flash attention
v2.7.0
Этот репозиторий обеспечивает официальную реализацию Flashattention и Flashattention-2 из следующих документов.
Флэндика: быстрое и эффективное память точное внимание с i-avingense
Три Дао, Даниэль Ю. Фу, Стефано Эрмон, Атри Рудра, Кристофер Рене
Бумага: https://arxiv.org/abs/2205.14135
Статья IEEE Spectrum о нашем представлении на эталон MLPERF 2.0 с использованием Flashatturetion. 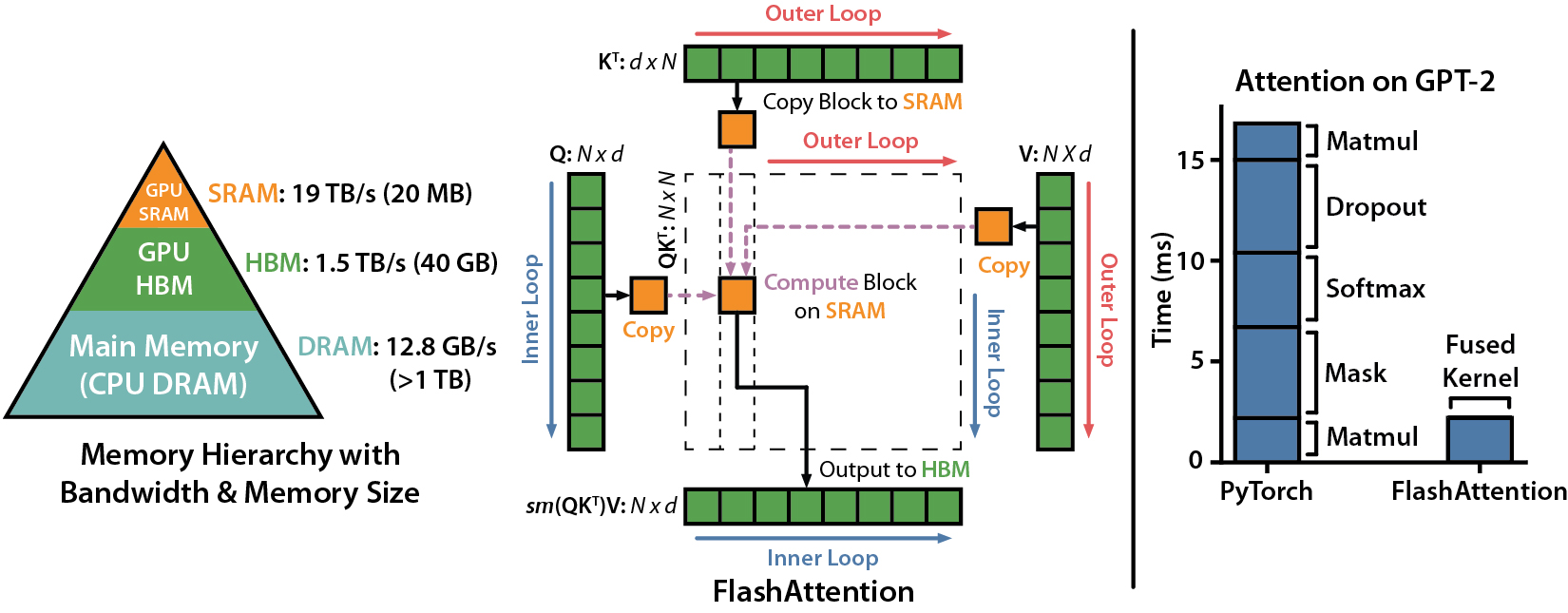
Flashattention-2: более быстрое внимание с лучшим параллелизмом и рабочим разделом
Три Дао
Бумага: https://tridao.me/publications/flash2/flash2.pdf

Мы были очень рады видеть, как Flashattunation широко принят за такое короткое время после его выпуска. Эта страница содержит частичный список мест, где используется вспышка.
Flashattunition и Flashattion-2 бесплатны и изменять (см. Лицензию). Пожалуйста, цитируйте и кредитуйте вспышку, если вы его используете.
Flashattention-3 оптимизирован для графических процессоров Hopper (например, H100).
