Репозиторий состоит из VQ-VAE, реализованного в Pytorch и обученного набору данных MNIST.
VQ-VAE следуют той же базовой концепции, что и за вариационными автододерами (VAE). VQ-VAE Используйте дискретные скрытые встраивания для вариационных автоматических кодеров , то есть каждое измерение Z (скрытый вектор) является дискретным целым целом, вместо непрерывного нормального распределения, обычно используемого при кодировании входов.
VAE состоят из 3 частей:
Что ж, вы можете спросить о различиях, которые VQ-Vaes приносят на стол. Давайте перечислим их:
Многие важные объекты реального мира дискретны. Например, на изображениях у нас могут быть такие категории, как «кошка», «автомобиль» и т. Д., И может не иметь смысла интерполировать между этими категориями. Дискретные представления также легче моделировать.
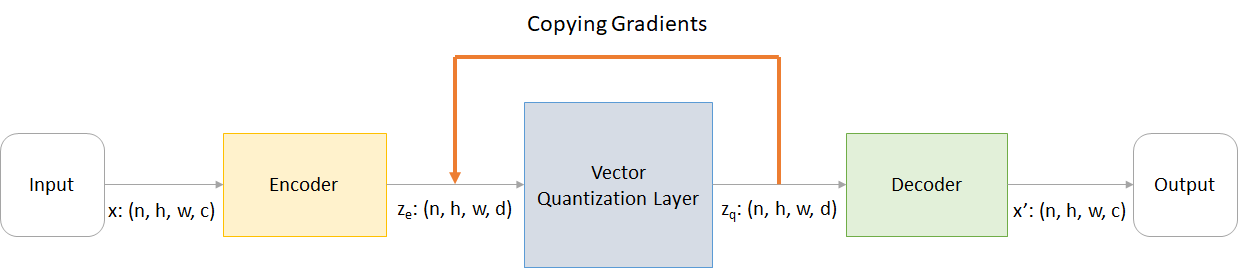
где:
n : размер партииh : высота изображенияw : ширина изображенияc : Количество каналов в входном изображенииd : количество каналов в скрытом состоянии Вот краткий обзор работы сети VQ-VAE:
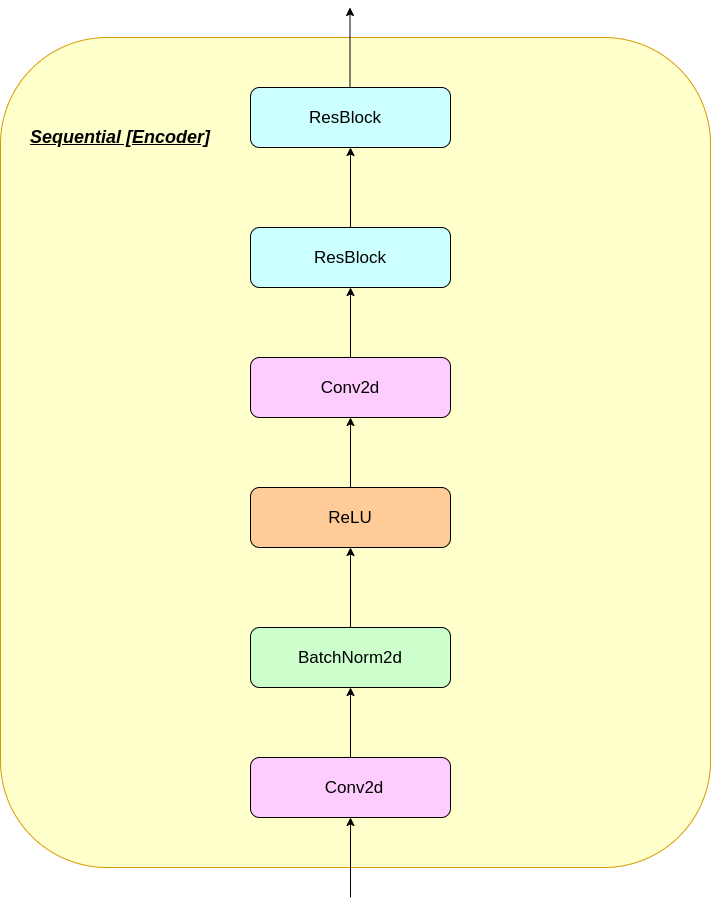
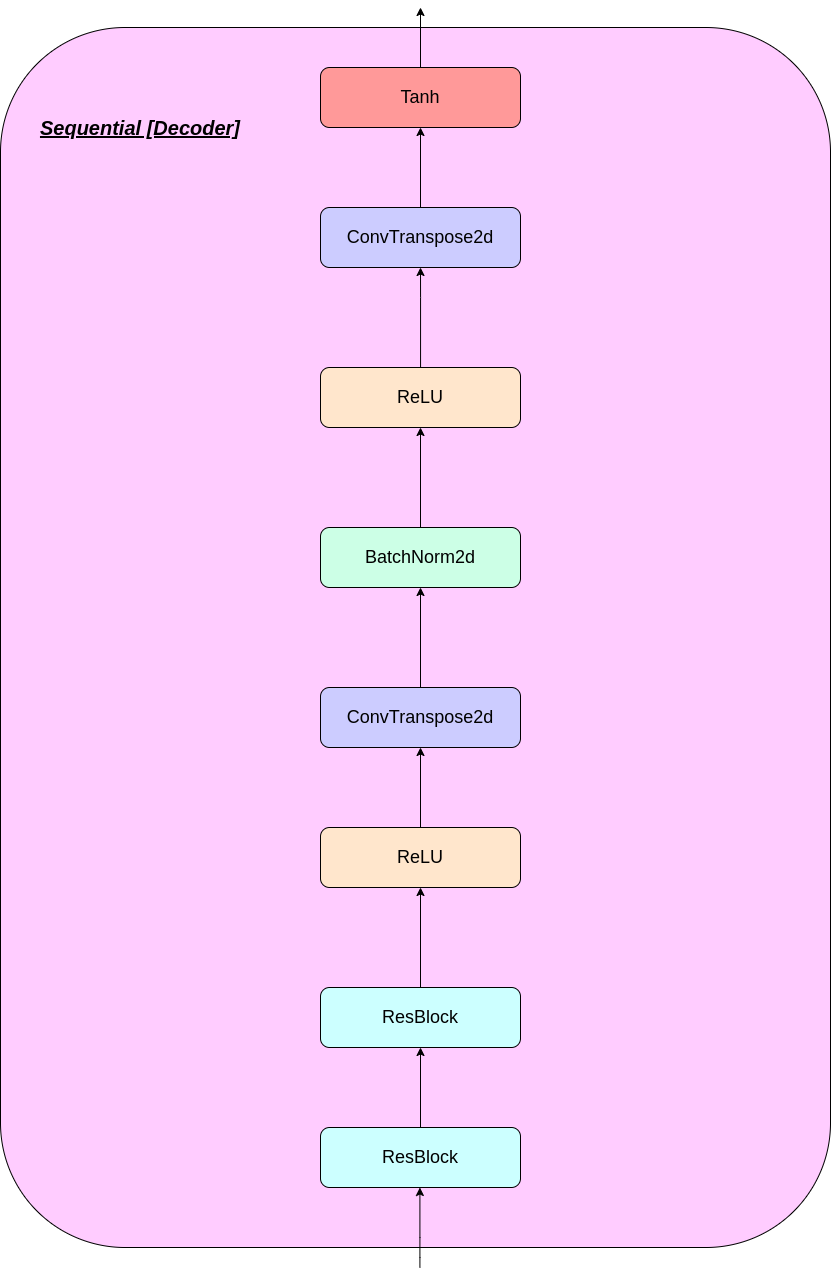
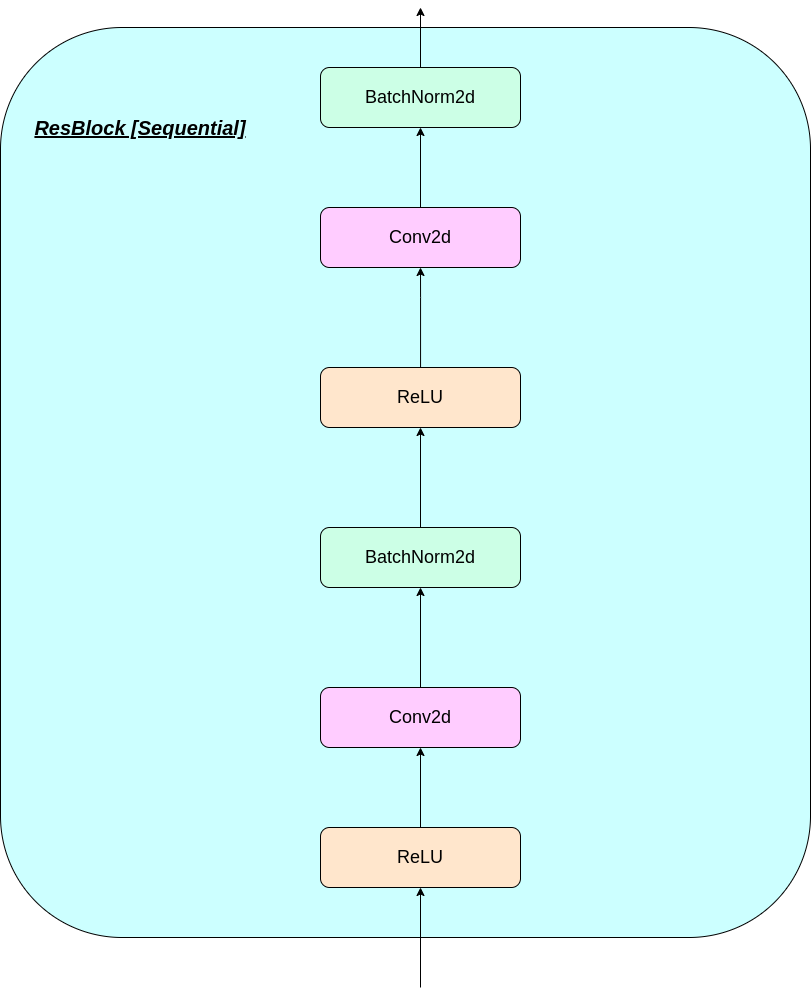
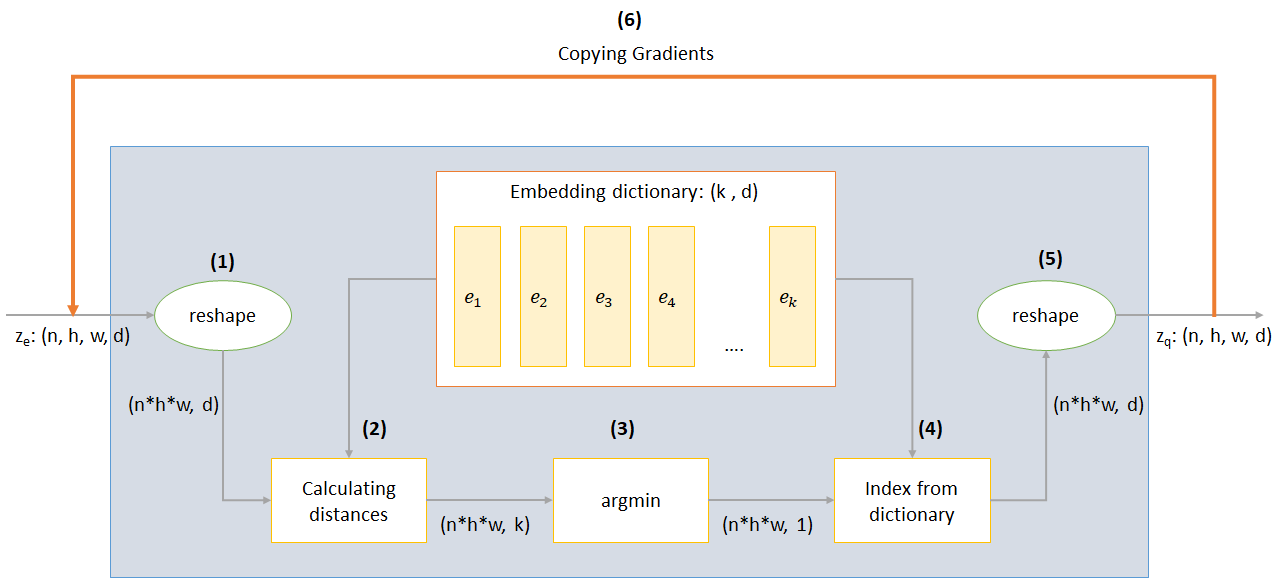
Работа слоя VQ может быть объяснена в шести этапах, пронумерованных на рисунке:
VQ-VAE использует 3 убытки для вычисления общей потери во время обучения:
Потеря реконструкции: оптимизирует декодер и энкодер как vae, то есть разница между входным изображением и реконструкцией:
reconstruction_loss = -log( p(x|z_q) )
Потеря кодовой книги: из -за того, что градиенты обходят внедрение, словарный алгоритм обучения, который использует ошибку L2 для перемещения векторов встраивания E_I в направлении выхода кодера.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG представляет оператор Stop Gradient, что означает, что градиент течет через все, на что он применяется)
Потеря обязательств: Поскольку объем пространства встраивания безразмер, он может произвольно расти, если встраивание E_I не тренируется так быстро, как параметры кодера, и, таким образом, добавлена потеря обязательств, чтобы убедиться, что энкодер собирается внедрить.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β - это гиперпараметр, который контролирует, сколько мы хотим взвесить потерю приверженности по сравнению с другими компонентами)
Вы можете загрузить репо или клонировать его, запустив следующее в CMD -подсказке
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
Вы можете обучить модель с нуля по следующей команде (в Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - Имя папки данныхdata-folder - имя папки данныхdevice - Установите устройство (ЦП или CUDA, по умолчанию: ЦП)hidden-size - размер скрытых векторов (по умолчанию: 40)k - количество скрытых векторов (по умолчанию: 512)batch-size - размер партии (по умолчанию: 128)num-epochs - количество эпох (по умолчанию: 10)lr - скорость обучения для Adam Optimizer (по умолчанию: 2E -4)beta - вклад потери приверженности, между 0,1 и 2,0 (по умолчанию: 1,0)num-workers - количество рабочих для отбора проб траекторий (по умолчанию: CPU_COUNT () - 1) Программа автоматически загружает набор данных MNIST и сохраняет его в папке PATH_TO_MNIST_dataset (вам нужно создать эту папку). Это происходит только один раз.
Он также создает папку и models logs , а внутри них создает папку с именем, передаваемым вам, чтобы сохранить журналы и модели контрольных точек внутри нее соответственно.
Для генерации новых изображений из z, выбранных случайным образом из единичного гауссона, запустите следующую команду (в Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - имя файла, содержащее модельinput - Mnist или случайныйdevice - Установите устройство (ЦП или CUDA, по умолчанию: ЦП)hidden-size - размер скрытых векторов (по умолчанию: 40)k - количество скрытых векторов (по умолчанию: 512)filename - Имя, с каким файлом должен быть сохранен Он генерирует 10*10 сетку изображений, которые сохраняются в папке с именем generatedImages .
Вы можете использовать предварительно обученную модель, загрузив ее по ссылке в model.txt .
Репозиторий содержит следующие файлы
