glory admin
1.0.0
GloryAdmin — это фоновый фреймворк, основанный на Springboot2.1.9.RELEASE и vue-admin-template;
GloryAdmin использует управление разрешениями на основе ролей. Дерево ролей представляет собой дерево с корневым узлом «Системный администратор», а дерево разрешений состоит из нескольких деревьев подразрешений. «Системный администратор» имеет все разрешения; роли, не являющиеся системными администраторами, могут просматривать информацию текущей роли и непосредственно подчиненных ролей, но могут только добавлять, удалять и изменять информацию непосредственно подчиненных ролей (прямые подчиненные: A — прямые подчиненные). подчиненный узел B, то A должен быть дочерним узлом B).
Слава-Админ
| проект | технология |
|---|---|
| Бэкэнд-проект | пружинный сапог |
| Фронтенд-проект | Пользовательский интерфейс элемента и Vue.js |
| база данных | MySQL |
| кэш | Редис |

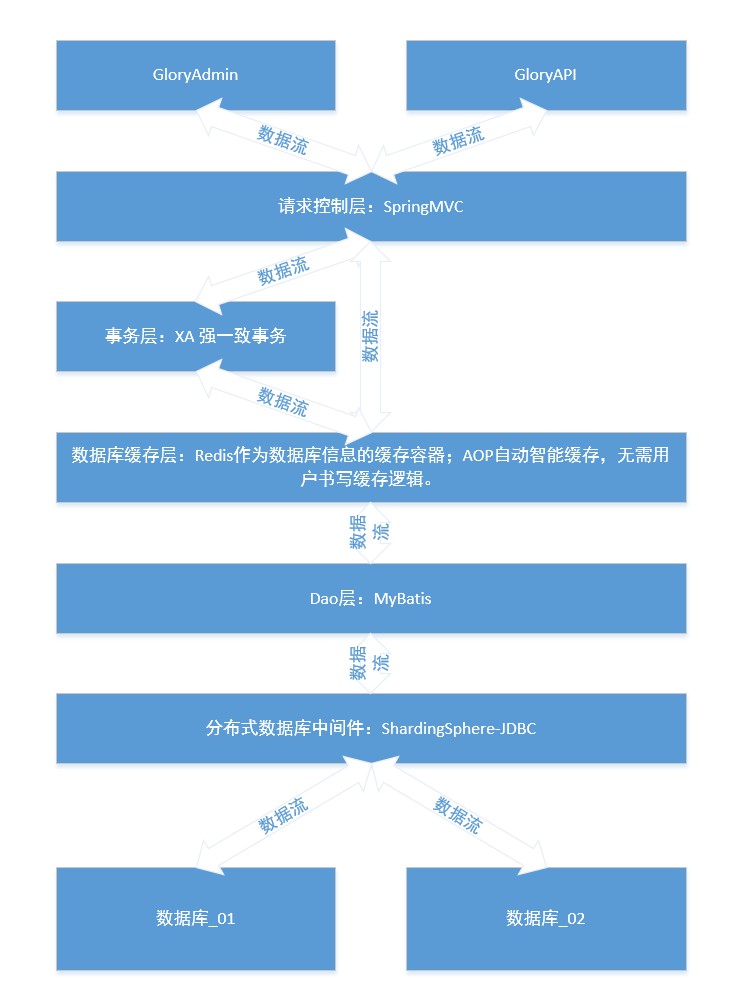
В этом проекте используется база данных mysql. Вы можете использовать сценарий базы данных для создания двух баз данных multi_module_db multi_module_db_01
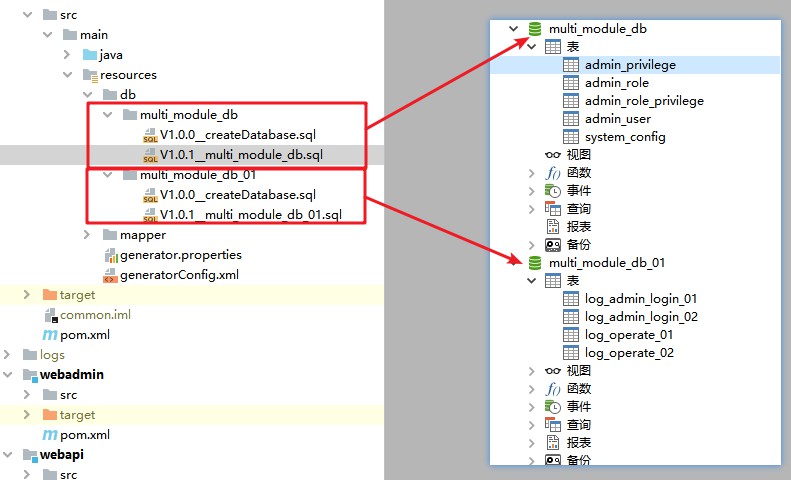
Запустите в фоновом режиме и используйте порт 28081.