Blogpost: https://tridao.me/blog/2024/flash3/
Бумага: https://tridao.me/publications/flash3/flash3.pdf
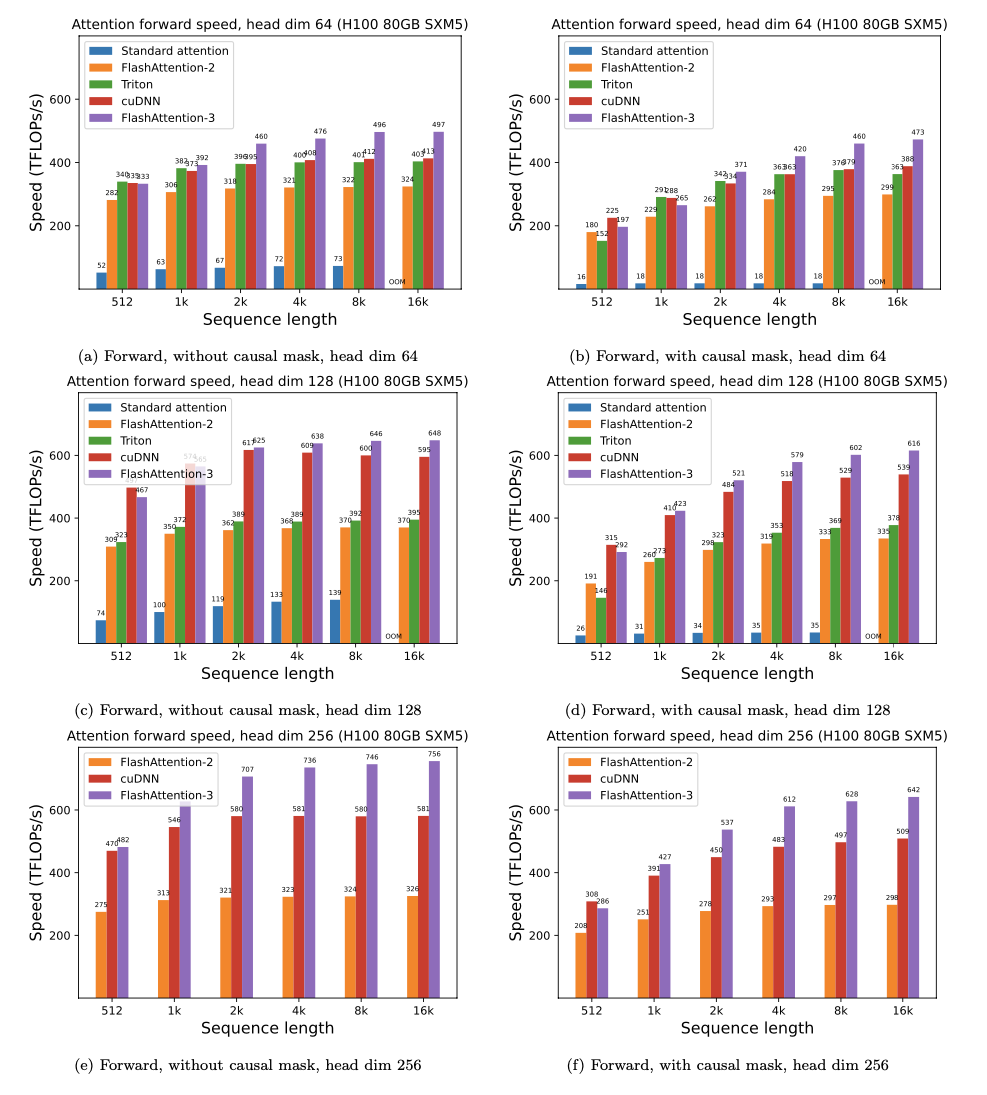
Это бета -версия для тестирования / сравнительного анализа, прежде чем мы интегрируем это с остальной частью репо.
В настоящее время выпущено:
Требования: H100 / H800 GPU, CUDA> = 12,3.
На данный момент мы настоятельно рекомендуем CUDA 12.3 для лучшей производительности.
Для установки:
cd hopper
python setup.py installЧтобы запустить тест:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyТребования:
packaging Python Package ( pip install packaging )ninja Python ( pip install ninja ) * * Убедитесь, что ninja установлен и что она работает правильно (например, ninja --version echo $? Должен ли код выхода 0). Если нет (иногда ninja --version , то echo $? Возвращает ненулевой выход кода), удалите, затем переустановите ninja ( pip uninstall -y ninja && pip install ninja ). Без ninja компилирование может занять очень много времени (2 часа), поскольку он не использует несколько сердечников ЦП. С компиляцией ninja занимает 3-5 минут на 64-ядерной машине, используя Cuda Toolkit.