modules.py - содержит различные модули, используемые для создания нашей моделиVQ-VAE.py -содержит функции и код для обучения нашей модели VQ-VAEvector_quantizer.py - классы квантования векторов определены в этом файлеgenerate-py -генерирует новые изображения из предварительно обученной моделиmodel.txt - содержит ссылку на предварительно обученную модельREADME.md - readme, давая обзор репоreferences.txt - Ссылки, используемые при создании этого репо.readme_images - имеет различные изображения для readmeMNIST - содержит набор данных MNIST ZIPD (хотя он будет загружен автоматически, если это необходимо)Training track for VQ-VAE.txt -содержит значения потерь во время обучения нашей модели VQ-VAElogs_VQ-VAE -содержит журналы Zippd Tensorboard для нашей модели VQ-VAE (автоматически созданная программой)testers.py - содержит некоторые функции для проверки наших определенных модулейКоманда запуска Tensorboard (в Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Учебное изображение
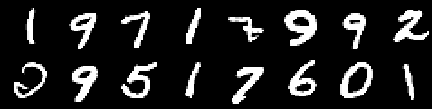
Изображение от 0 -й эпохи

Изображение с 2 -й эпохи
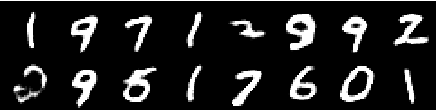
Изображение из 4 -й эпохи
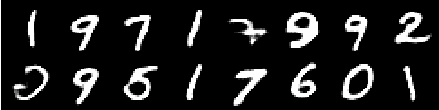
Изображение с 6 -й эпохи
Изображение из 8 -й эпохи
Изображение с 10 -й эпохи
Реконструкции продолжают улучшаться, и в конце почти напоминает изображения training_set, которые отражаются в значениях потерь (проверьте Training track for VQ-VAE.txt ).