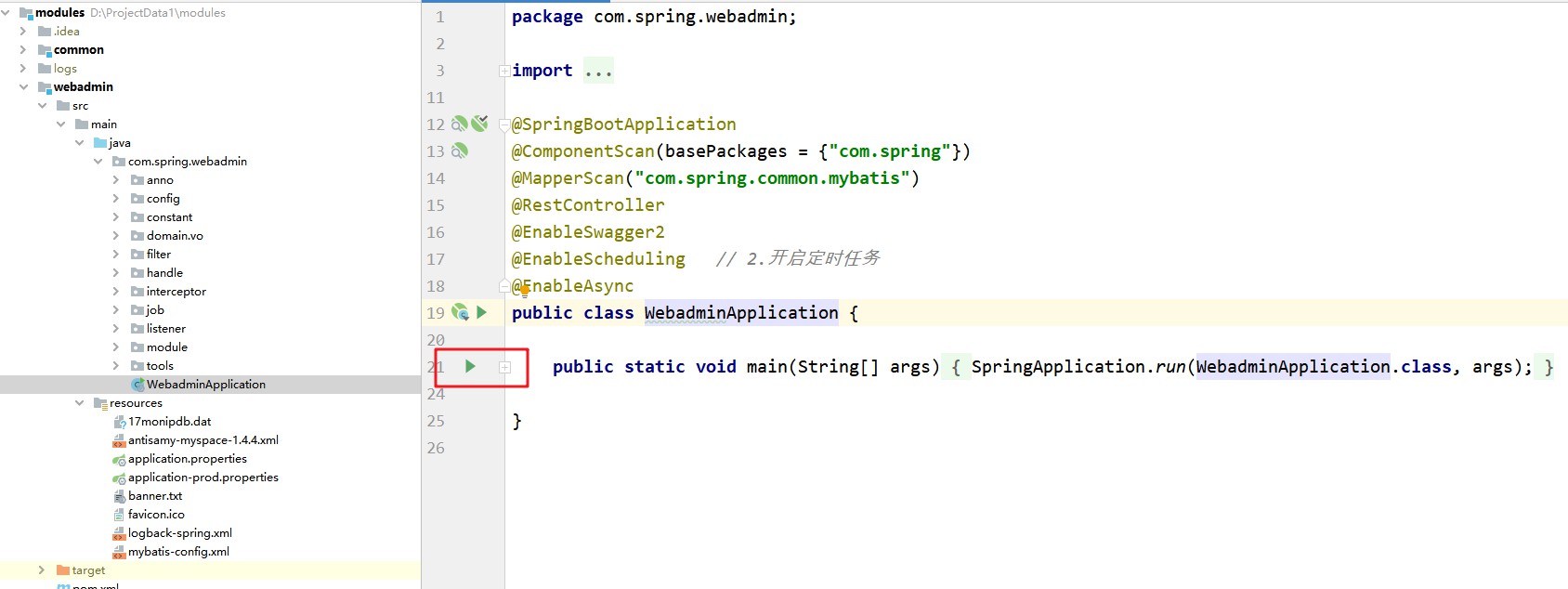
Запустите интерфейс и используйте порт 9523.