Для установки:
pip install flash-attn --no-build-isolationВ качестве альтернативы вы можете скомпилировать из источника:
python setup.py install Если на вашей машине меньше 96 ГБ оперативной памяти и много ядер процессоров, ninja может выполнять слишком много рабочих мест для компиляции, которые могут исчерпать количество оперативной памяти. Чтобы ограничить количество вакансий параллельных компиляций, вы можете установить переменную среды MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation Интерфейс: src/flash_attention_interface.py
Требования:
Мы рекомендуем контейнер Pytorch от NVIDIA, который имеет все необходимые инструменты для установки вспышки.
Flashattention-2 с CUDA в настоящее время поддерживает:
Версия ROCM использует Composable_kernel в качестве бэкэнда. Он обеспечивает реализацию Flashattention-2.
Требования:
Мы рекомендуем контейнер Pytorch от ROCM, который имеет все необходимые инструменты для установки вспышки.
Flashattention-2 с ROCM в настоящее время поддерживает:
Основные функции реализуют масштабированное точечное продукт (SoftMax (Q @ K^T * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""Чтобы увидеть, как эти функции используются в многопользовательском уровне внимания (который включает в себя проекцию QKV, выходную проекцию), см. Реализацию MHA.
Обновление от Flashatturetion (1.x) до Flashattention-2
Эти функции были переименованы:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcЕсли входные данные имеют одинаковую длину последовательности в одной и той же партии, это проще и быстрее использовать эти функции:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )Если seqlen_q! = Seqlen_k и casesal = true, причинно-следственная машина выровнена в правый нижний угол матрицы внимания, вместо верхнего левого угла.
Например, если seqlen_q = 2 и seqlen_k = 5, причинно -следственная машина (1 = Keep, 0 = Masked Out) - это:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
Если seqlen_q = 5 и seqlen_k = 2, причинно -следственная машина:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
Если строка маски все ноль, вывод будет нулевой.
Оптимизировать для вывода (итеративное декодирование), когда запрос имеет очень небольшую длину последовательности (например, длина последовательности запросов = 1). Узкое место здесь состоит в том, чтобы загрузить кэш KV как можно быстрее, и мы разделим загрузку на разные блоки резьбы с отдельным ядром, чтобы объединить результаты.
См. Функцию flash_attn_with_kvcache с большими функциями для вывода (выполните вращающийся встраивание, обновление KV -кэша в месте).
Благодаря команде Xformers и, в частности, Дэниел Хазиза за это сотрудничество.
Реализуйте внимание скользящего окна (т.е. локальное внимание). Спасибо Mistral AI и, в частности, Timothee Lacroix за этот вклад. Раздвижное окно использовалось в модели Mistral 7B.
Реализовать алиби (Press et al., 2021). Спасибо Сангуну Чо из Какао Брейна за этот вклад.
Реализуйте детерминированный обратный проход. Спасибо инженерам из Meituan за этот вклад.
Поддержка Pagge KV Cache (т.е. Pageganatatureation). Спасибо @beginlner за этот вклад.
Поддержите внимание с помощью Softcapping, как используется в моделях GEMMA-2 и GROK. Спасибо @narsil и @lucidrains за этот вклад.
Спасибо @ani300 за этот вклад.