Потеря реконструкции
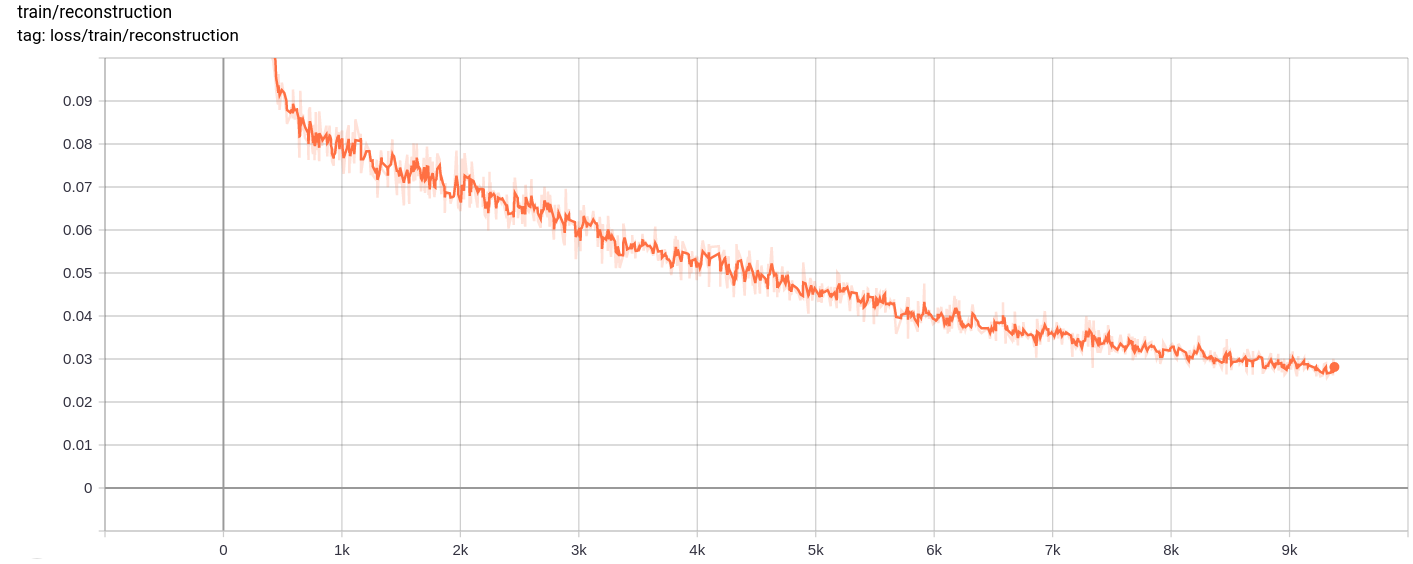
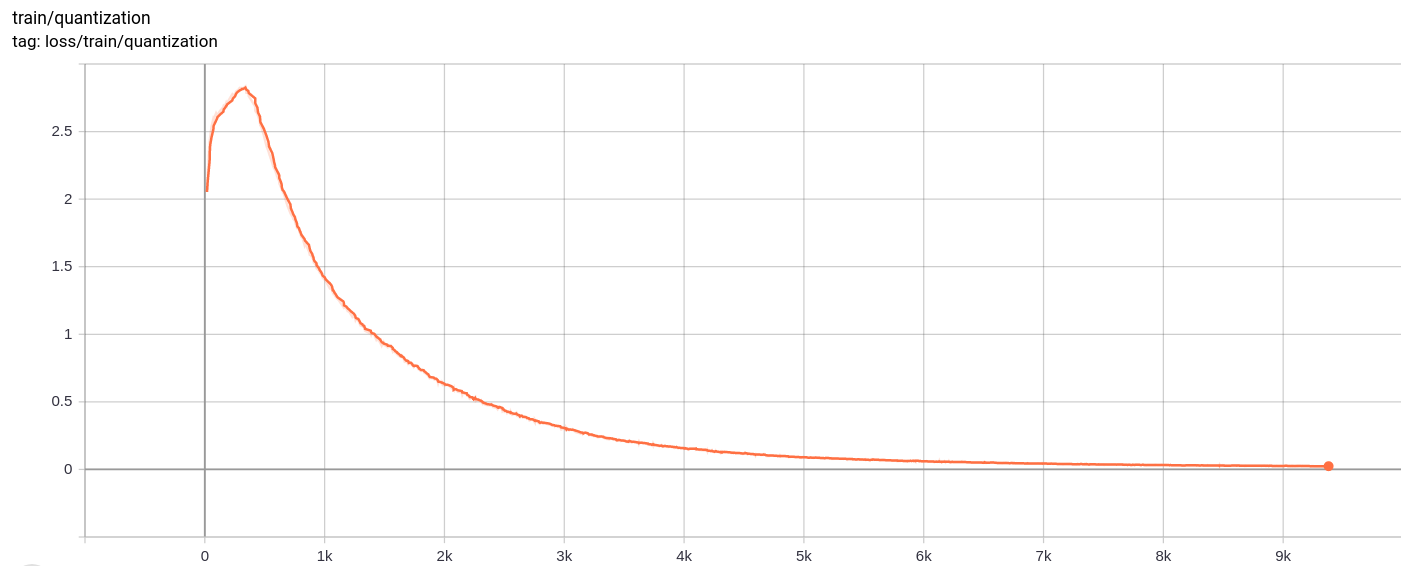
Потеря квантования
Total_loss
