rtdl revisiting models
1.0.0
Важный
Ознакомьтесь с новой табличной моделью DL: TabM
арXiv? Пакет Python Другие табличные проекты DL
Это официальная реализация статьи «Пересмотр моделей глубокого обучения для табличных данных».
В одном предложении: модели, подобные MLP, по-прежнему являются хорошими базовыми моделями, а FT-Transformer — это новая мощная адаптация архитектуры Transformer для задач табличных данных.
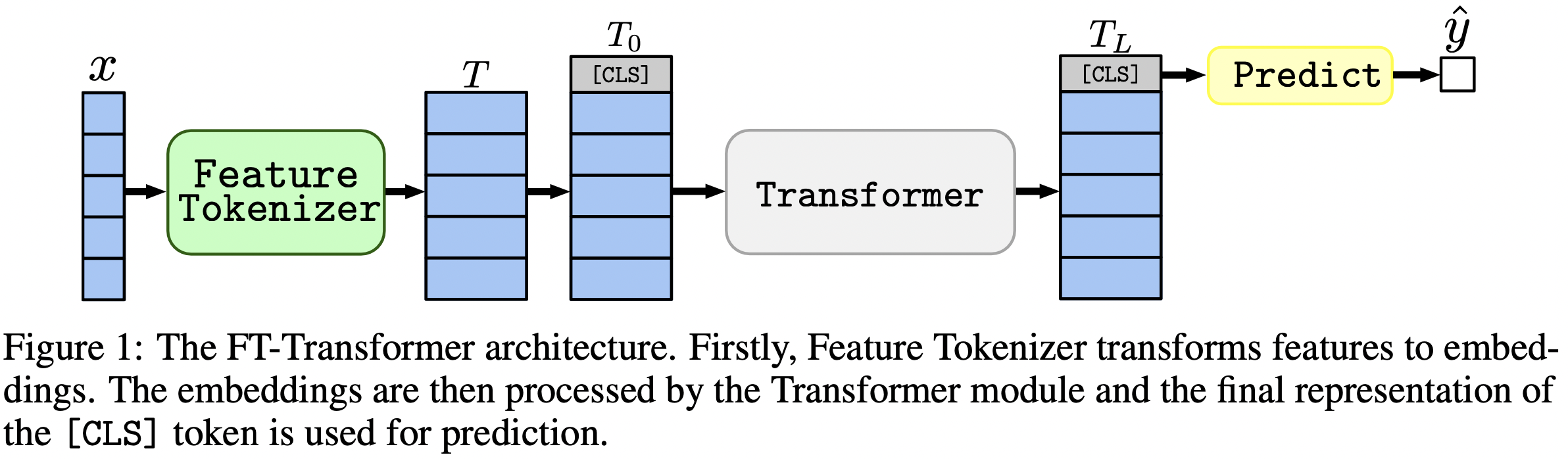
В статье основное внимание уделяется архитектурам для решения задач табличных данных. Результаты:
Пакет Python в каталоге package/ — это рекомендуемый способ использования статьи на практике и в будущей работе.
Остальная часть документа :
Каталог output/ содержит многочисленные результаты и (настроенные) гиперпараметры для различных моделей и наборов данных, используемых в статье.
Например, давайте рассмотрим метрики модели MLP. Сначала загрузим отчеты (файлы stats.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])Теперь для каждого набора данных давайте посчитаем средний балл теста по всем случайным начальным значениям:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Результат точно соответствует Таблице 2 из статьи:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
Вышеупомянутый подход также можно использовать для исследования гиперпараметров, чтобы получить представление о типичных значениях гиперпараметров для различных алгоритмов. Например, вот как можно вычислить медианную настроенную скорость обучения для модели MLP:
Примечание
Для некоторых алгоритмов (например, MLP) более поздние проекты предлагают больше результатов, которые можно исследовать аналогичным образом. Например, см. этот документ о TabR.
Предупреждение
Используйте этот подход с осторожностью. При изучении значений гиперпараметров:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536Примечание
Этот раздел длинный. Используйте функцию «Структура» на GitHub в своем текстовом редакторе, чтобы получить обзор этого раздела.