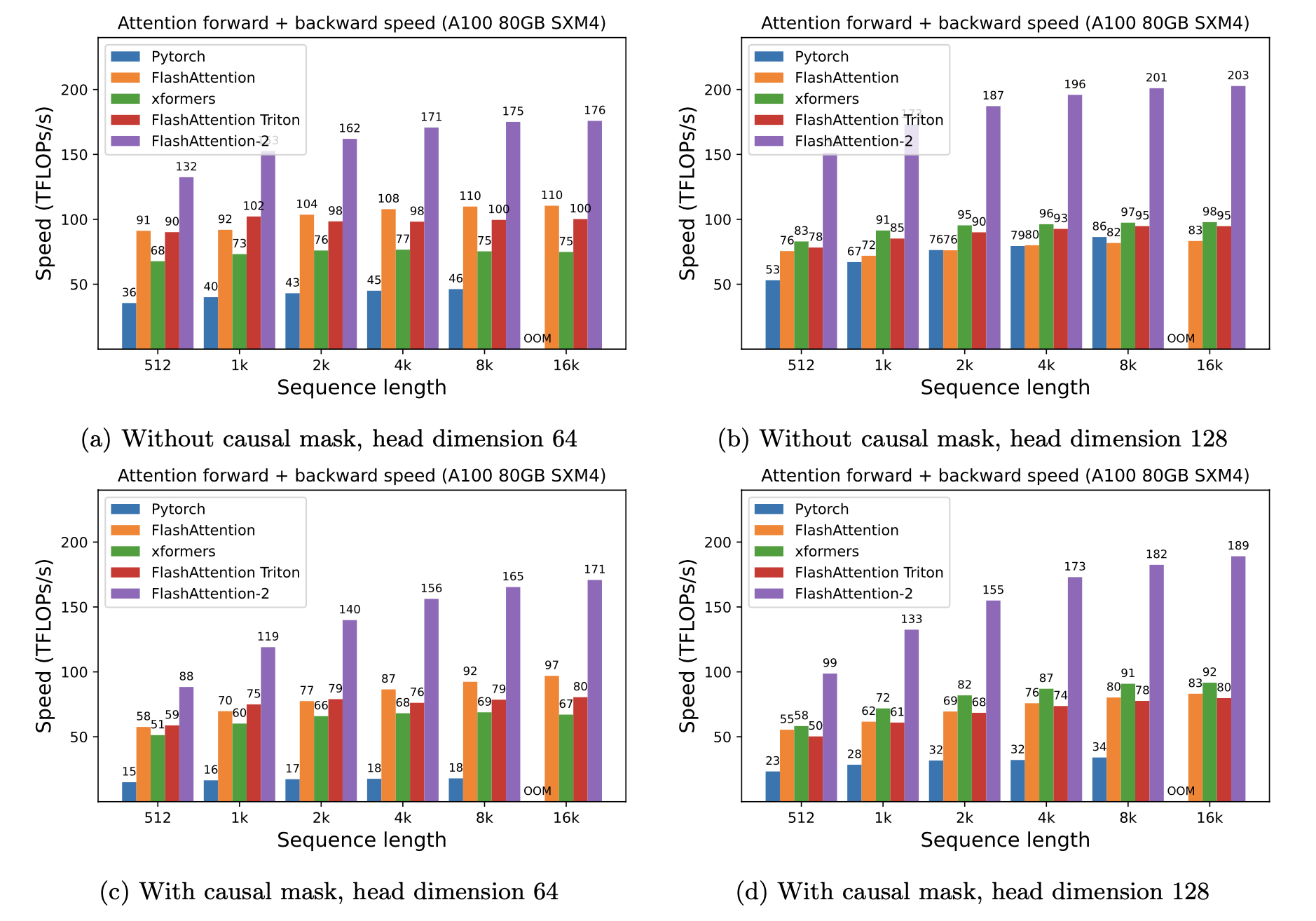
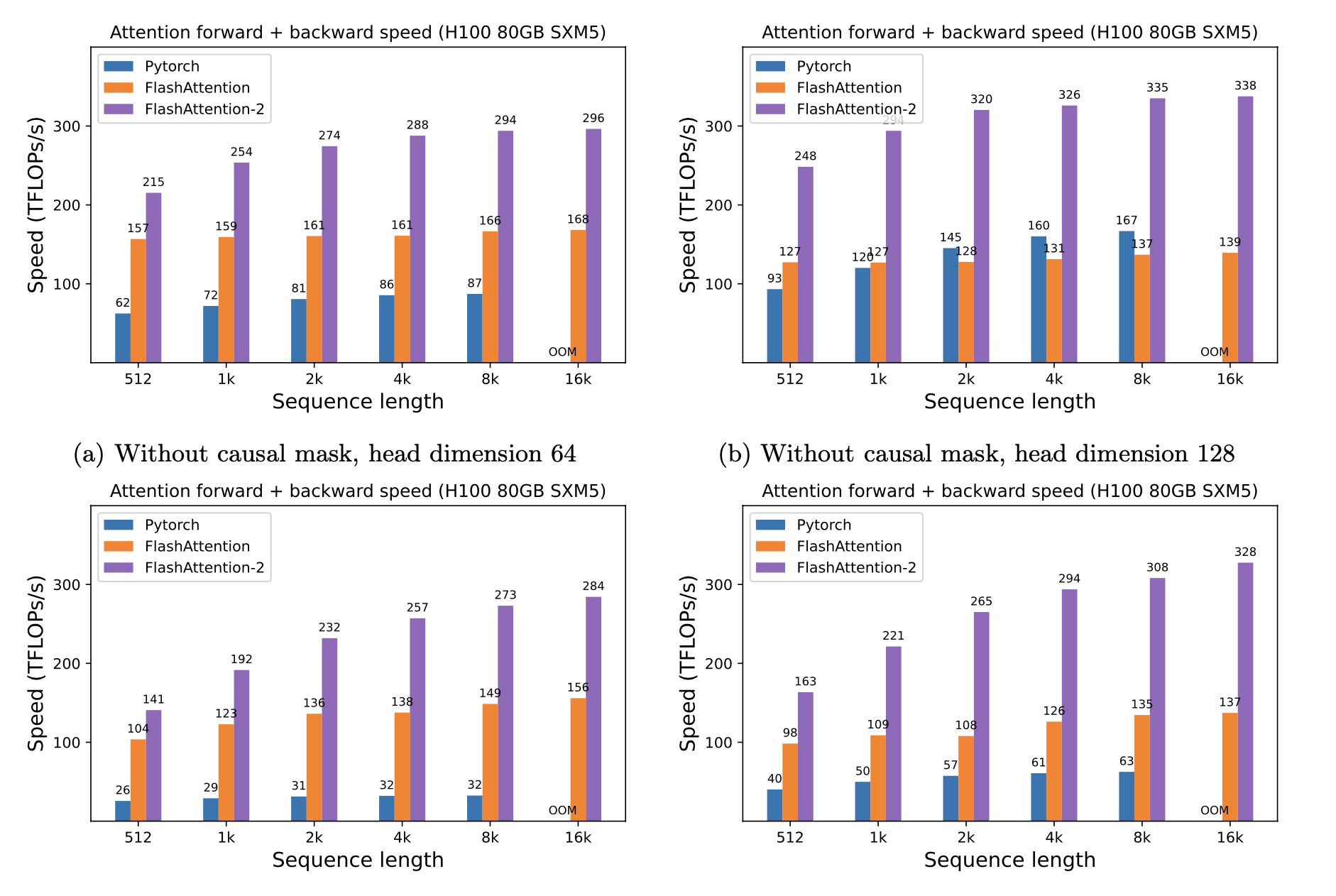
Мы представляем ожидаемое ускорение (комбинированный вперед + обратный проход) и экономию памяти от использования вспышки против стандартного внимания Pytorch, в зависимости от длины последовательности, на разных графических процессорах (ускорение зависит от полосы пропускания памяти - мы видим больше ускорения на более медленной памяти графических процессоров).
В настоящее время у нас есть тесты для этих графических процессоров:
Мы отображаем ускорение вспышки, используя эти параметры:
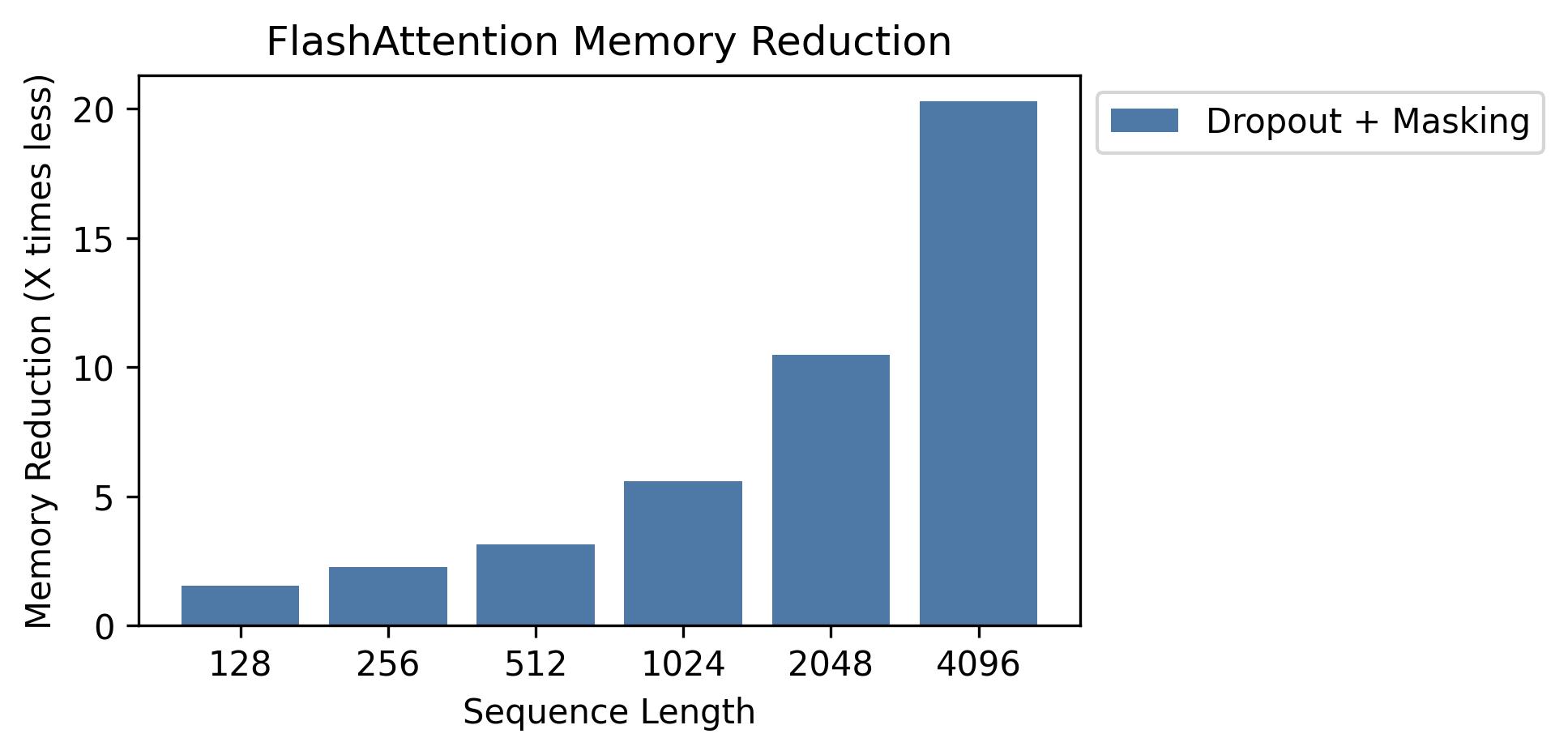
Мы показываем сохранение памяти на этом графике (обратите внимание, что следование памяти одинаково независимо от того, используете ли вы отсечение или маскировку). Экономия памяти пропорциональна длине последовательности - поскольку стандартное внимание имеет квадратичную память по длине последовательности, тогда как у вспышки есть линейная память по длине последовательности. Мы видим 10 -кратные