lumiere pytorch
0.0.24
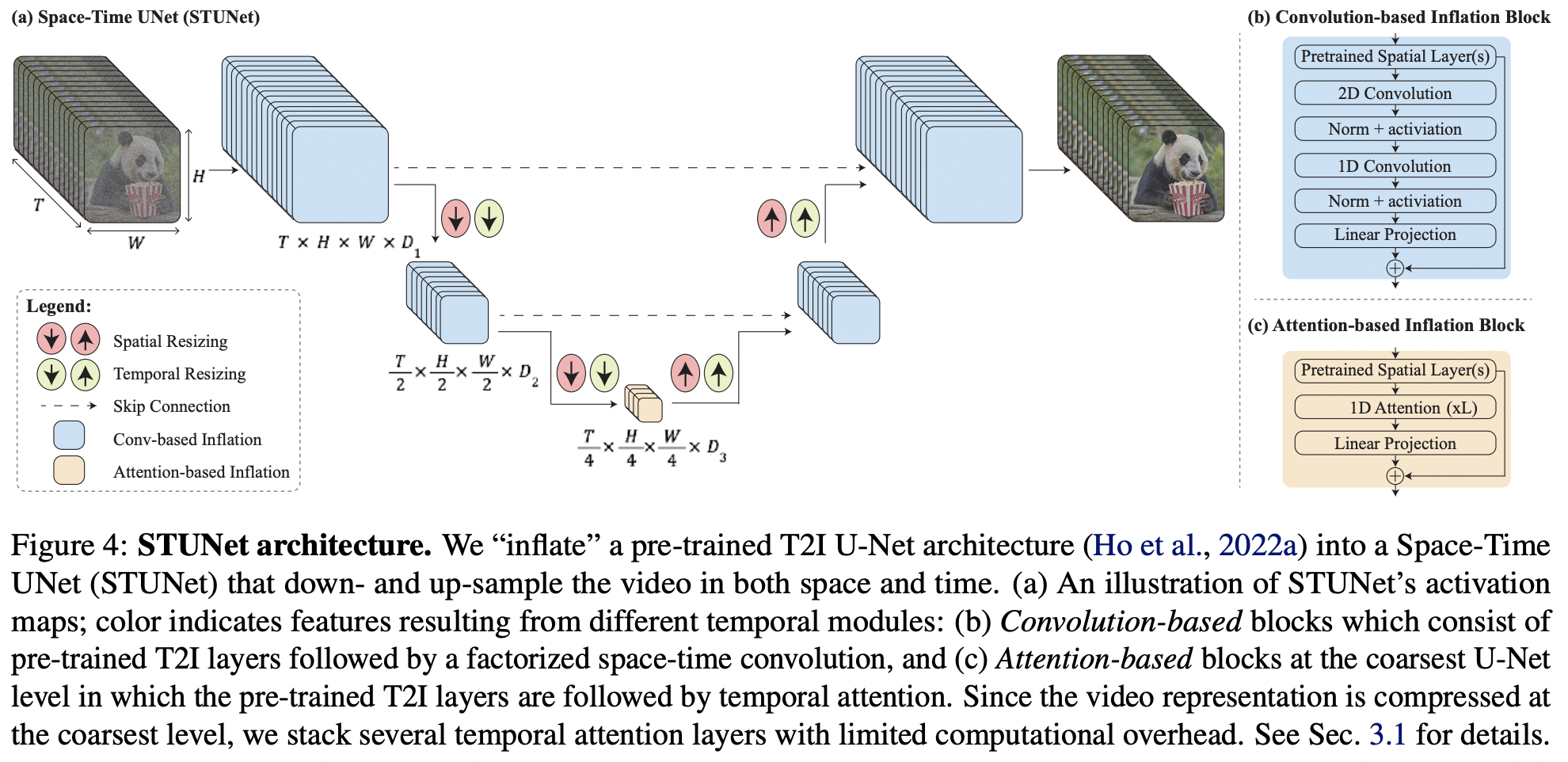
Реализация Lumiere, SOTA-генератора текста в видео от Google Deepmind, в Pytorch.
Рецензия на статью Янника
Поскольку эта статья представляет собой всего лишь несколько ключевых идей, дополняющих модель преобразования текста в изображение, мы сделаем еще один шаг вперед и расширим новую сеть Karras U-net для видео в этом репозитории.
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape добавить все временные слои
выставлять для обучения только временные параметры, все остальное заморозить
выяснить, как лучше всего справиться с временной обусловленностью после временного понижения дискретизации - вместо преобразования pytree в начале, вероятно, потребуется подключиться ко всем модулям и проверить размеры пакетов
обрабатывать средние модули, которые могут иметь форму вывода как (batch, seq, dim)
следуя выводам Теро Карраса, импровизируйте вариант из 4-х модулей с сохранением магнитуды
протестируйте на imagen-pytorch
посмотрите на мультидиффузию и посмотрите, можно ли ее превратить в какую-нибудь простую обертку
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

