perfusion pytorch
0.1.23
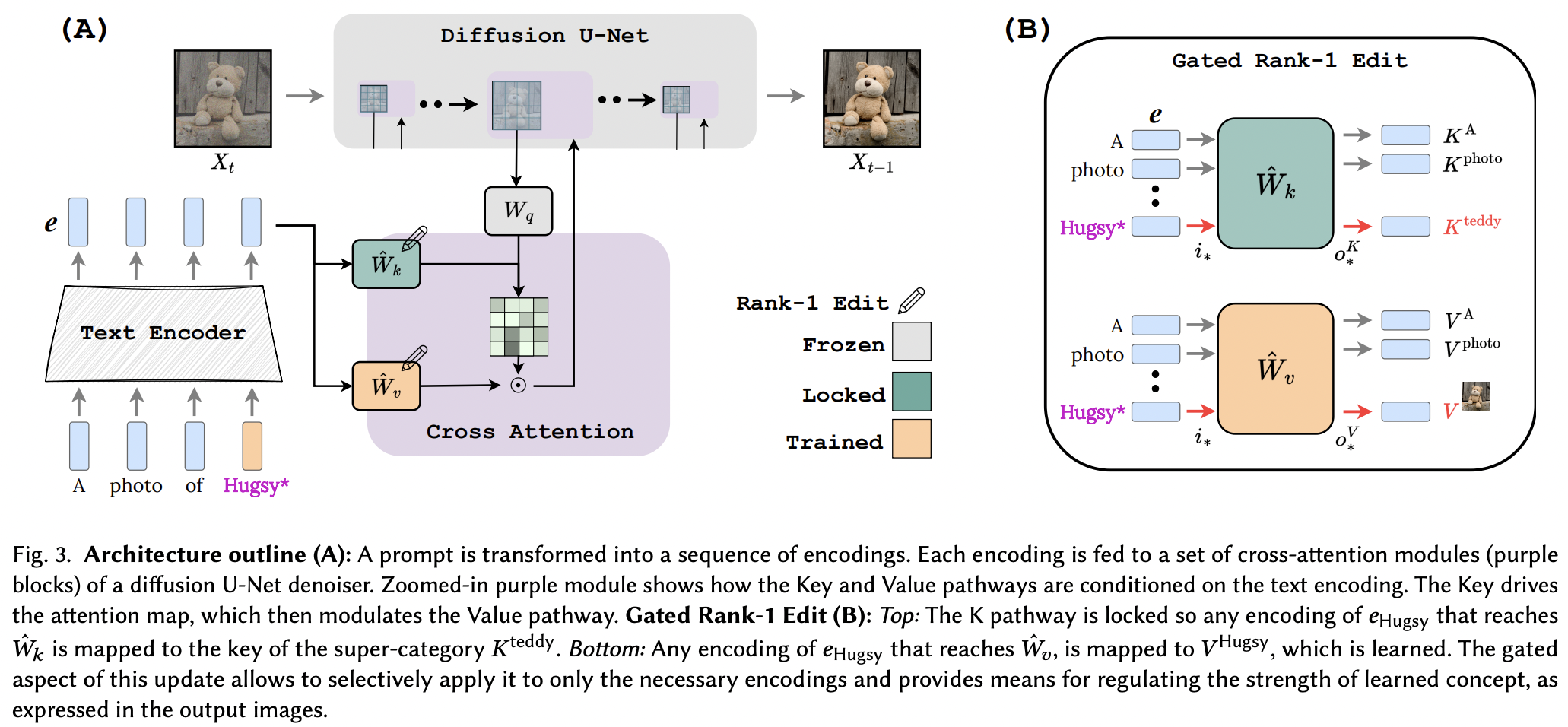
Реализация редактирования первого ранга с блокировкой клавиш. Страница проекта
Преимуществом этой статьи является чрезвычайно низкий уровень дополнительных параметров на каждую добавленную концепцию, вплоть до 100 КБ.
Кажется, они успешно применили технику редактирования ранга 1 из статьи по редактированию памяти для LLM, с некоторыми улучшениями. Они также определили, что ключи определяют «где» новой концепции, а значения определяют «что», и предлагают блокировку локального/глобального ключа для концепции суперкласса (при изучении значений).
Для исследователей, если эта статья будет проверена, инструменты в этом репозитории должны работать для любой другой сети преобразования текста <insert modality> использующей кондиционирования перекрестного внимания. Просто мысль
StabilityAI за щедрую спонсорскую поддержку, а также другим моим спонсорам
Йоаду Тевелу за многочисленные проверки кода и разъясняющие электронные письма.
Брэду Видлеру за предварительный расчет ковариационной матрицы для CLIP, используемого в Stable Diffusion 1.5!
Всем специалистам по сопровождению OpenClip за их модели SOTA с открытым исходным кодом для контрастного обучения «текст-изображение».
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) Репозиторий также содержит EmbeddingWrapper , который упрощает обучение новой концепции (и для возможного вывода из нескольких концепций).
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask Если вы можете идентифицировать экземпляр CLIP в экземпляре стабильного распространения, вы также можете передать его непосредственно в OpenClipEmbedWrapper чтобы получить все необходимое для слоев перекрестного внимания.
бывший.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) подключиться к SD 1.5, начиная с Dreambooth-SD от xiao
показать пример в readme для вывода с несколькими концепциями
автоматически определять, где находятся проекции ключей и значений, если не указано для функции make_key_value_proj_rank1_edit_modules_
Оболочка встраивания должна позаботиться о замене идентификатором токена суперкласса и вернуть встраивание суперкласса.
просмотрите несколько концепций - благодаря Yoad
предложить функцию, которая вызывает перекрестное внимание
обрабатывать несколько понятий в одной подсказке при выводе - суммирование сигмовидного члена + выходные данные
предложить способ объединить отдельно изученные концепции из нескольких Rank1EditModule в одну для вывода
Rank1EditModule s добавить нулевую маскировку концепции, предложенной в статье
позаботьтесь о функции, которая принимает набор данных и текстовый кодировщик и предварительно вычисляет ковариационную матрицу, необходимую для обновления ранга 1
вместо того, чтобы заставлять исследователя беспокоиться о разных скоростях обучения, предложите трюк с дробным градиентом из другой статьи (чтобы изучить внедрение концепции)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