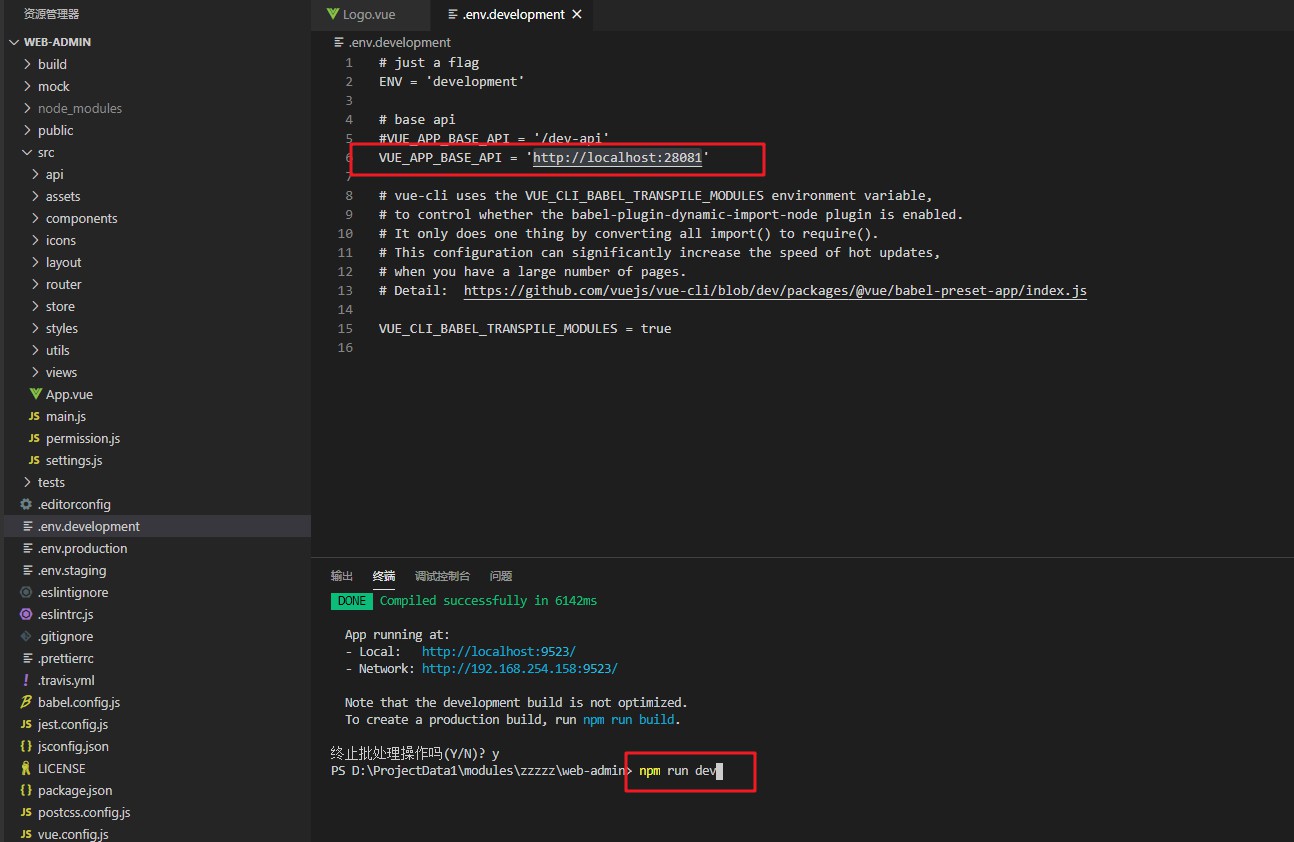
Откройте браузер и посетите http://localhost:9523 admin a123456.
Суть шардинга или шардинга заключается в нарушении закона Мура. Решение о централизованном хранении данных на одном узле данных было трудным для удовлетворения сценариев огромных объемов данных в Интернете с точки зрения производительности, доступности, а также затрат на эксплуатацию и обслуживание.
Одна база данных не может поддерживать существующие предприятия, поэтому появились подбазы данных и таблицы, а для хранения данных используются несколько баз данных. Простое понимание подбазы данных и подтаблицы заключается в том, что содержимое корзины ограничено, что влияет на эффективность поиска и емкость. Содержимое корзины разделено на N частей и помещено в разные корзины. Это устраняет ограничения емкости и повышает эффективность запросов.