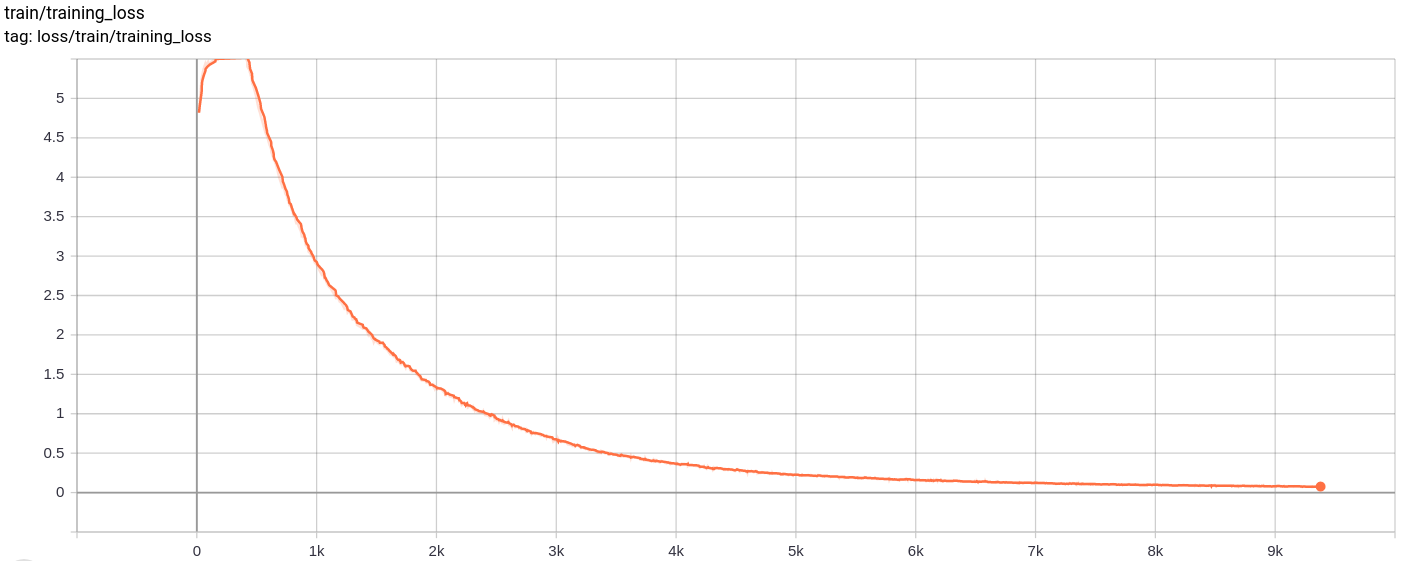
Общая потеря, потери реконструкции и потери квантования уменьшаются, как и ожидалось.
