q transformer
0.3.0
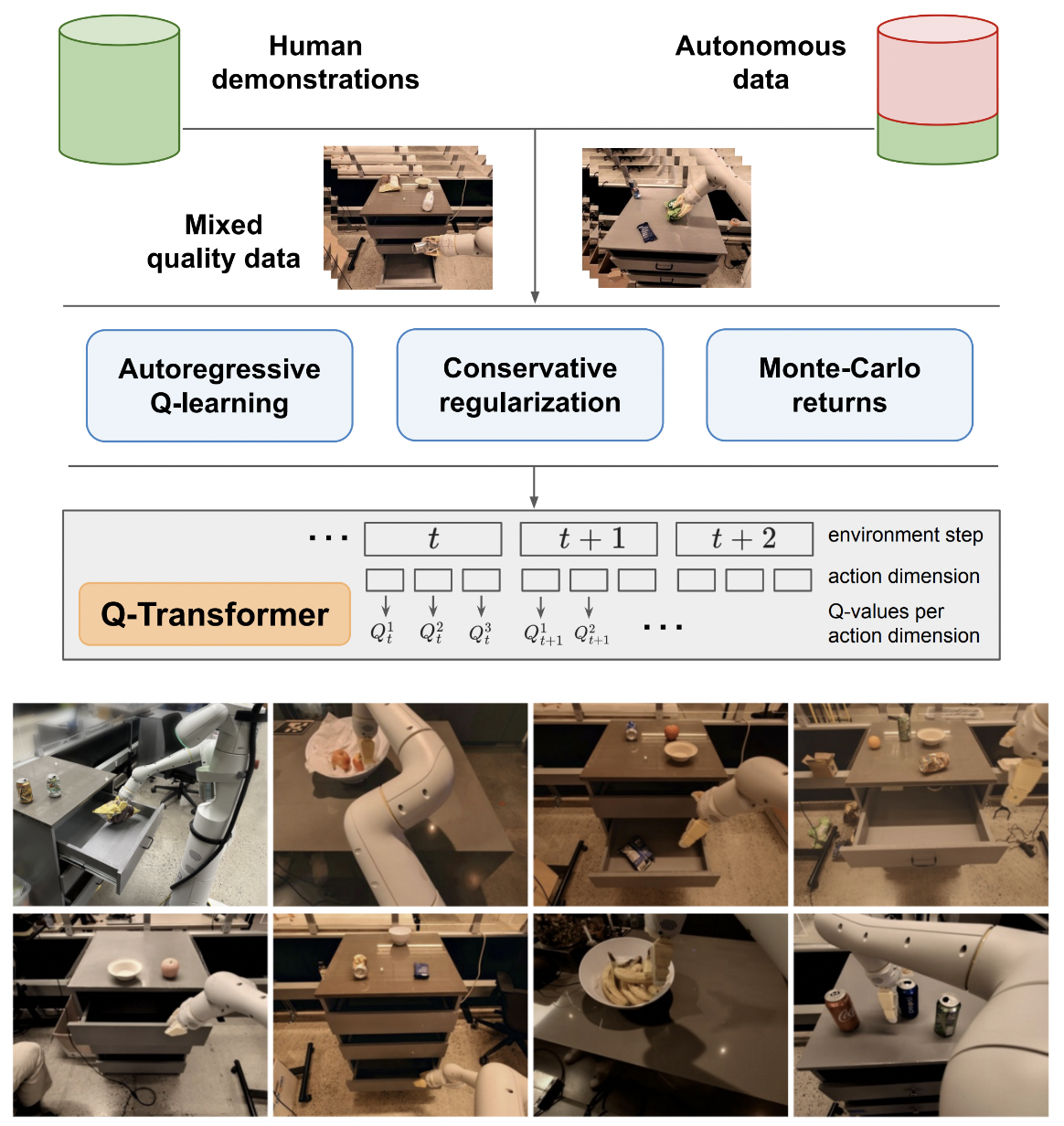
Реализация Q-трансформатора, масштабируемого автономного обучения с подкреплением с помощью авторегрессионных Q-функций, из Google Deepmind
Я буду придерживаться логики Q-обучения для одного действия только для окончательного сравнения с предлагаемым авторегрессионным Q-обучением для нескольких действий. А также служить образованием для себя и публики.
Формулировка авторегрессионного Q-обучения была воспроизведена Kotb et al.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )первый рабочий путь к поддержке единого действия
предложить безнормативный вариант maxvit, как это сделано в погодной модели SOTA metnet3
добавить дополнительную архитектуру глубоких дуэлей
добавить n-этапное обучение Q
построить консервативную регуляризацию
составить основное предложение на бумаге (авторегрессия дискретных действий до последнего действия, вознаграждение дается только за последнее)
импровизируйте вариант головы декодера, вместо объединения предыдущих действий на этапе кадры + изученные токены. другими словами, используйте классический кодер-декодер
переделать максвит с осевыми поворотными закладными + сигмовидный литник, чтобы ничего не обслуживать. включите Flash-внимание для maxvit с этим изменением
создайте простой класс создателя набора данных, принимая во внимание среду и модель и возвращая папку, которая может быть принята ReplayDataset
ReplayDataset , который принимает папку правильно обрабатывать несколько инструкций
показать простой сквозной пример в том же стиле, что и все остальные репозитории.
не обрабатывать никаких инструкций, использовать нулевой кондиционер в библиотеке CFG
кэш kv для декодирования действий
для исследования разрешить точную рандомизацию подмножества действий, а не всех действий сразу
проконсультируйтесь с экспертами по RL и выясните, есть ли какие-нибудь новые пути решения проблемы бредовой предвзятости.
выяснить, можно ли тренироваться со случайным порядком действий — порядок можно отправить как условие, которое объединяется или суммируется перед слоями внимания
простая функция поиска луча для оптимальных действий
импровизировать перекрестное внимание к прошлым действиям и состояниям временного шага, мода Transformer-xl (с выпадением структурированной памяти)
посмотрите, применима ли основная идея этой статьи к языковым моделям здесь
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