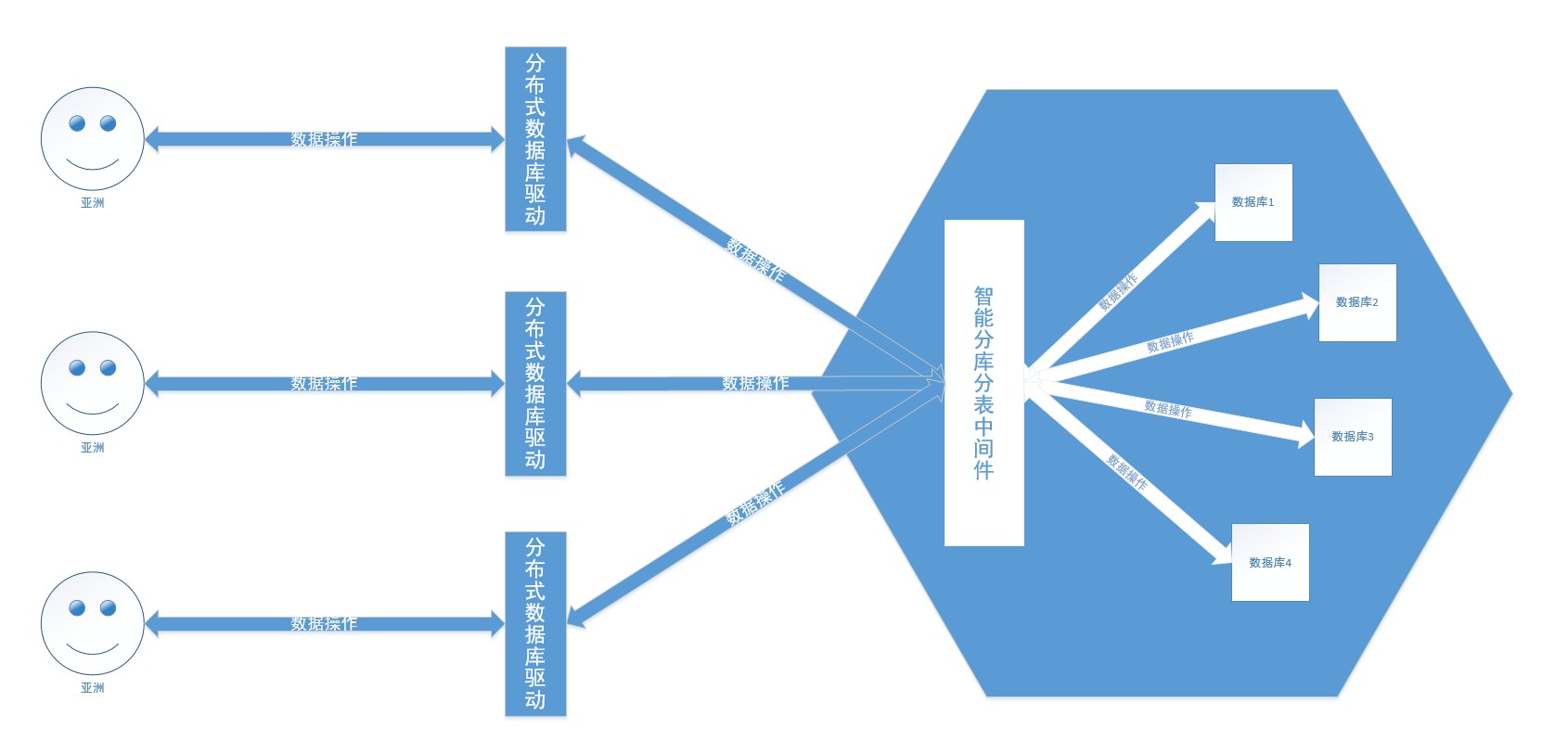
Затем давайте поговорим о распределенных базах данных. К наиболее популярным в Китае относятся TDSQL от Tencent, OceanBase от Alibaba, PolarDB, GaussDB от Huawei и т. д. По сути, они разрабатываются независимо, имеют строгую согласованность и высокую доступность, глобальную архитектуру развертывания, распределенное неограниченное горизонтальное расширение, высокую производительность, сотни миллиардов записей, а также транзакции между строками и таблицами с сотнями ТБ данных (например, для Родина) . Распределенная база данных скрывает стратегию сегментирования базы данных и таблиц, интеллектуально распределяет данные по базам данных и таблицам и использует их так же, как при работе с базой данных.