Testing_loss
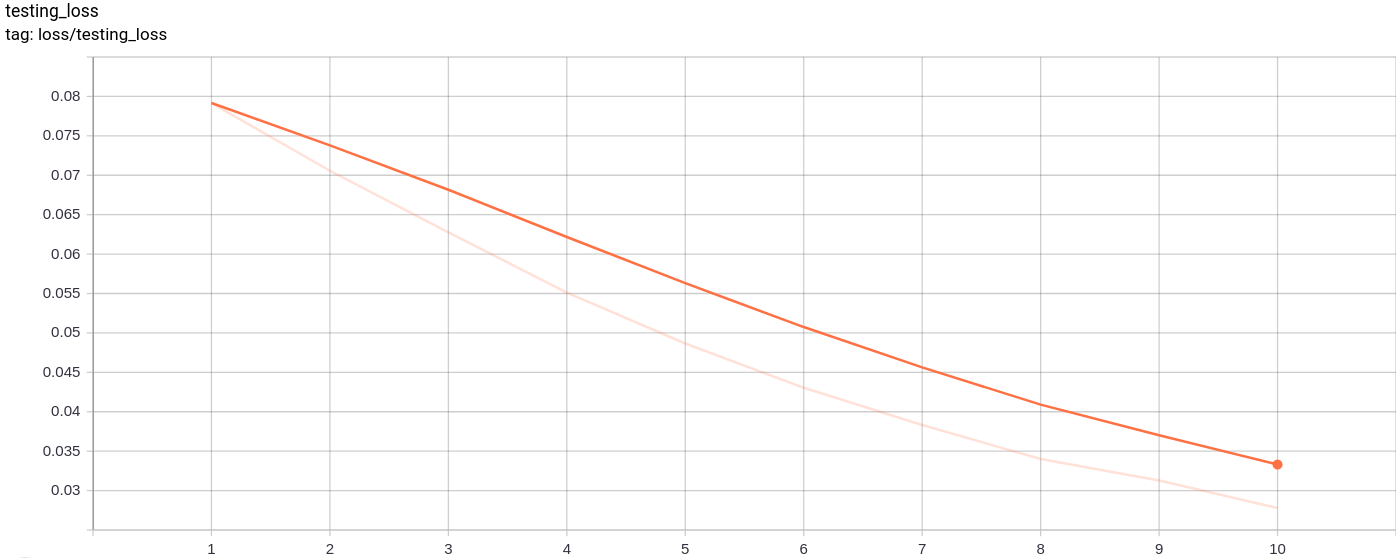
Потеря тестирования уменьшается равномерно, как и ожидалось.
Следующая сетка изображения была сгенерирована после прохождения изображений MNIST в качестве входов:

Поколение довольно хорошо.
Следующие сетки изображения были сгенерированы после прохождения AZ, выбранного случайным образом из единичного гауссового в качестве входного сигнала для модели, а затем проходили через декодер


Изображения не выглядят идеально. Настройка размеров скрытого пространства, количество векторов встраивания и т. Д. Может помочь в создании лучших случайных изображений.
Модель была обучена Google Colab для 10 эпох, с размером партии 128.
После обучения модель смогла довольно хорошо восстановить входные изображения, а также смогла генерировать новые изображения, хотя сгенерированные изображения не так хороши.
Обучение, а также потеря тестирования также продолжали уменьшаться почти монотонно.
Я заметил, что обучение модели для более чем 10-20 эпох дает результаты, которые предположили вероятный признак переживания в модели. Кроме того, я экспериментировал с различными измерениями пространства Latednt и в конечном итоге dimension = 40 дал наилучшие результаты. Лучший диапазон для измерения стал между 16-42.
Следующие источники очень помогли сделать это хранилище


