video diffusion pytorch
0.7.0
этих фейерверков не существует
Текст в видео, это происходит! Официальная страница проекта
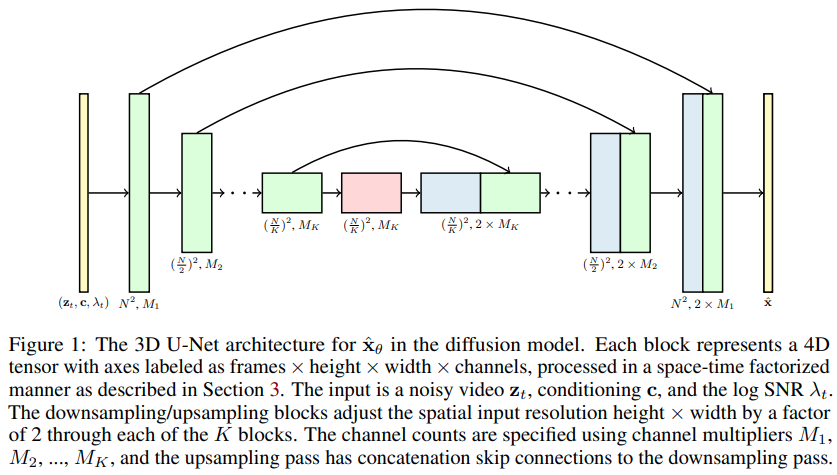
Реализация моделей распространения видео, новая статья Джонатана Хо, расширяющая DDPM до генерации видео — в Pytorch. Он использует специальную пространственно-временную сеть U-net, расширяющую генерацию от 2D-изображений до 3D-видео.
14к для сложных движущихся мнистей (сходится гораздо быстрее и лучше, чем NUWA) - wip

Вышеуказанные эксперименты возможны только благодаря ресурсам, предоставленным Stability.ai.
Любые новые разработки по синтезу текста в видео будут централизованы в Imagen-pytorch.
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)Для обработки текста они получили встраивания текста, сначала пропустив токенизированный текст через BERT-large. Тогда вам просто нужно тренировать его вот так
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)Вы также можете напрямую передавать описания видео в виде строк, если планируете использовать BERT-базу для обработки текста.
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) В этом репозитории также содержится удобный класс Trainer для обучения работе с папкой gifs . Каждая gif должна иметь правильные размеры image_size и num_frames .
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () Примеры видео (в виде файлов gif ) будут периодически сохраняться в ./results , как и параметры модели диффузии.
Одно из утверждений в статье заключается в том, что, распределяя пространственно-временное внимание, можно заставить сеть уделять внимание настоящему для одновременного обучения изображений и видео, что приводит к лучшим результатам.
Непонятно, как они этого добились, но я выдвинул предположение.
Чтобы привлечь внимание к настоящему моменту для определенного процента образцов пакетного видео, просто передайте prob_focus_present = <prob> в методе диффузии вперед.
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()Если у вас есть лучшее представление о том, как это сделать, просто откройте вопрос на GitHub.
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