Поскольку операции с памятью и операции с диском совершенно не одного порядка, для крупных проектов требуется буферный уровень типа памяти для баз данных дискового типа для кэширования дисковых данных в памяти. Уровень кэширования данных используется для кэширования данных всего уровня данных для ускорения доступа к сайту. В этом проекте используется технология AOP и база данных Redis в памяти в качестве уровня кэша данных. Подробности см. в коде com/spring/common/aop/CacheDaoAspect.java.
В этом проекте используется шардинг JDBC для обработки базы данных и таблиц базы данных. Разделите данные самостоятельно в соответствии с бизнес-сценариями.
Обычно проекты имеют только одну базу данных, а в Китае в качестве пула подключений к базе данных чаще используется друид Alibaba Cloud. В этом проекте используются MySQL, Druid и Sharding JDBC. Принцип сегментирования данных заключается в поддержании в программе нескольких пулов подключений к базе данных, и каждый пул подключений к базе данных соответствует базе данных. В сегментированной базе данных и сегментированных таблицах используется двухфазная обработка транзакций на основе протокола XA . Путь конфигурации com.spring.common.config.shardingJDBC
Вертикальное разделение. Метод разделения бизнеса называется вертикальным сегментированием, также известным как вертикальное разделение. Распределите таблицы по разным базам данных в зависимости от бизнеса, тем самым распределяя нагрузку на разные базы данных.
Горизонтальное разделение: оно не заботится о классификации бизнес-логики, но распределяет данные по нескольким библиотекам или таблицам в соответствии с определенными правилами через определенное поле (или несколько полей) определенной таблицы. Правила здесь и задействованный алгоритм называются алгоритмами шардинга .
( Следующее содержимое взято из документации shardingJDBC )
Соответствует PrecisionShardingAlgorithm, используемому для обработки сценария сегментирования = и IN с использованием одного ключа в качестве ключа сегментирования. Необходимо использовать со StandardShardingStrategy.
Соответствует RangeShardingAlgorithm, который используется для обработки сценариев сегментирования с использованием BETWEEN AND , > , < , >= и <= с использованием одного ключа в качестве ключа сегментирования. Необходимо использовать со StandardShardingStrategy.
Соответствует ComplexKeysShardingAlgorithm, который используется для обработки сценариев, в которых несколько ключей используются в качестве ключей сегментирования. Логика, содержащая несколько ключей сегментирования, сложна, и разработчикам приложений приходится самостоятельно справляться со сложностью. Необходимо использовать с ComplexShardingStrategy.
Соответствует HintShardingAlgorithm, используемому для обработки сценариев, в которых используется сегментирование строк Hint . Необходимо использовать с HintShardingStrategy.
Пользователь входит в систему, чтобы получить токен и сохранить его локально (adminLogin).
Пользователь отправляет токен для получения информации о пользователе и информации о разрешениях и сохраняет их в хранилище. Поскольку нажатие клавиши F5 приведет к потере хранилища, к внешнему запросу добавляется перехватчик. Если информация о пользователе и сведения о разрешениях отсутствуют, информация о пользователе и разрешения будут получены повторно (getAdminInfo).