экономии памяти в длине последовательности 2K и 20x при 4K. В результате вспышка может масштабироваться до гораздо более длинной длины последовательности.
Мы выпустили полную реализацию модели GPT. Мы также предоставляем оптимизированные реализации других слоев (например, MLP, Layerorm, потери поперечной энтропии, вращательное встраивание). В целом, это ускоряет тренировку в 3-5x по сравнению с базовой реализацией от HuggingFace, достигая до 225 TFLOPS/SEC на A100, эквивалентно 72% модельным флопам (нам не нужна какая-либо контрольная точка активации).
Мы также включаем учебный сценарий для обучения GPT2 на OpenWebText и GPT3 на куче.
Фил Тиллет (OpenAI) имеет экспериментальную реализацию вспышки в Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fuss-attence.py
Поскольку Тритон является языком более высокого уровня, чем CUDA, это может быть легче понять и экспериментировать. Установки в реализации Triton также ближе к тому, что используется в нашей статье.
У нас также есть экспериментальная реализация в Triton, которая поддерживает смещение внимания (например, alibi): https://github.com/da-ailab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
Мы проверяем, что вспышка производит тот же выход и градиент, что и эталонная реализация, вплоть до численной толерантности. В частности, мы проверяем, что максимальная численная ошибка вспышки не более вдвое больше численной ошибки базовой реализации в Pytorch (для разных размеров головки, входной Dtype, длины последовательности, причинно-следственной / не-овсяной).
Чтобы запустить тесты:
pytest -q -s tests/test_flash_attn.pyЭтот новый выпуск Flashattention-2 был протестирован на нескольких моделях в стиле GPT, в основном на графических процессорах A100.
Если вы сталкиваетесь с ошибками, пожалуйста, откройте проблему GitHub!
Чтобы запустить тесты:
pytest tests/test_flash_attn_ck.pyЕсли вы используете эту кодовую базу или иным образом нашли нашу работу ценной, пожалуйста, цитируйте:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


