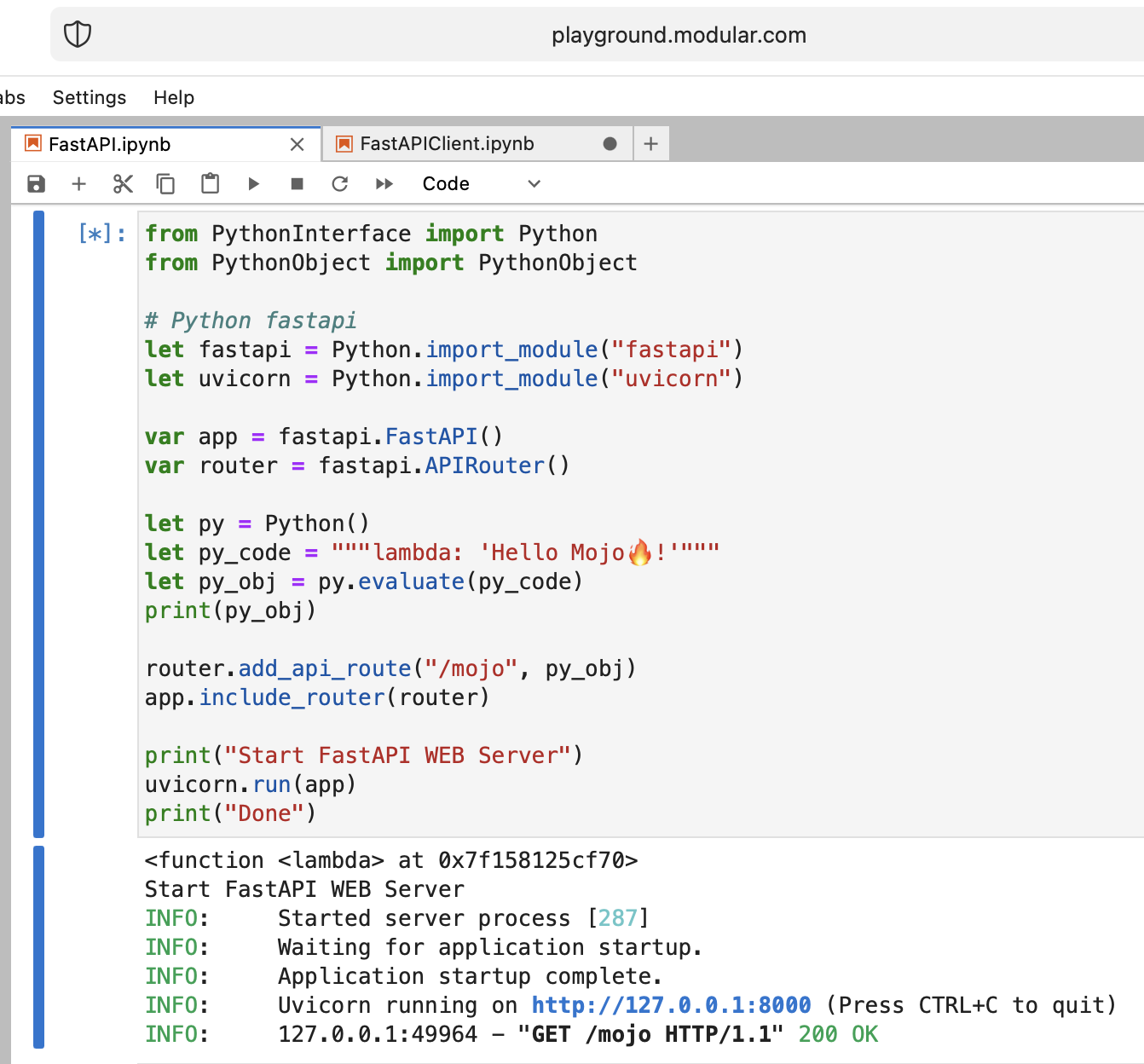
Это безумие, но давайте попробуем запустить современный веб-сервер Python FastAPI с помощью Mojo!
Нам нужно загрузить код FastAPI на игровую площадку. Итак, на вашей локальной машине сделайте
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web и загрузите web.tar.gz на игровую площадку через веб-интерфейс.