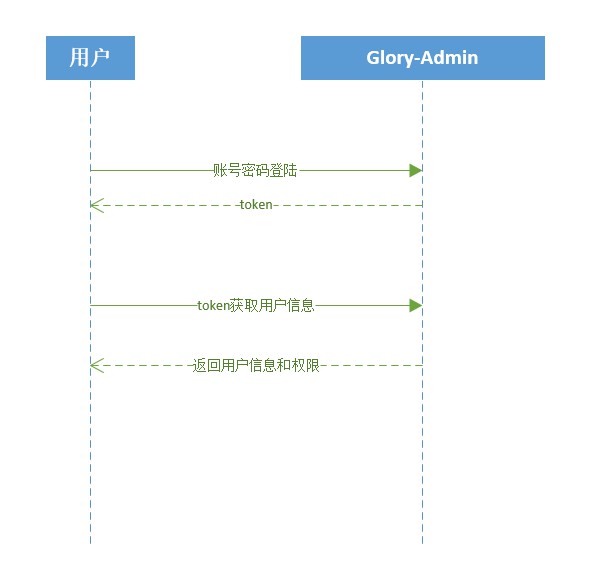
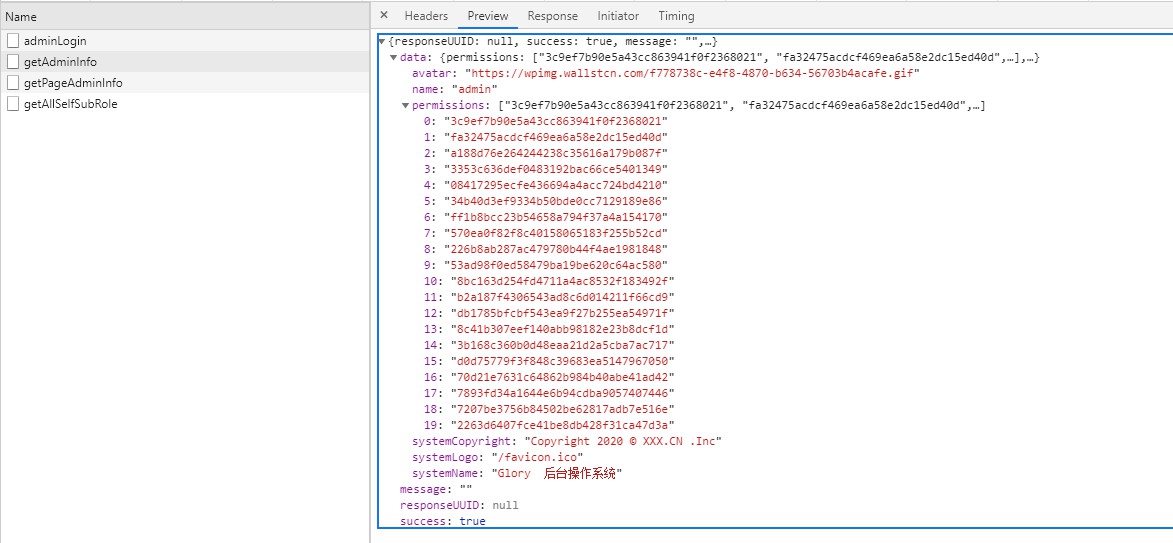
Здесь возвращаются все разрешения пользователя, а не роли. Пользователь динамически генерирует внешние маршруты.
asyncRoutes — это динамически создаваемое разрешение. Если разрешение пользователя соответствует разрешению маршрута, оно будет отображено;
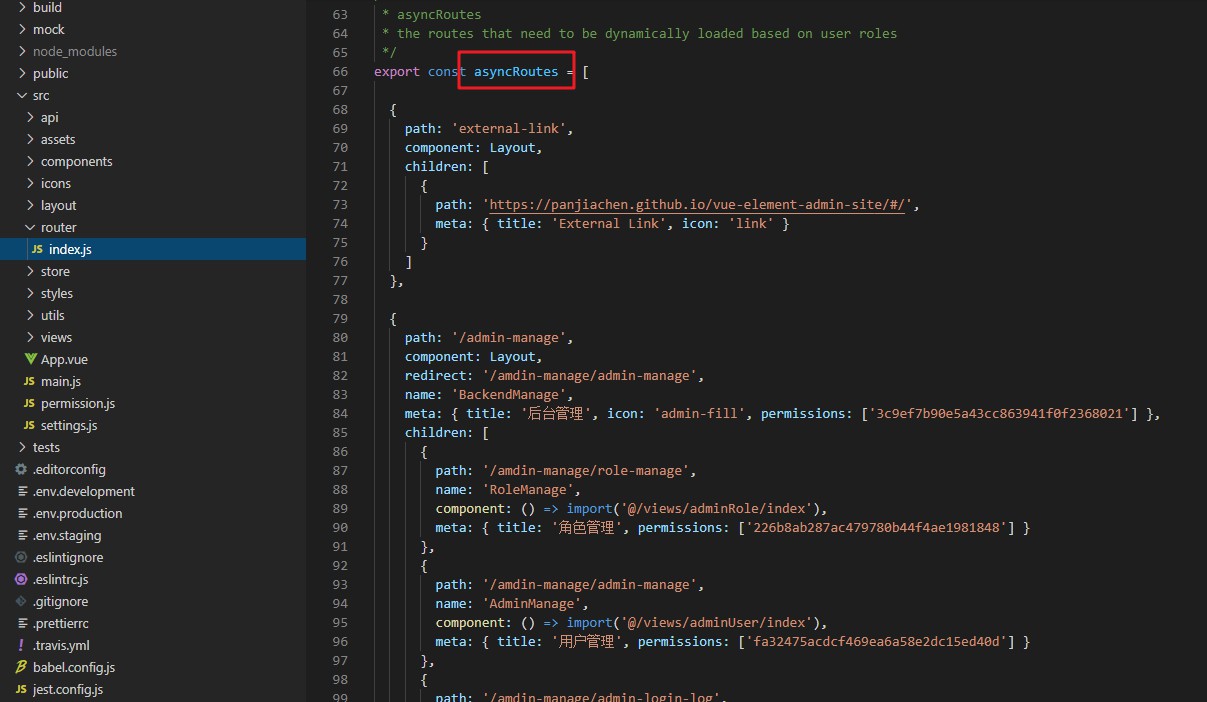
общие: операции с данными, кэширование данных, операции транзакций.