Код организован следующим образом:
bin :ensemble.py выполняет ансамбльtune.py выполняет настройку гиперпараметровanalysis_gbdt_vs_nn.py запускает экспериментыcreate_synthetic_data_plots.py строит графикиlib содержит общие инструменты, используемые программами в binoutput содержат файлы конфигурации (входные данные для программ в bin ) и результаты (метрики, настроенные конфигурации и т. д.)package содержит пакет Python для этой статьи Установить Конду
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsЭта среда нужна только для экспериментов с TabNet. Во всех остальных случаях используйте среду PyTorch.
Инструкции такие же, как и для среды PyTorch (включая установку PyTorch!), но:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt выполните следующие действия:pip install tensorflow-gpu==1.14tensorboard в requirements.txtЛИЦЕНЗИЯ : загружая наш набор данных, вы принимаете лицензии на все его компоненты. Мы не налагаем никаких новых ограничений в дополнение к этим лицензиям. Список источников вы можете найти в разделе «Библиотека» нашей статьи.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz В этом разделе представлены только конкретные команды с небольшим количеством комментариев. После завершения руководства мы рекомендуем просмотреть следующий раздел, чтобы лучше понять, как работать с репозиторием. Это также поможет лучше понять учебник.
В этом уроке мы воспроизведем результаты для MLP в наборе данных California Housing. Мы рассмотрим:
Заметим, что шансы получить точно такие же результаты довольно низкие, однако они не должны сильно отличаться от наших. Прежде чем что-либо запускать, перейдите в корень репозитория и явно установите CUDA_VISIBLE_DEVICES (если вы планируете использовать GPU):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0Прежде чем начать, давайте проверим, что среда настроена успешно. Следующие команды должны обучать один MLP набору данных о жилье в Калифорнии:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml Результат должен находиться в каталоге draft/check_environment . На данный момент содержание результата не важно.
Наша конфигурация для настройки MLP в наборе данных California Housing находится по адресу output/california_housing/mlp/tuning/0.toml . Для того, чтобы воспроизвести настройку, скопируйте наш конфиг и запустите настройку:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml Результат вашей настройки будет находиться по адресу output/california_housing/mlp/tuning/reproduced , вы можете сравнить его с нашим: output/california_housing/mlp/tuning/0 . Файл best.toml содержит лучшую конфигурацию, которую мы оценим в следующем разделе.
Теперь нам нужно оценить настроенную конфигурацию с 15 различными случайными начальными числами.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done Наша директория с результатами оценки находится рядом с вашей, а именно по адресу output/california_housing/mlp/tuned .
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced Ваши результаты будут расположены по адресу output/california_housing/mlp/tuned_reproduced_ensemble , вы можете сравнить их с нашими: output/california_housing/mlp/tuned_ensemble .
Используйте описанный здесь подход, чтобы обобщить результаты проведенного эксперимента (измените фильтр пути в .glob(...) соответственно: tuned -> tuned_reproduced ).
Подобные шаги можно выполнить для всех моделей и наборов данных. Процесс настройки немного отличается в случае поиска по сетке: вам придется запустить все нужные конфигурации и вручную выбрать лучшую , исходя из показателей валидации . Например, см. output/epsilon/ft_transformer .
Скрипты Python следует запускать из корня репозитория. Большинство программ ожидают, что файл конфигурации будет единственным аргументом. Результатом будет каталог с тем же именем, что и у конфигурации, но без расширения. Конфиги написаны на TOML. Списки возможных аргументов для программ не приводятся и должны быть получены из скриптов (обычно в скриптах конфиг представлен переменной args ). Если вы хотите использовать CUDA, вы должны явно установить переменную среды CUDA_VISIBLE_DEVICES . Например:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlЕсли вы собираетесь использовать CUDA постоянно, вы можете сохранить переменную среды в среде Conda:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " Опция -f ( --force ) удалит существующие результаты и запустит скрипт с нуля:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py поддерживает продолжение:
python bin/tune.py path/to/config.toml --continuestats.json и другие результаты Для всех скриптов stats.json является наиболее важной частью вывода. Содержание варьируется от программы к программе. Он может содержать:
Прогнозы для обучающих, проверочных и тестовых наборов обычно также сохраняются.
Теперь вы знаете все, что вам нужно, чтобы воспроизвести все результаты и расширить этот репозиторий для своих нужд. Учебное пособие также должно стать более понятным. Не стесняйтесь открывать проблемы и задавать вопросы.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