Затем нам нужно его install , просто поместив в соответствующую папку:
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
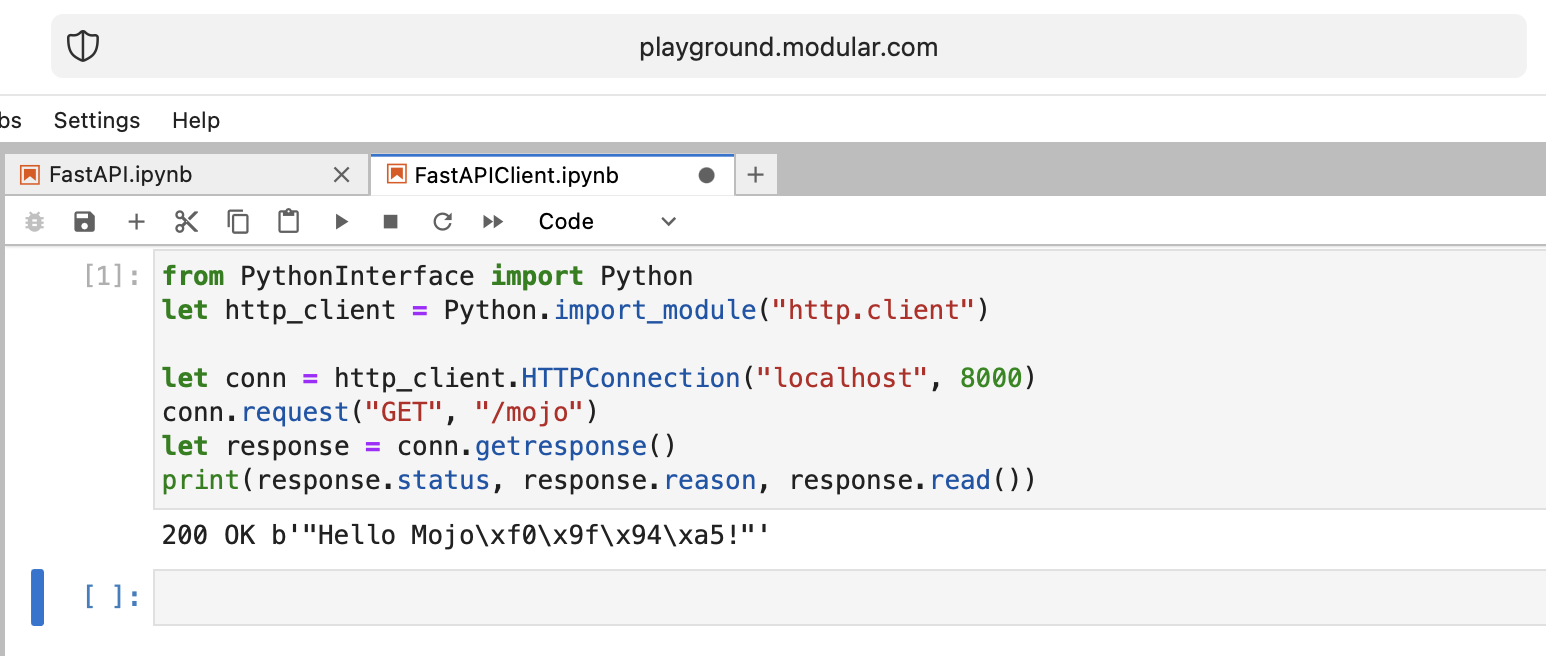
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())Как обычно, вам следует создать два отдельных блокнота и сначала запустить FastAPI , а затем FastAPIClient .
Есть много открытых вопросов, но в принципе мы достигаем цели.
Моджо молодец!
Некоторые открытые вопросы:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + yБудущее выглядит очень оптимистично!
Ссылки:
Бенчмарк Mojo против Numba, Ник Воган
Time utils от Самай Кападиа @Zalando
Подключение к вашей игровой площадке моджо из VSCode или DataSpell
от Максима Закса
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()реализация libc
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click файл в проводнике и выберите Open With > Editorselect all и copy.ipynbGithub отображает его правильно, а затем, если кто-то хочет опробовать код на своей игровой площадке, он может скопировать и вставить необработанный код.
Это мое личное мнение, поэтому не судите меня слишком строго.
Я не могу сказать, что Mojo — простой для изучения язык программирования, как, например, Python.
Это требует большого понимания, терпения и опыта работы с любыми другими языками программирования.
Если вы захотите построить что-то нетривиальное, это будет сложно, но весело!
Прошло две недели с тех пор, как я отправился в это путешествие , и я рад сообщить, что теперь я хорошо познакомился с Моджо.
На моих глазах начали раскрываться тонкости его структуры и синтаксиса , и я наполнился новым пониманием .
Я с гордостью могу сообщить, что теперь я могу уверенно писать код на этом языке, что позволяет мне воплощать в жизнь самые разнообразные идеи .
Mojo — язык программирования Modular Inc. Почему Mojo мы обсуждали здесь. О компании мы знаем меньше, но у нее очень крутое название Modular , на которое можно ссылаться:
«Другими словами: Mojo — это не волшебство, оно модульное».
Все о вычислениях, программировании, искусственном интеллекте и машинном обучении. Очень хорошее доменное имя, которое точно описывает смысл Компании.
Есть несколько дополнительных материалов об истории бренда Modular и о том, как помочь Modular очеловечить ИИ через бренд.
Сегодня я хотел бы рассказать историю о проблеме Python Enum. Как инженеры-программисты, мы часто встречаем это в Интернете. Предположим, у нас есть схема базы данных (PostgreSQL) с enum статуса:
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);В коде Python нам нужны имена и значения в виде строк (предположим, мы используем GraphQL с некоторым типом ENUM для нашей клиентской части), и нам нужно поддерживать их порядок и иметь возможность сравнивать эти перечисления:
order2.status > order1.status > 'FIRST'
Так что это проблема для большинства распространенных языков =) но мы можем использовать little-known функцию Python и переопределить метод класса перечисления: __new__ .
MALE -> 1 , FEMALE -> 2 , как это делает PostgreSQL.len ! import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME Конец истории. и используйте эту информацию о Python ENUM для хорошего программирования!