Администратор выступает только в качестве контроллера, который используется для пересылки между запросами пользователей и внутренним бизнесом. (Почему он спроектирован таким образом?) Потому что некоторым системам промежуточного программного обеспечения необходимо использовать структуру RPC для пересылки запросов, а также потому, что некоторые конфиденциальные системы презирают использование SpringMVC и выбирают vertx для независимой разработки уровня запросов.
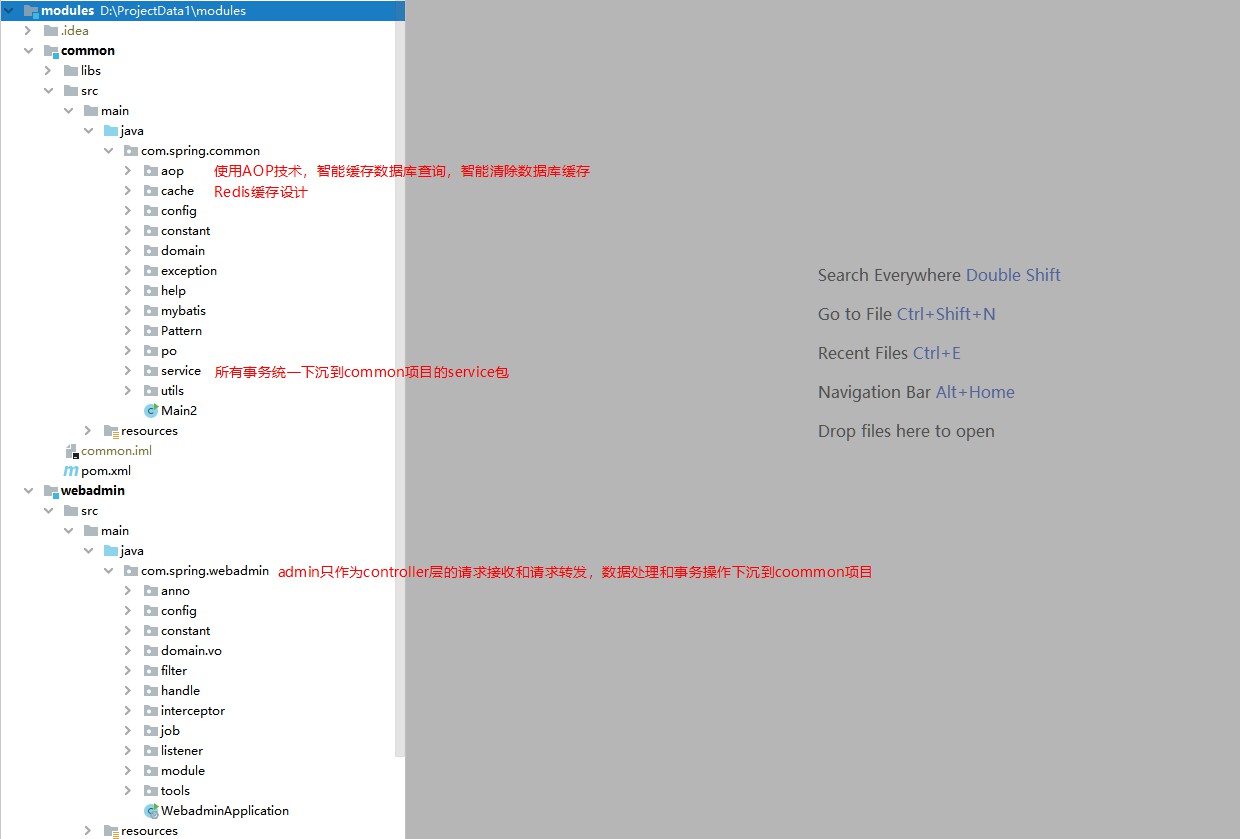
Используйте наследование Maven для управления зависимостями проекта. В модулях зависимости вводятся через управление зависимостями, а версии подпроектов наследуют модули, и при введении зависимостей указывать версии не требуется.
Глобальная обработка журналов
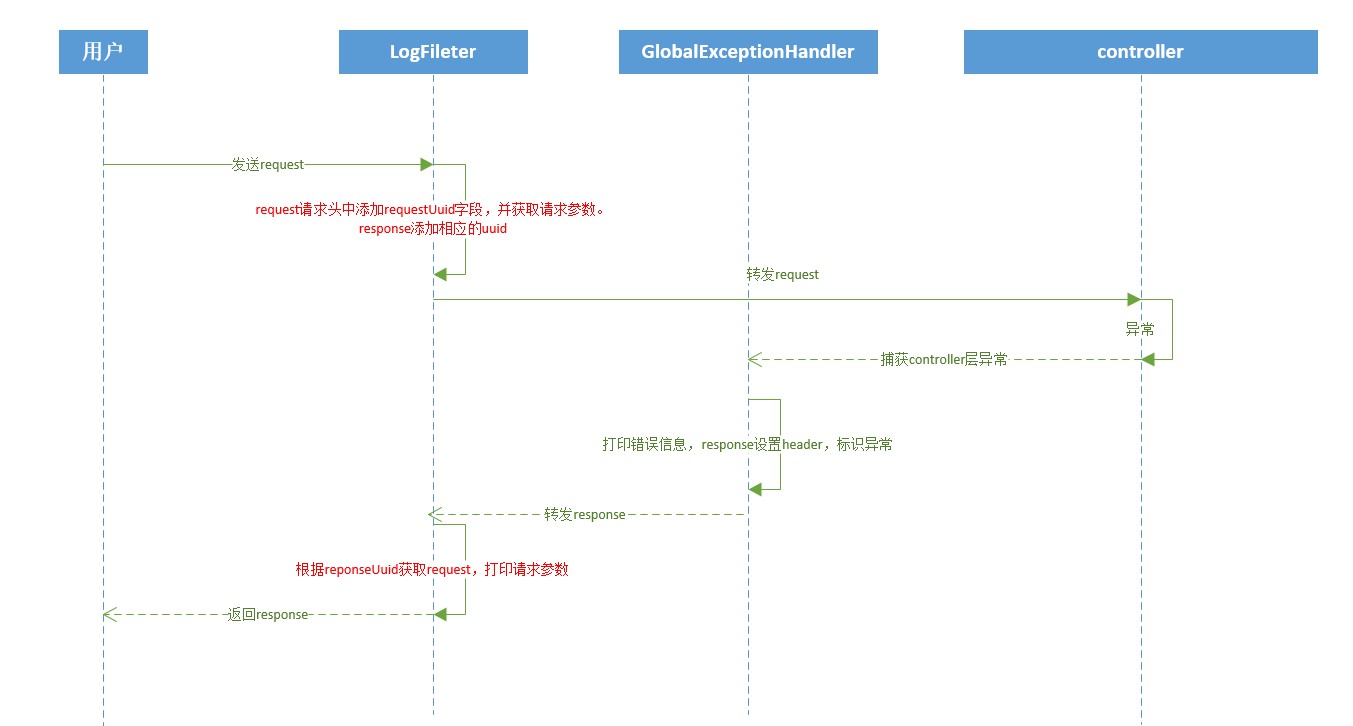
В журналах операций пользователя используются методы аннотации. Если этому методу необходимо записывать журналы операций, просто добавьте аннотацию **@OperateLog** над именем метода.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

